1. REST의 이해와 설계
REST(REpresentational State Transfer)는 현재 대부분의 OPEN API의 기반이 되고 있다.
기본 개념
REST는 크게 리소스, 메서드, 메시지의 요소로 구성된다.
-
HTTP 메서드
REST에서 사용하는 메서드는 CRUD에 해당하는 4가지(POST, GET, PUT, DELETE)만 사용한다. -
REST의 리소스
모든 것을 리소스로 표현하므로 명사의 형태여야 하고, 세부 리소스에는 ID를 붙인다. -
특성
-
유니폼 인터페이스
HTTP 표준만 따르면 어떤 기술에서든 사용할 수 있다. 플랫폼이나 언어에 종속되지 않는 느슨한 결합 형태의 인터페이스 스타일이다. -
Stateless
REST는 상태를 어디에도(클라이언트/서버) 저장하지 않기 때문에 서버는 컨텍스트 정보를 알 필요 없이 들어오는 요청만 처리하면 되므로 구현이 단순해진다. -
캐시 가능
캐싱 기능을 적용할 수 있어, 응답 시간과 성능면에서 유리하다. -
자체 표현 구조
리소스와 메서드만 보면 무슨 행위를 하는지 직관적으로 알 수 있는 구조이다. -
클라이언트-서버 구조
REST의 클라이언트 서버 구조를 적용하게 되면서 각각의 역할이 명확히 구분되게 되었고, 이로 인해 클라이언트와 서버의 개발에서 상호 의존성이 줄어들었다. -
계층형 구조
클라이언트는 REST API 서버만 호출하지만, 서버는 API 서버뿐만 아니라 그 앞에 추가적인 계층을 두어 유연하게 구성될 수 있다.
-
-
안티 패턴
-
GET/POST를 이용한 터널링
메서드와 실제로 하는 동작의 내용이 다른 경우다. GET 메소드에서http://myweb/users?method=update&id=terry처럼 업데이트 메서드를 명시하거나,
HTTP POST, http://myweb/users/
{ "getuser":{"id":"terry"} }
처럼 POST 메소드임에도 body의 내용은 정보를 가져오는 식으로 사용하는 것은 REST하지 않는 방법이다. -
HTTP 응답 코드를 사용하지 않음
응답 코드를 성공일 때 200, 실패일 때 500만 사용하면 REST의 디자인 사상과도 맞지 않는다.
-
REST API 디자인 가이드
-
단순, 직관적인 REST URI
최대 2단계 정도로만 내려가는 것이 이해하기 편하다.
리소스는 명사로 표현하고, 메서드에서 동사를 표현한다. -
리소스간의 관계
리소스간에 소유 관계가 있다면 주로 서브 리소스로/users/{userId}/devices처럼 표현하고, 관계명이 복잡해 구체적으로 표현해야 한다면/users/{userId}/likes/devices처럼 나타낼 수 있다. -
에러 처리
에러 처리의 기본은 HTTP 응답 코드를 사용한 후 response body에 에러에 대한 내용을 기술하는 것이다.
HTTP 응답 코드의 경우 많을수록 명시적이지만, 현실적인 코드 관리 문제로 인해 핵심적인 몇 가지만 사용한다.
200 성공
400 Bad Request
401 Unauthorized
404 Not Found
500 Internal Server Error그리고 response body에는 에러 내용을 구체적으로 기술한다.
-
API 버전 관리
API의 버전을 관리함으로써 서비스가 확장되었을 때 필요에 따라 특정 서버만 분리해서 배포할 수 있게 된다. -
페이징
응답이 큰 사이즈라면 페이징 처리를 통해 부하를 줄일 수 있다.
페이징 디자인은 여러가지가 있지만 자주 보이는 패턴은 offset, limit을 사용한 스타일이다. -
부분 응답 처리
응답 메시지에는 모든 필드가 항상 필요한 것은 아니다.
이 경우에는 필드를 제한함으로써 네트워크 대역폭을 절약하고 파싱을 간략화할 수 있다.
회사마다 처리 방법은 다르지만, 저자가 권장하는 방법은 페이스북 스타일로/terry/friends?fields=id, name과 같은 형식이다. -
검색
검색의 경우 GET 메소드에서 쿼리 스트링을 통해 조건을 정의하는 경우가 많다.
이 때 검색 조건이 다른 쿼리 스트링(offset, limit 등)과 섞여 헷갈릴 수 있다.
따라서 검색 조건은 별도로 URLEncode로 인코딩하면 다른 쿼리 스트링과 분리할 수 있다.
검색 범위의 경우, 전역 검색일 경우/search와 같은 전역 검색 URI를 활용하고, 리소스 안에서는 리소스명에 쿼리 스트링을 붙이는 식으로 해결할 수 있다. -
HATEOS를 이용한 링크 처리
HATEOS는 Hypermedia as the Engine of Application State의 약어로 HTTP 응답에 다음 액션이나 관계된 리소스에 대한 HTTP 링크를 함께 반환하는 것이다.
HATEOS를 통해 API에 대한 가독성을 높일 수 있다. -
단일 API 엔드포인트 활용
API 서버가 물리적으로 분리된 여러 서버에서 돌아가더라도, Reverse Proxy를 통해 단일 URL로 라우팅시킬 수 있다.
REST의 문제점
-
JSON + HTTP를 쓰면 REST?
JSON + HTTP만 쓴다고 해서 REST가 되는 것은 아니다.
리소스를 제대로 정의하고 이에 대한 메서드를 올바르게 사용하며, 에러 코드도 올바른 HTTP 응답 코드를 사용해야 제대로 된 REST이다. -
표준 규약이 없다
REST는 정확한 표준이 없고 암암리에 많이 쓰는 것들을 모은 de facto standard 정도만 있는 상황이다.
그래서 개발에서 REST를 관리하기 어렵고, 자체 표준을 정해야 하기 때문에 오히려 REST 하지 않은 아키텍처가 나올 수도 있다.
따라서 이런 문제점은 REST API 표준 가이드와 API 문서를 만들어 리뷰하는 프로세스를 갖추어 해결하고자 노력해야 한다.
REST API 보안
-
인증
여러 인증 방식이 있으므로 각 방식의 장단점을 파악하고 서비스 수준에 맞는 인증 방식을 선택해야 한다.- API KEY 방식
가장 기초적인 방법으로, 특정 사용자만 알 수 있는 문자열을 제공한다. 하지만 이 키가 노출되면 전체 API가 뚫리기 때문에 높은 보안인증이 필요할 경우에는 사용하면 안된다. - API 토큰 방식
사용자가 ID, 비밀번호로 인증하면 API 호출에 필요한 API 토큰을 발급 한다.
설령 토큰이 탈취당하더라도 API만 호출할 수 있을 뿐 계정의 ID, 비밀번호는 알 수 없으므로 연쇄적인 피해를 막을 수 있다.
API 토큰 방식에는 다양한 유형이 있어, 보안 수준에 따라 선택해서 사용할 수 있다.
유형의 예로는 HTTP Basic Auth, Digest Access Authentication, 클라이언트 인증, 제3자 인증, IP화이트리스트, Bi-directional Certification 등이 있다.
- JWT 방식
현재 많이 사용되는 방식인 JWT 방식은 Claim기반의 토큰 방식이다.
Claim은 사용자의 속성을 뜻하며, 토큰에 이 내용이 들어 있으므로 별도로 사용자 정보를 호출할 필요가 없다.
JWT는 변조 방지를 위해 다양한 알고리즘을 사용하여 복호화한 서명을 토큰 뒤에 붙인다.
이렇듯 JWT 방식은 사용이 간단하지만 claim의 길이가 길어질수록 네트워크 부담이 커지고, 한번 토큰이 발급되면 수정, 폐기가 불가능하며 claim 정보는 암호화되지 않기 때문에 들어갈 정보를 잘 선별해야 한다는 문제점도 존재한다.
- API KEY 방식
-
인가
존재하는 사용자인지 인증이 되었다면 API 호출 권한이 있는 사용자인지 확인하는 과정이 필요하다.- 인가 방식
권한 인증 방식은 여러가지가 있지만, 가장 일반적인 방식은 RBAC(Role Based Access Control) 방식으로, 역할에 따라 권한을 갖게 되는 방식이다.
한편 ACL(Access Control List) 방식은 역할 없이 사용자에게 직접 권한을 부여하는 방식이다. - 인가 처리 위치
인가 처리는 여러 계층에서 가능하지만 일반적으로 서버에서 처리하게 된다.
API Gateway에서 인가에 필요한 필드를 변환해서 서버로 전달하면 구현을 간략하게 할 수 있다. - 네트워크 레벨 암호화
네트워크 레벨에서 가장 기본적인 보안 방법은 HTTPS 프로토콜을 사용하는 것이다.
이것만으로도 메시지를 암호화해 전송하기 때문에 대부분의 메시지 누출은 막을 수 있다.
하지만 중간자 공격을 통해 해커가 메시지를 가로챌 수도 있는데, 이를 막기 위해서는 공인 인증서를 사용했는지를 점검해야 한다. - 메시지 본문 암호화
메시지 전체가 아니라 필요한 필드만 애플리케이션 단에서 암호화할 수도 있다.
그 경우 클라이언트와 서버가 암호화 키를 가지고 있어야 한다.
암호화 키에는 대칭 키와 비대칭 키가 있는데, 이에 대해서는 예전 포스트에서 간단히 설명해 놓았다. - 메시지 무결성 보장
메시지가 변조되지 않았는지를 판단하기 위한 방법으로는 HMAC을 이용한 방법이 널리 사용되고 있다.
클라이언트와 서버가 대칭키를 기반으로 한 암호화 키를 가지고, 호출 시 HMAC 알고리즘으로 키를 이용해 해시 값을 추출하여 메시지에 포함시킨다.
만약 메시지가 변조될 경우 해시값이 달라지기 때문에 이를 통해 변조된 것을 알 수 있다.
- 인가 방식
-
자바스크립트 클라이언트 지원
자바스크립트 기술이 발전하면서 SPA(Single Page Application)가 유행하고 있는데,
기존과 다르게 자바스크립트가 API 호출을 바로 하는 형태이다.
브라우저에서 자바스크립트 코드를 볼 수 있고 수정도 가능하다는 특성상, API의 보안 측면에서도 새로운 요구사항이 제기되었다.- 동일 출처 정책
자바스크립트의 API 호출은 동일 출처 정책에 의해 제한된다.
이는 웹 브라우저에서 동작하는 프로그램은 해당 프로그램이 로딩된 위치에 있는 리소스에만 접근할 수 있다는 뜻이다.
따라서 설정 없이sitea.com에서 자바스크립트를 로딩하고, 여기서api.my.com에 있는 API를 호출하려고 하면 에러가 발생한다.
이를 해결하기 위한 방법은 여러가지가 있지만 가장 일반적으로 사용되는 것은 CORS(Cross Origin Resource Sharing)이다. - 특정 사이트에 대한 접근 허용
CORS 방식 중 가장 간단한 것으로, API 서버의 설정에서 응답 헤더에 Request Origin을 명시해 줌으로써 접근을 허용하는 방식이다.
Access-Control-Allow-Origin: sitea.com처럼 특정 사이트에서만 요청을 처리하도록 할 수도 있고,Access-Control-Allow-Origin: *로 Request Origin에 관계 없이 요청을 처리하도록 할 수도 있다. - Pre-flight을 이용한 세세한 CORS 통제
REST 리소스(URL)당 세세한 CORS 통제가 필요하다면 Pre-flight 호출을 사용할 수 있다.
브라우저에서 URL에 요청을 보내기 전에 HTTP OPTIONS를 호출하고, 서버에서는 이에 대해 접근할 수 있는 Origin URL과 HTTP 메서드를 반환한다. - API Access Token에 대한 인증처리
자바스크립트 클라이언트는 서버와 달리 API Access Token을 안전하게 저장할 방법이 없으므로 추가적인 처리가 필요하다.
한 가지 방법으로는 보안 쿠키를 사용하는 것인데, 보안 쿠키는 항상 HTTPS를 통해서만 전송해야 하므로 네트워크를 통해 토큰을 탈취하지 못한다. 또한 HttpOnly 옵션을 쿠키에 추가해서 자바스크립트가 쿠키에 접근하지 못하도록 할 수 있다.
다른 방법으로는 토큰의 만료 시간을 정해놓고 그 시간 내에서만 유효하도록 하는 방법이다.
- 동일 출처 정책
2. 대용량 실시간 데이터 처리를 위한 람다 아키텍처
람다 아키텍처란?
람다 아키텍처는 실시간 분석을 지원하는 빅데이터 아키텍처다.
다음의 예제를 통해 람다 아키텍처의 흐름을 파악해보자.
-
문제 정의
사용자가 1억명인 애플리케이션에서 매일 각 사용자의 행동 패턴을 서버에 저장하여 일별로 사용자 이벤트의 개수를 통계로 추출한다.
이 때 통계 정보를 실시간으로 확인하고자 할 때, 가장 단순한 방법으로는 RDBMS에서 쿼리를 통해 가져오는 것이다.
하지만 사용자가 1억명이므로 매일 1억개의 레코드가, 한달이면 30억개가 생긴다. 가져올 때 엄청난 시간이 걸릴 것이라 짐작이 가능하다. -
배치 활용
이를 해결하는 전통적인 방법은 배치를 활용하는 것이다. 데이터를 모아놓고 밤마다 필요한 데이터를 계산해 별도의 테이블에 작성하면 1년분의 데이터도 365행뿐이므로 속도에도 문제가 없다.- 실시간 데이터 반영
그런데 속도 문제가 해결되더라도 이 배치 테이블은 최대 1일이 차이난다. 결국 실시간이 아니라는 말이므로 이를 해결해야 한다. 이는 어제까지의 데이터가 있는 테이블과 사용자별로 기록된 오늘의 데이터 로그 테이블을 조인함으로써 현재 시점의 통계값을 볼 수 있다.
- 실시간 데이터 반영
-
실시간 집계 테이블의 활용
그런데 오늘 하루에 쌓이는 데이터가 1억건이라는 것을 생각해보면, 조인을 하더라도 1억개의 행에 연산이 발생하므로 성능이 저하될 것이다.
그렇다면 데이터에 대한 통계값을 실시간 업데이트한 테이블과 배치 테이블을 조인하는 방식으로 빠르게 실시간 통계를 볼 수 있다.
람다 아키텍처 활용
이제까지의 흐름을 그림으로 나타내면 다음과 같다.
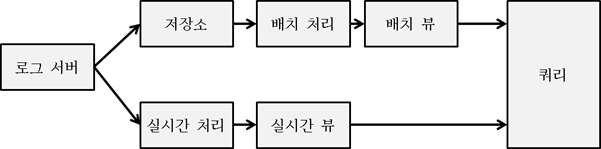
람다 아키텍처의 재구성
-
RDBMS를 활용한 유연성 증대
람다 아키텍처는 대용량 데이터 처리에 유리한 하둡이나 NoSQL을 사용해서 구현하는 경우가 많다.
그렇기 때문에 유연성 측면에서 상호 조인이나 인덱스, 조인 등이 어렵다.
이러한 문제를 해결하기 위해 RDBMS를 실시간 뷰와 배치 뷰 부분에 사용해볼 수 있다. -
데이터 분석 도구를 이용한 새로운 분석 모델 개발
데이터 과학자는 원본 데이터를 재분석함으로써 새로운 데이터 모델을 추출해 낼 수 있다.
이 때 원본 저장소에 데이터 분석 도구를 이용해 샘플 데이터를 추출해 상관관계를 파악하고 분석하여 새로운 모델을 설계하고 검증할 수 있다.
