
본 포스트는 박재호님의 유튜브 강의(링크)를 보고 일부 발췌하여 정리한 내용입니다.
사용된 자료, 샘플 데이터 등은 모두 SQLite Tutorial에서 확인할 수 있습니다.
1. UNION
sql에서도 집합에 대한 연산이 가능하다.
union은 한 테이블에서 쿼리한 결과와 다른 테이블(복수 가능)에서 쿼리한 결과를 합쳐 하나의 테이블처럼 보이게 만들어 주는 기능이다.
다만 union을 사용하기 위한 몇 가지 조건이 존재한다.
- 모든 쿼리의 컬럼의 개수는 같아야 한다.
- 매칭되는 컬럼의 데이터 타입은 호환 가능(compatible)해야 한다.
- result set의 컬럼 이름은 가장 처음 쿼리의 컬럼 이름으로 결정된다.
- GROUP BY와 HAVING절은 각각의 쿼리에만 적용되고, 최종 결과물에 대해서 적용할 수는 없다.
- ORDER BY절은 반대로 최종 결과물에만 적용되고 각각의 쿼리에는 적용할 수 없다.
실제로 어떻게 동작하는지 확인하기 위해 다음과 같이 테이블을 생성한다.
CREATE TABLE t1(
v1 INT
);
INSERT INTO t1(v1)
VALUES(1),(2),(3);
CREATE TABLE t2(
v2 INT
);
INSERT INTO t2(v2)
VALUES(2),(3),(4);생성된 두 테이블에 대해 union을 실행해 보자.
SELECT v1
FROM t1
UNION
SELECT v2
FROM t2;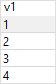
두 테이블이 합쳐진 결과가 나오게 된다.
여기서 union all을 사용하면 중복된 데이터(2,3)이 한 번씩 더 나오게 될 것이다.
다음으로 order by를 사용한 예제를 확인해 보자.
SELECT FirstName, LastName, 'Employee' AS Type
FROM employees
UNION
SELECT FirstName, LastName, 'Customer'
FROM customers
ORDER BY FirstName, LastName;
위에서 설명한 것처럼 order by의 경우 각각의 쿼리문이 아닌 최종 결과물에서 적용되므로, 전체 테이블이 firstname, lastname 순으로 정렬된 것을 볼 수 있다.
2. INTERSECT와 EXCEPT 흉내내기
sqlite에는 intersect와 except가 있지만, 일반적으로 많이 쓰이는 mysql에는 두 기능이 없다.
하지만 필요한 기능이기에, inner join과 left join으로 해결해 보도록 한다.
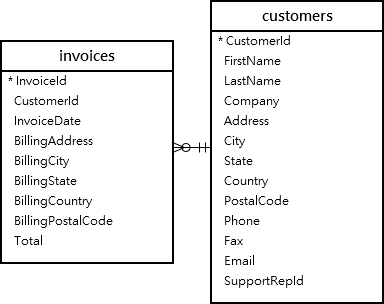
두 테이블에 공통적으로 존재하는 CustomerId를 기준으로 둘의 교집합을 구하는 쿼리문은 다음과 같다.
SELECT DISTINCT c.CustomerId
FROM Customers c
INNER JOIN invoices i
ON c.CustomerId=i.CustomerId
ORDER BY c.CustomerId;여기서 DISTINCT가 없으면 중복되는 데이터도 포함해서 나오게 된다.
except는 한 테이블에만 존재하는 데이터를 뽑아내는데, 이는 left join을 통해 구현할 수 있다.
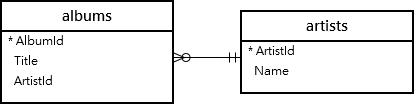
artists에는 있지만 albums에는 없는 artistId를 찾기 위한 쿼리문은 아래와 같다.
SELECT a.ArtistId
FROM artists a
LEFT JOIN albums b
ON a.ArtistId=b.ArtistId
WHERE b.ArtistId IS NULLIS NULL을 통해 albums에는 데이터가 없는 부분만을 가져오도록 했다.
