
본 포스트는 박재호님의 유튜브 강의(링크)를 보고 일부 발췌하여 정리한 내용입니다.
사용된 자료, 샘플 데이터 등은 모두 SQLite Tutorial에서 확인할 수 있습니다.
1. Subquery
서브쿼리는 쿼리문 안에 쿼리문이 들어 있는 구조이다.
서브쿼리에서 다른 테이블에 한 번 질의한 결과를 마치 기존 테이블 있는 데이터처럼 사용할 수 있다.
실제로 join만큼이나 자주 사용하는 쿼리이기도 하다.
다만 subquery가 들어갈 수 있는 곳은 한정되어 있는데, SELECT, FROM, WHERE, JOIN절에만 들어갈 수 있다.
1-1. WHERE절에서의 subquery
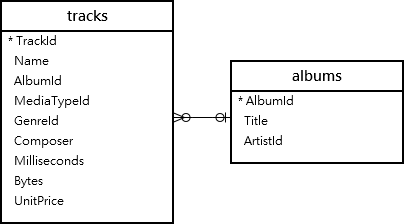
위 테이블에서 albums의 title이 특정한 값인 데이터들을 tracks에서 찾는 쿼리는 다음과 같다.
SELECT trackid,
name,
albumid
FROM tracks
WHERE albumid = (
SELECT albumid
FROM albums
WHERE title = 'Let There Be Rock'
);1-2. FROM절에서의 subquery
from절에서 서브쿼리를 사용하는 경우는 한 컬럼에 aggregate function을 여러번 적용하고 싶을 때이다.
SELECT AVG(SUM(bytes))
FROM tracks
GROUP BY albumid;그냥 위처럼 쿼리하면 되지 않을까 싶지만 위의 쿼리로는 에러가 발생한다.
그래서 택할 수 있는 방법이 먼저 트랙 용량의 합계를 구한 다음 그 합계를 가지고 평균을 구하는 방법이다.
SELECT AVG(album.size)
FROM
(SELECT SUM(bytes) SIZE
FROM tracks
GROUP BY albumid ) AS album;쿼리문을 보면 subquery에서 트랙 용량의 합(SIZE)을 구한 결과셋을 album으로 정의하고 결과셋 안에서 평균을 구하고 있다.
1-3. Correlated subquery
지금까지는 서로 독립적인 쿼리들의 서브쿼리에 대해서 알아보았다.
하지만 서브쿼리와 바깥쿼리간에 의존성이 존재하여 바깥쿼리의 값을 서브쿼리에서 사용해야 하는 경우도 있다.
SELECT albumid,
title
FROM albums
WHERE 10000000 > (
SELECT sum(bytes)
FROM tracks
WHERE tracks.AlbumId = albums.AlbumId
)
ORDER BY title;위 쿼리문은 다음과 같이 동작한다.
- albums의 매 행에 대해서 tracks 테이블에서 albumid가 일치하는 데이터들의 용량의 합을 구하고,
- 바깥 where절에서 크기가 10000000이상인 것만 필터한다.
동작 방식을 보면 알 수 있듯, 매 행에 대해서 작업을 해야 하기 때문에 효율이 떨어질 수 있다느나 점에 주의해야 한다.
2. EXISTS
exists는 서브쿼리를 통해 나오는 결과값이 있는지를 알려주는 논리 연산자이다.
한 가지 주의할 점은, 쿼리에서 나온 결과가 NULL일 경우, 이는 TRUE로 인식한다는 점이다.
SELECT
CustomerId,
FirstName,
LastName,
Company
FROM
Customers c
WHERE
EXISTS (
SELECT
1
FROM
Invoices
WHERE
CustomerId = c.CustomerId
)
ORDER BY
FirstName,
LastName; 기존 쿼리문과 크게 다른 것은 없다.
exists 안에서의 서브쿼리는 invoices 테이블의 customerid가 customers 테이블의 customerid와 같은 경우만 출력하라는 뜻인 것은 알 수 있을 것이다.
select에서 1을 넣어준 것은 조건을 만족하면 1을 반환하라는 것인데, exists는 값이 어떤 것이든 있다면 true, 없으면 false를 반환하기 때문에 1이 아닌 어떤 글자를 넣어도 상관 없다.
반대로 존재하지 않는 것만 보고 싶다면 NOT EXISTS를 사용하면 된다.
또한 exists 대신 다음과 같이 IN을 사용해 같은 기능을 하도록 구현할 수도 있다.
SELECT
CustomerId,
FirstName,
LastName,
Company
FROM
Customers c
WHERE
CustomerId IN (
SELECT
CustomerId
FROM
Invoices
)
ORDER BY
FirstName,
LastName;둘의 차이는 서브쿼리의 결과로 나온 첫행에서 나뉘게 되는데, exists의 경우 첫 행이 존재하면 즉시 탐색을 멈추는 반면, in의 경우 모든 행을 탐색하게 된다.
따라서 일반적으로는 exists의 속도가 더 빠르다.
다만 서브쿼리의 결과 크기가 작을 경우 in의 속도가 더 빠르다.
3. CASE
case 표현식은 일반적인 프로그래밍 언어에서의 if-then-else(또는 switch-case)문과 비슷하다.
어떤 조건을 나열하고 그 조건에 맞는 표현식을 리턴하기 때문이다.
case의 경우 유효한 표현식을 받아들일 수 있다면 어떤 문장(select, update 등)이나 절(where, order by 등)에도 들어갈 수 있다.
3-1. 단순 CASE
일반적인 case 표현식은 다음과 같은 형태로 구성된다.
CASE case_expression
WHEN when_expression_1 THEN result_1
WHEN when_expression_2 THEN result_2
...
[ ELSE result_else ]
END컬럼에 대한 표현식을 선언하고 WHEN에서 조건을 보여준 후 THEN에서 조건에 따른 결과를 보여준다.
사용한 예를 보면 더 쉽게 파악할 수 있을 것이다.
SELECT customerid,
firstname,
lastname,
CASE country
WHEN 'USA' THEN
'Domestic'
ELSE 'Foreign'
END CustomerGroup
FROM customers
ORDER BY LastName, FirstName;3-2. 검색 CASE
단순 case에서는 조건이 ~와 같을 때만 비교했지만, 검색 case의 경우 어떤 형태의 비교연산자라도 사용해 비교할 수 있다.
SELECT
trackid,
name,
CASE
WHEN milliseconds < 60000 THEN
'short'
WHEN milliseconds > 60000 AND milliseconds < 300000 THEN 'medium'
ELSE
'long'
END category
FROM
tracks;