BERT
BERT 개념
BERT: Bidirectional Encoder Representations from Transformer
Transformer에서 Encoder만 사용하는데 이때 Bidirectional한 정보를 사용한다.
Pretrain:언어 모델링 과정
- Masked language model(MLM): 특정 위치의 부분을 Masking 하고 예측하도록 만든다. 즉, 양방(forward, backward)으로 masked 단어 주변을 전부(앞, 뒤 단어 모두) 사용한다.
- Next sentence prediction(NSP): 특정한 두 쌍의 sentence가 들어왔을 때 해당하는 다음 sentence가 corpus에서 다음에 등장했던 것인지 판별한다.
Fine-Tuning: Pretrain 된 모델을 가져와서 BERT의 제일 윗단에 하나의 단순한 레이어만을 추가해서 Fine-Tuning 진행한다.
BERT 구조
Transformer의 Encoder 사용
- L: Layer의 수
- H: Hidden node의 size
- A: Self-Attention head의 number
BERT Input/Output representations
BERT는 다양한 종류의 task를 다루기 위해 Input representation이 유연하게 구성된다. 즉, Input으로 하나의 Single sentence와 pair of sentence 모두 받을 수 있다.
- Sentence: 언어학적으로 의미가 있는 문장이 아닌, 단지 연속적인 단어의 집합으로 볼 수 있다.
- Sequence: Single Sentence 또는 2개 이상의 Sentence
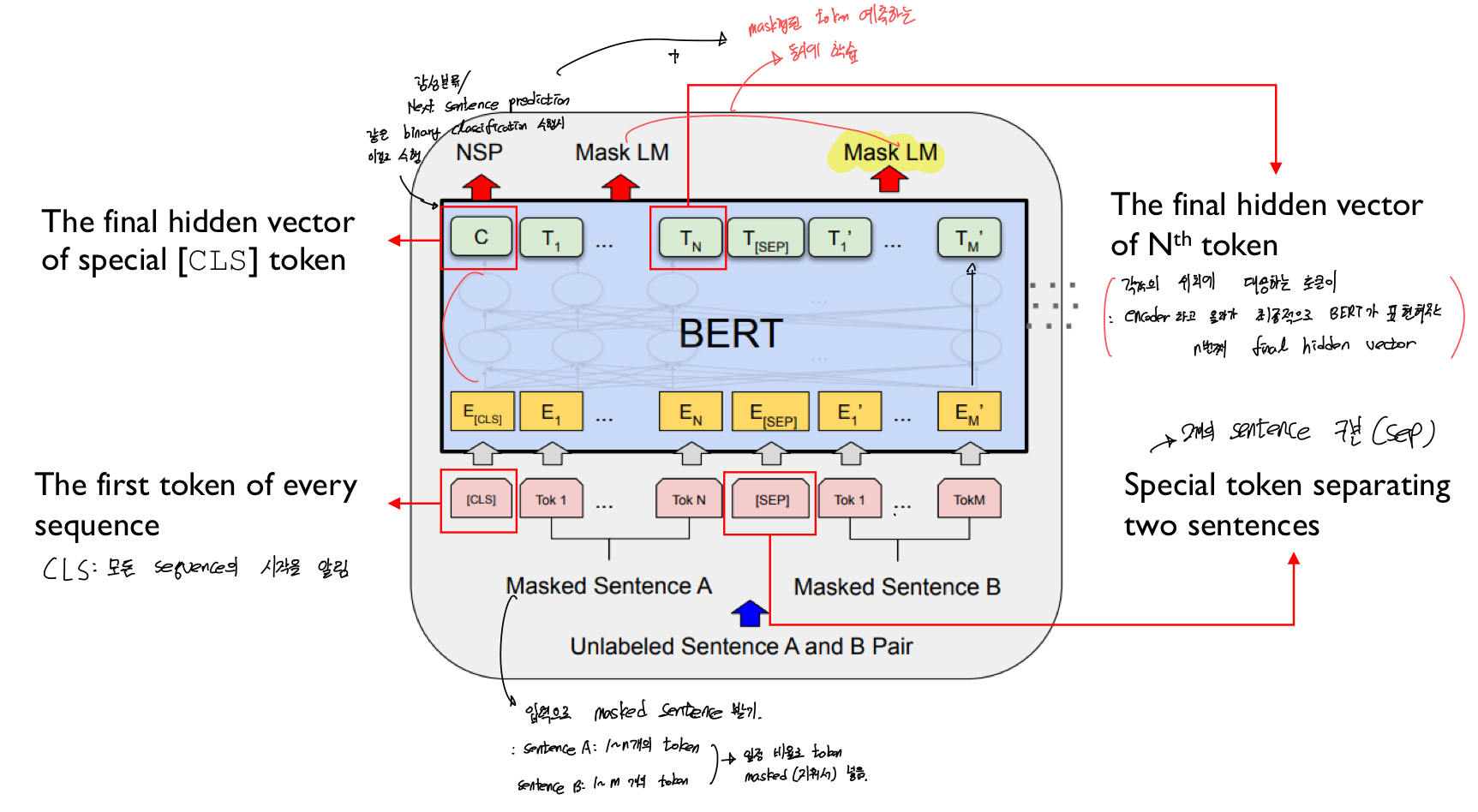
- CLS: 모든 Sequence의 시작 토큰
- SEP: 두개의 Sentence 구분하는 토큰
각 Input Token은 Encoder을 타고 올라가 최종적으로 BERT가 표현하는 N번쨰 final Hidden vector가 된다
- 이때 CLS의 Final Hidden Vector은 감성분류나 다음 문장 예측과 같은 binary classification을 수행한다
- BERT는 위의 토큰의 역할과 Masking된 Token을 동시에 예측하도록 학습하는 것이 목적이다.
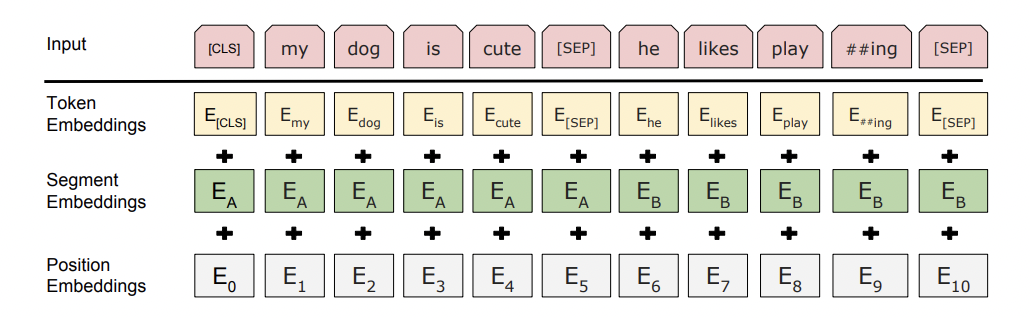
Input Representation은 3가지 토큰 임베딩의 합으로 구성된다.
- Token Embeddings: 각 단어 Token에 대한 Embeddings
- Segment Embeddings: SEP 기준으로 진행. CLS + SEP까지 하나로 Embedding
- Position Embeddings: 상대적인 위치를 사용한다. Transformer와 같다.
Pretrain 방법
Masked Language Model(MLM)
- 전체 token의 15%가 랜덤하게 [MASK] 토큰으로 변경된다.
- BERT 모델 통과한 최종적 Output이 Classification Layer 통과 시 Masked 되기 전 실제 토큰이 되도록 학습시키는 것
- 문제점: MASK는 Pretrain 단계에서만 일어나고 이에 [MASK] 토큰은 Fine-Tuning 단계에는 없다.
- 해결법: Fine-Tuning에서 i번째 Token이 [MASK]가 될 것이라 선택이 되면, 80%는 마스킹하고, 10%는 변환하지 않고, 10%는 랜덤한 Token으로 변환.
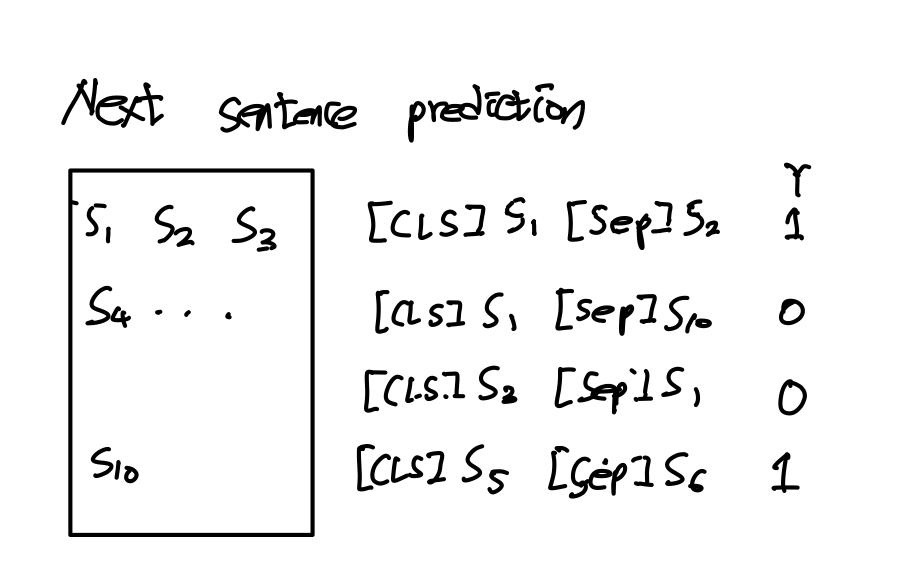
Next Sentence Prediction(NSP)
- Question Answering과 같은 2개 이상 sentences의 relation이 이해가 이루어져야 하는데 문장 단위의 Language Model은 이 relation을 잘 알 수 없다.
- BERT는 이를 위해 Binarized next sentence prediction model을 정의한다.
- 50%는 A,B가 next에 있어 연관된 문장을 가져오고
- 50%는 A,B가 연관되지 않은 문장을 가져와서
- CLS 토큰을 통해 Yes/No로 판별해 예측한다.
즉
BERT는 NSP, MLM으로 문맥을 파악하고 단어의 의미한다. 이게 Pretrain이고 BERT 모델을 Pretrain에 맞도록 파라미터를 조정하는 것이 Finetuning이다.

안녕하세요