주행 기록계 데이터 분석을 통한 주행 습관 분석
with TipsInstitute, Inha University
프로젝트 진행 이유
교통사고의 주요 원인은 사람들의 난폭한 운전이다. 특히 대한민국의 교통사고 사망자 비율은 OCED 국가 중 최상위권에 속하고, 사업용 버스의 수치가 압도적으로 나타난다.
하지만 과속, 급정거, 급출발 등의 난폭운전은 모두 연관되어 있는데 현재 교통안전공단은 절대적 수치를 기준으로 특정 행동에만 기준을 적용해 단순한 평가를 진행하고 있다. 이에 운전자집단을 군집화해 상대적 평가 기준을 마련하며 운전자 개인별 위험도 특성을 부여해 경각심을 갖도록 한다.
데이터셋
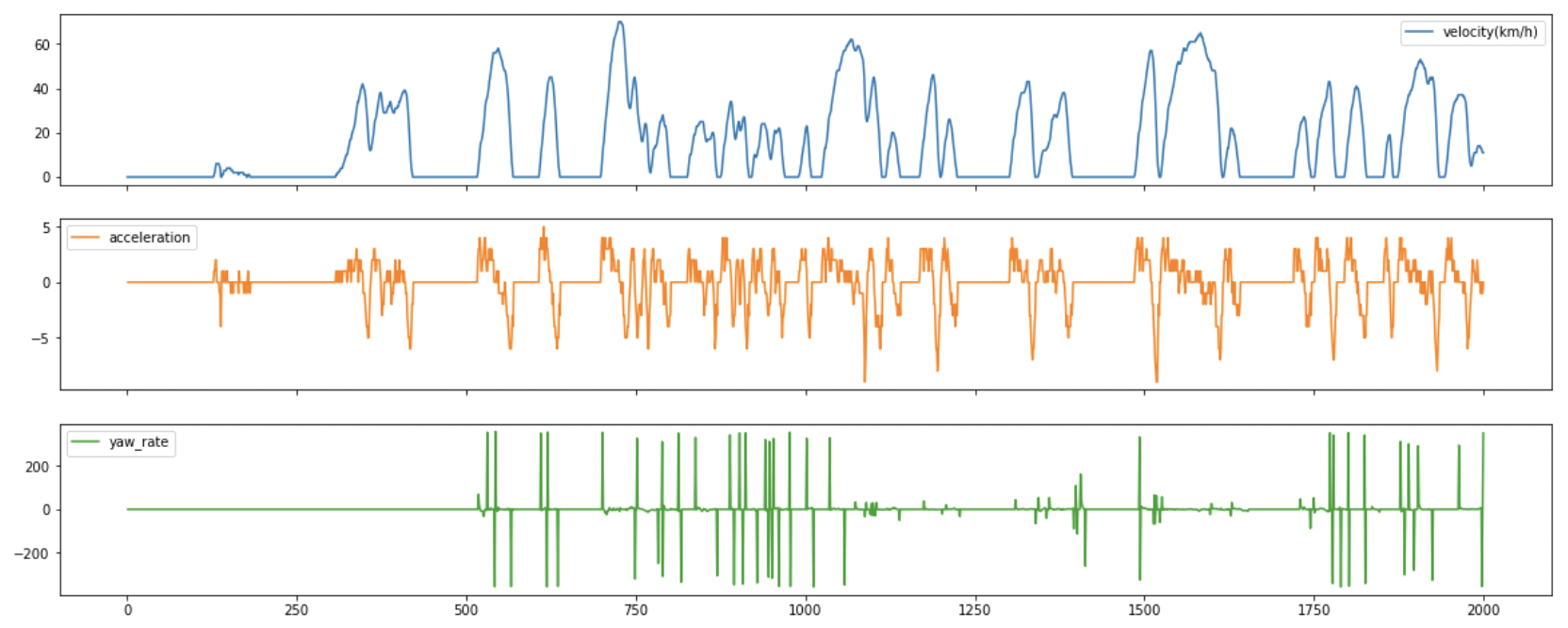
DTG(Digital Tachograph), 주행운전기록계에서 나오는 데이터를 사용.
DTG는 모든 시내버스에 의무적으로 부착되어야 한다.

총 12개의 컬럼으로 이루어져 있으며
- 가속도: 1초간 속도의 차이
- 요레이트: 1초간 Angle의 차이
두 컬럼을 추가해 속도, 가속도, 요레이트 3가지 요소만 사용했다.
불일치도 계산
데이터의 급격한 변화 시점을 파악하기 위해 ACD(Abrupt Change Detection) 기법 사용함.
본 연구에서는 이를 위해 uLSIF(unconstrained least-squares importance fitting) 메서드를 사용했다.
uLSIF
- 확률분포 간 거리를 측정하여, 분포간의 변화 감지 또는 특징 추출한다.
- 두개의 연속된 시간 window에서 밀도 기반 차이 측정하여 (density ratio based dissimilarity measure)을 사용하여 변경된 점수를 기록한다.
- 이때의 점수가 불일치도(dissimilarity)이다.
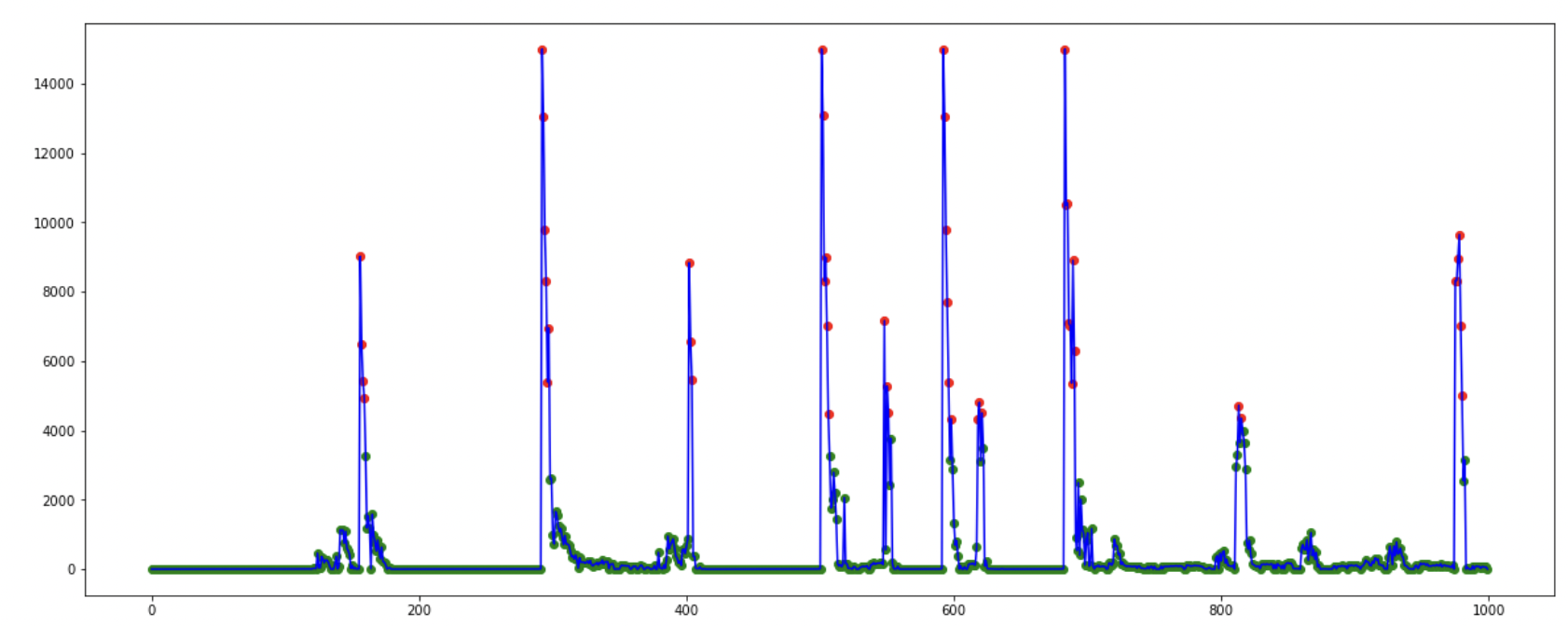
- 불일치도의 상위 5%지점을 급격한 주행 변화의 시발점으로 정의
- 시발점 이후 15초간 운행을 위험 운전이라 판단해 해당 데이터를 추출하고 이를 Driving Event로 명명

Driving Event 그래프
빨간 점이 임계값을 넘은 상위 5%의 값이고 Driving Event의 시발점이다.
ANN Auto Encoder
결국 Driving Event의 크기는 (15,3)이다. 위 데이터를 입력 데이터로 해서 군집화하고자 하는데 차원의 크기가 너무 크기에 특징을 파악하기 어려울 것으로 판단하였고 또한
군집화 전 Driving Event의 특징을 추출해야 했다.
- 입력 데이터의 특징을 추출해 저차원의 latent space로 매핑하는 과정에서 데이터의 차원 축소
- Auto Encoder:
비지도 학습 중 하나로, 입력 데이터를 압축하고 재구성하는 과정을 통해 데이터의 특징 추출 - Encoder + Decoder
Encoder 입력 데이터를 저차원의 표현으로 압축한다. 입력 데이터는 인코더의 입력층에 들어가고, 여러개의 은닉층을 거쳐 최종적으로 저차원의 특징 벡터로 압축된다. 인코더의 목표는 입력 데이터의 주요한 특징을 추출하여 고차원 데이터를 저차원으로 효율적으로 표현하는 것이다.
Decoder 디코더는 인코더의 출력인 저차원의 표현을 입력 데이터의 재구성으로 변환. 저차원의 특징 벡터를 받아들이고, 여러개의 은닉층을 거쳐 최종적으로 원본 입력 데이터와 유사한 형태로 재구성하는 것 이 목표이다.
즉, Auto Encoder를 통해 입력데이터를 효율적으로 압축하고 중요한 특징을 학습해 재구성할 수 있다.
군집화
차원축소된 Driving Event((15,3) >> (30,1))을 군집화해 Elbow method 사용해 총 8개의 군집으로 나눴다.
이제 각 군집별
