LDA 이론 공부 및 진행 방향 생각 정리
LDA(Latent Dirichlet Allocation)
알고 있는 것: 문서 별 단어
추론해야 할 것:
1. Topic 별 단어의 distribution
2. 각 문서(document)별 Topic의 distribution
3. 각 문서의 단어(word)는 어느 Topic에서 나왔는가
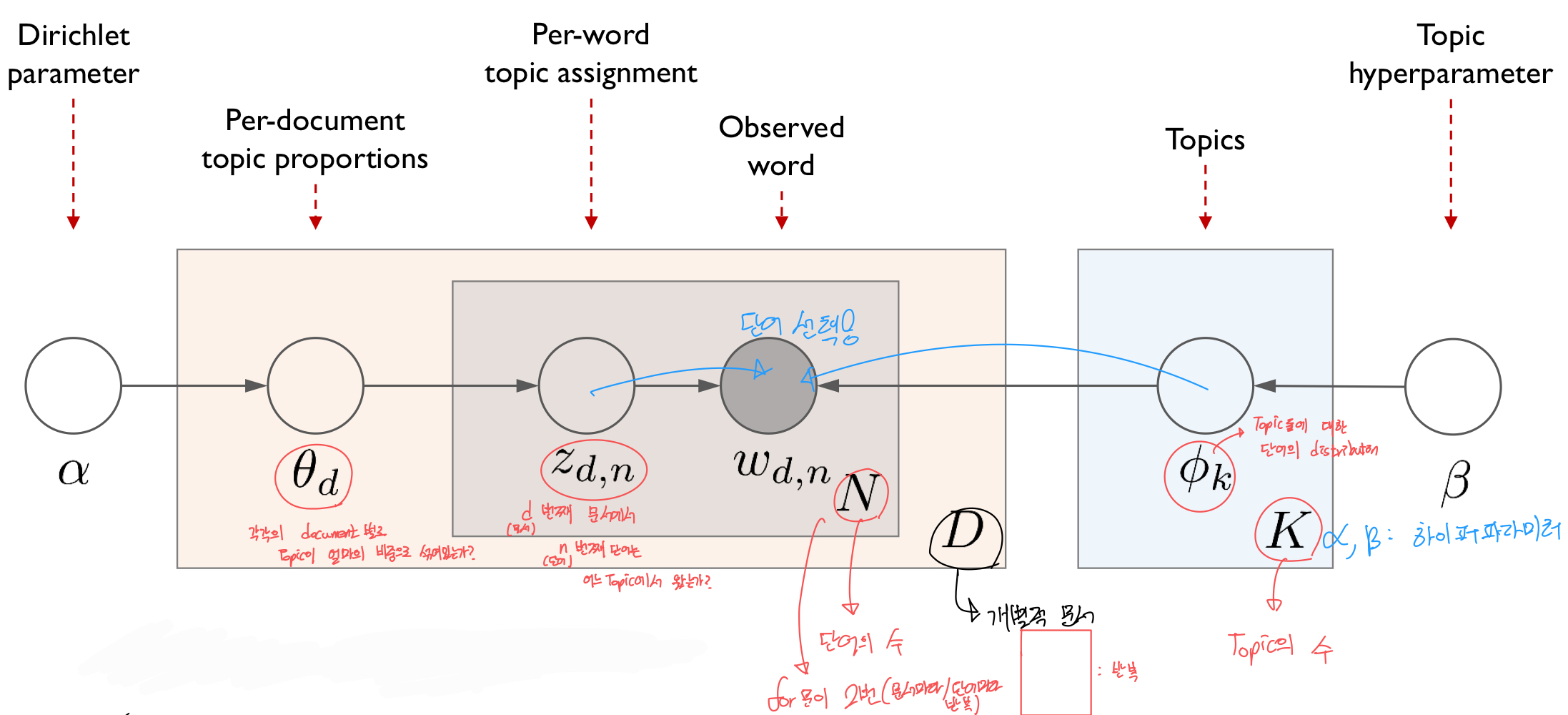
구성은 위 그림과 같다.
a,B는 하이퍼파라미터이다.
B로부터 Topic 별 단어의 distribution
a로부터 Document 별 Topic의 distribution
그리고
Z(d,n) d번째 문서에서 n번쨰 단어는 어느 Topic에서 왔는가에 대한 정보 + Topic 별 단어의 distribution =
W(d,n), 즉 documnet에서 n번째 단어를 선택하는 것이다.
이따 a,B는 Dirichlet 분포를 따른다.
단점: 모든 단어별로 문맥을 고려하는 것이 아닌 독립이라 가정한다.
이때 목적함수는 다음과 같다.

LDA 추론 방법
Collapsed Gibbs Sampling
Dirichlet, Gibbs sampling의 원리는 별도 노트에 필기했으니 전체적인 과정만 복기한다.
Word를 알고, Z(-i)라 가정할 떄 Z(i) = j일 확률은 다음 4가지의 영향을 받는다.
1. 현 document에서 word(i)제외하고 topic j에 할당 된 단어의 수 + B >> 비례
2. 현 documnet에 word(i) 제외하고 전체 단어의 수 + VB >> 반비례
3. word(i) 제외하고 Topic j에 할당한 동일한 단어 word의 수 + a >> 비례
4, word(i) 제외하고 j번째 Topic에 할당된 전체 단어 수 + Ka >> 반비례
a,B가 커지면 토픽들의 분포가 비슷해지고, 작아질수록 특정 토픽의 빈도수가 높도록 치우친다.
그리고 하이퍼파라미터 덕분에 실제 문서에서 나타나지 않더라도 출연 확률을 0으로 가져가지 않을 수 있다.
깁스 샘플링 과정
- Document별, word 별 랜덤하게 모두 토픽이 할당되어 있다.
- 우리가 알고자 하는, 예를들어 Z(0,0)을 마스킹하고 나머지를 Z(-i)로 나타낸다.
- 이를 통해 p(Zi=j)를 추정하고 특정 토픽을 Z(0,0)에 할당한다.
- Z(0,1)을 같은 방법으로 진행
- 전체 문서, 단어에 대해 진행했을 떄 1iteration
- 수렴할때까지 반복
평가 방법: Perplexity
LDA 토픽 모델링에서 정해진 최적의 토픽 수는 존재하지 않는다.
즉, 정량 + 정성적(직접 확인) 방법으로 정하는 수밖에 없다
그나마 정량적으로 평가할 수 있는게 Perplexity가 있다.
perplexity는 낮을수록 좋다고 할 수 있다.
2023.03.28 진행 방향
개선점
-
coherence score을 구할 때 학습한 모델과 실제 학습 모델에 파라미터 동일시하였다.
-
coherence score은 높을수록, perplexity score은 낮을수록 좋을 확률이 높으므로 둘 다 plot 후 coherence가 높은 topic 수에서 perplexity를 고려하여 최적 토픽 수를 뽑는다.
생각한 점 + 앞으로 할 일
-
현재 고려하는 것은 보유한 데이터(사고내용, 원인규명결과)로부터 사고내용을 범주화 후 원인규명결과를 또 범주화해서 시각화하기 >> 이는 Topic별 단어의 distribution 관점에서 풀어가는 것.
-
그렇다면 각 문서에 대해 Topic의 distribution을 활용할 수 있는 방법은 없을까? 매 사고시마다 전체 모델을 업데이트 한 후 해당 문서의 Topic을 확인하면 좋을 것. 하지만 지속적으로 업데이트 하다보면 문서 전체의 Topic 내용이 변할 수 있다. 해결 방안 생각해보기
-
최적 파라미터 개수를 구하는 방안 생각하기
-
LDA는 문맥을 파악하지 못한다. 문맥을 파악하는 방법으로 진행할 수는 없을까? 생각해보기.
출처 및 참고 영상:
https://www.youtube.com/watch?v=WR2On5QAqJQ
https://www.youtube.com/watch?v=iwMSCsiL6wQ
