딥러닝 기초(1)
퍼셉트론
인공신경망의 한 종류로 인간의 뇌를 본따 만든 구조
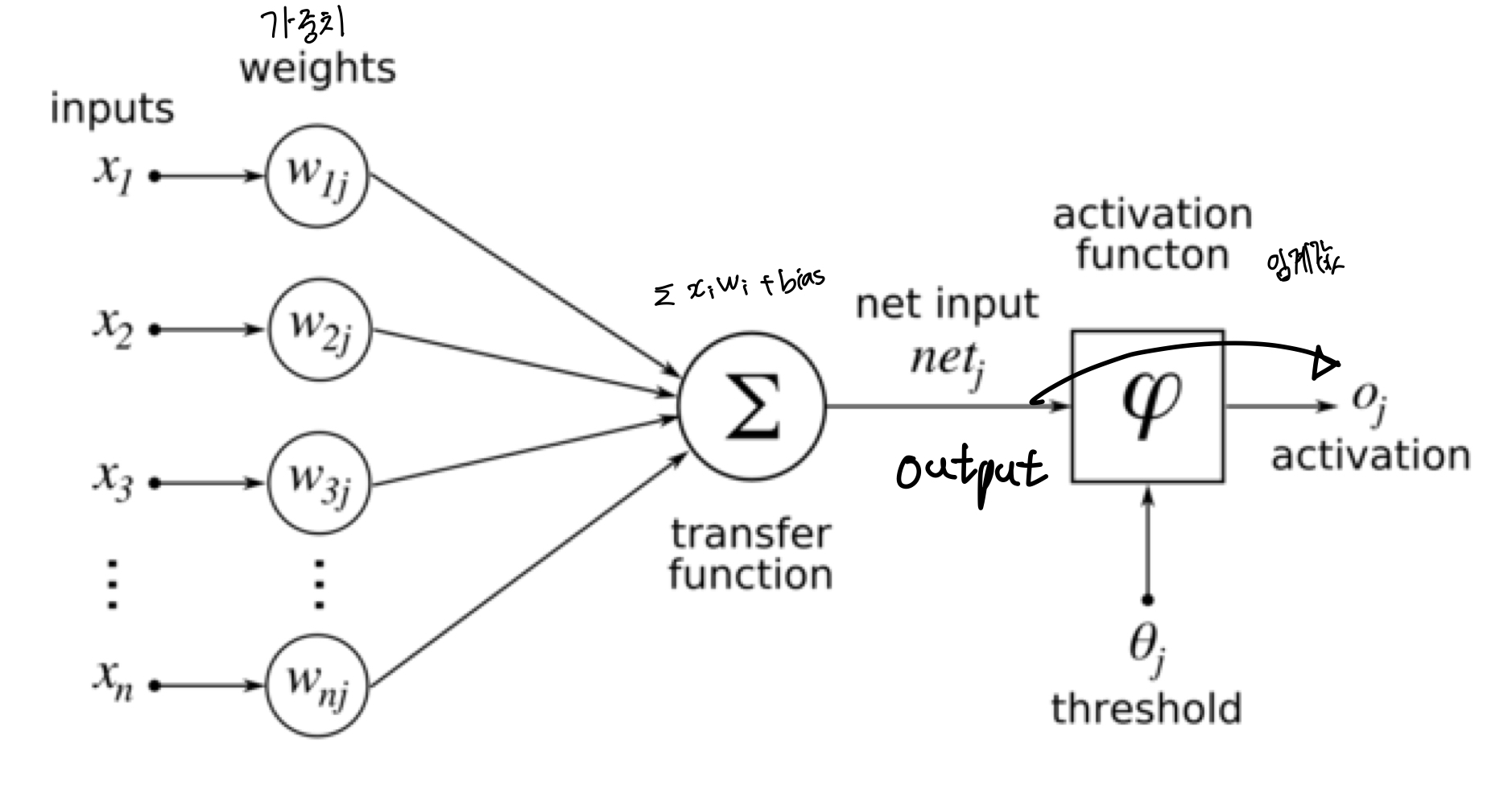
y = (input과 weights들의 행렬곱 + bias(활성화함수가 잘 작동하도록 설정))
output = activation(function) 의 구조로 이루어졌다.
AND, OR, XOR Gate
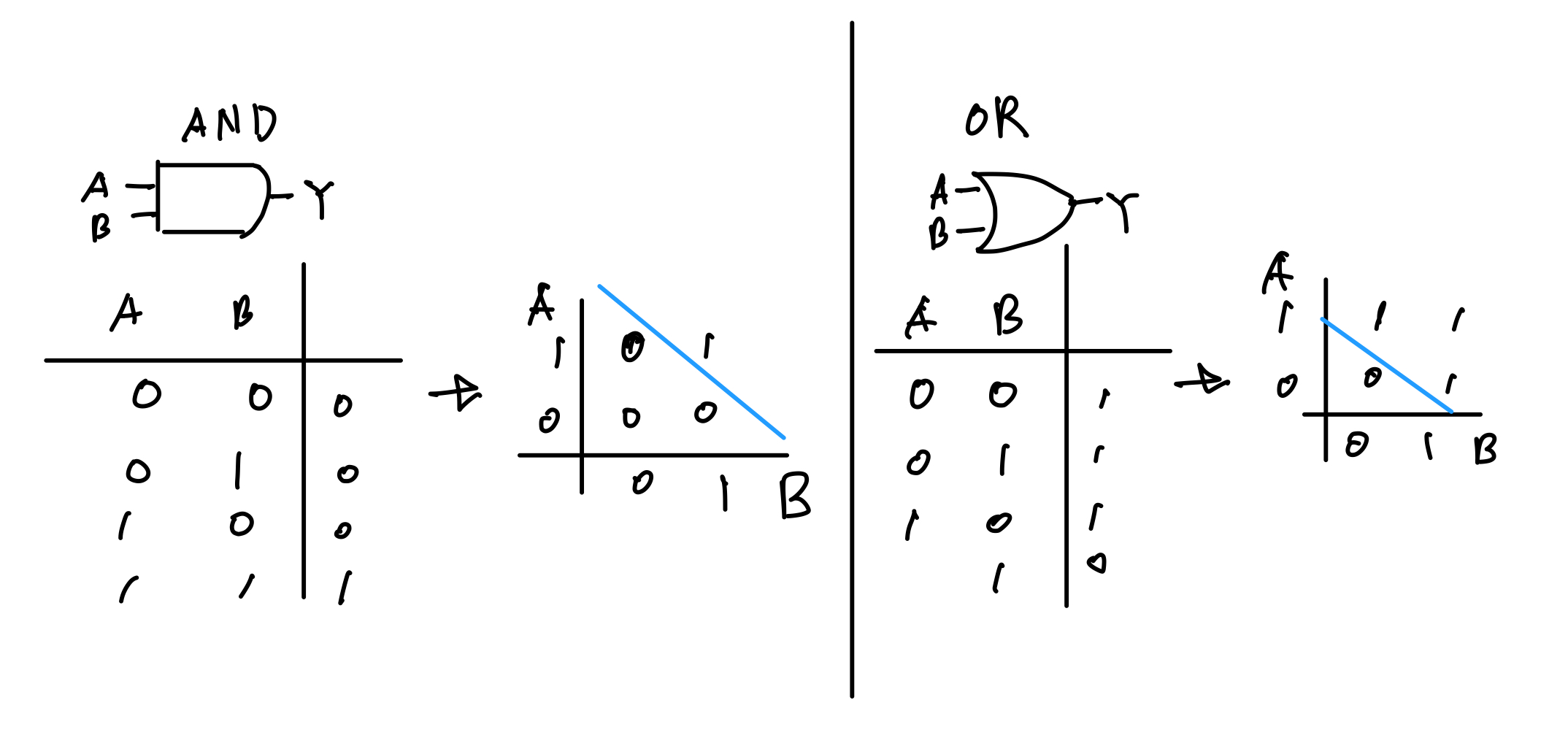
AND와 OR Gate는 단층 퍼셉트론으로 표현 가능하지만 XOR은 불가.
해결하고자 다층 퍼셉트론(Multi-Layer-Perceptron)의 개념이 등장했다.
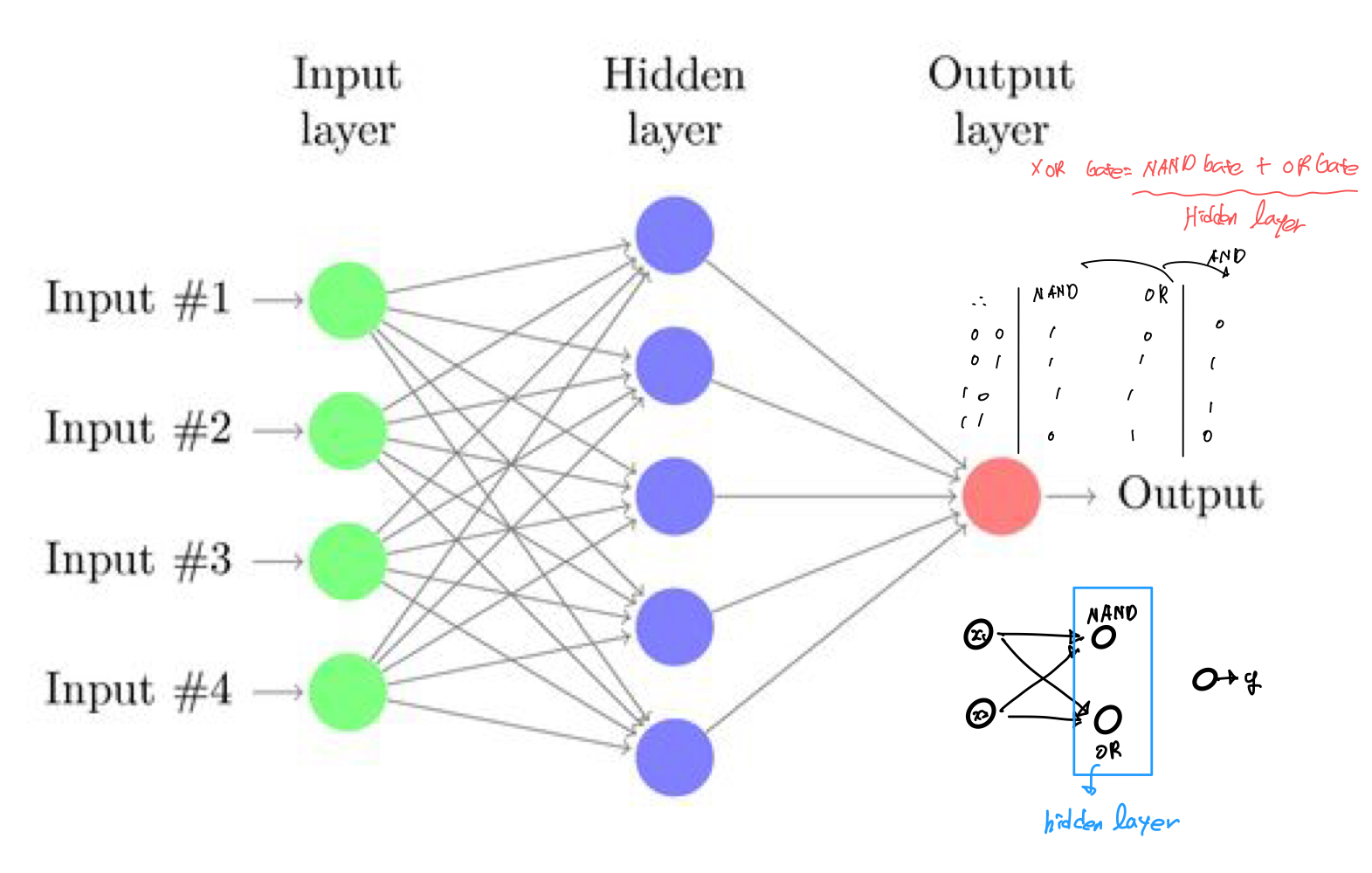
XOR Gate는 다음과같이 NAND, OR, AND의 결합으로 표현 가능
(1개의 은닉층)
Hidden Layer가 3개 이상일 떄 딥러닝이라고 부른다.
딥러닝에서는 Loss Function을 최소화하는 방향으로 optimization을 사용해, 즉 cost를 최소화하는 Weight와 bias를 찾는 것이 목표이다.
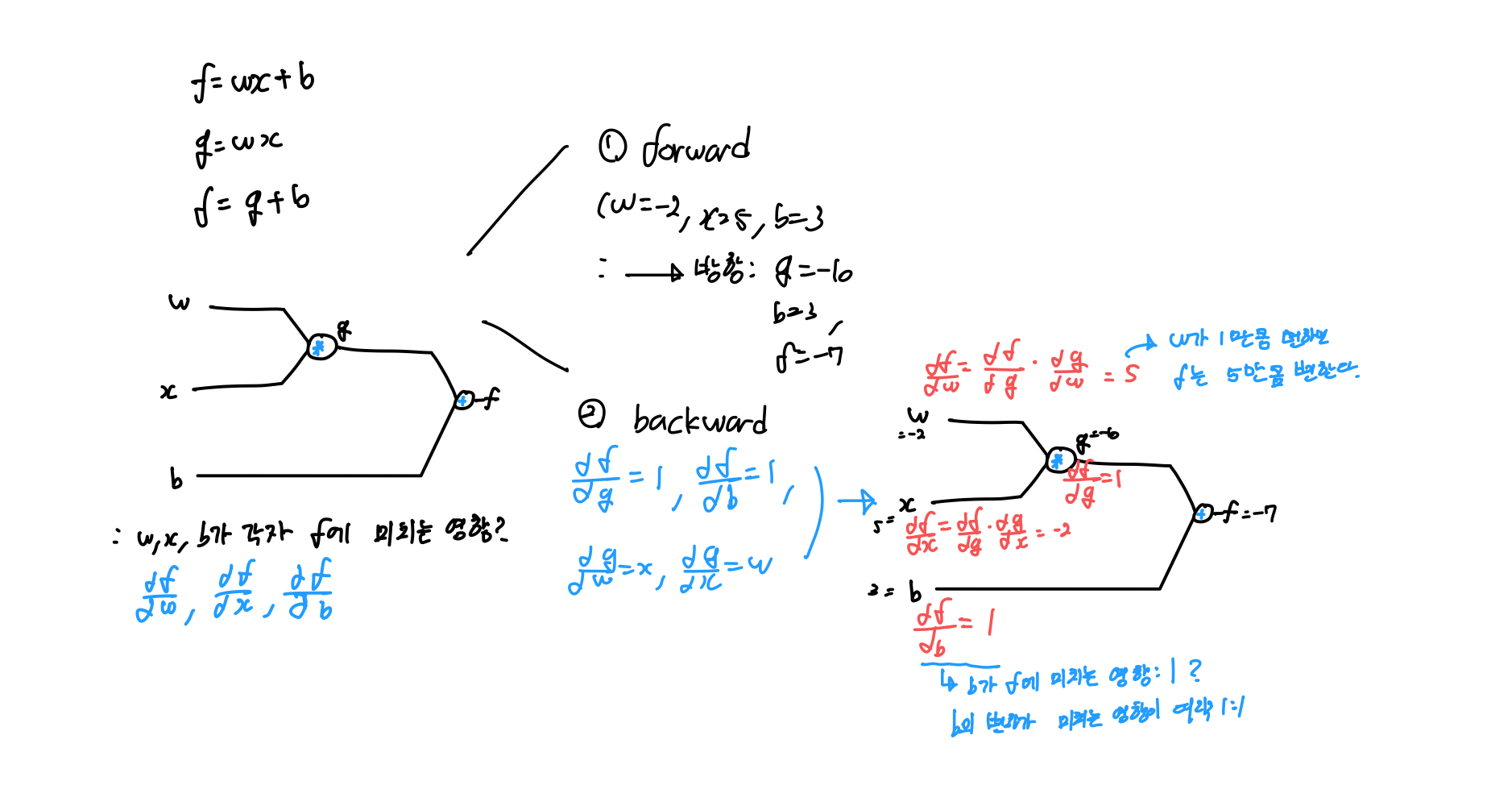
역전파(Backpropagation)
W,b를 구할 떄 역전파 라는 개념을 사용한다.
Activation 함수를 통한 Forward Propagation 계산 후 Cost 구하고 Backpropagation 적용하며 W값 업데이트.
(Multi) Linear Regression
입,출력 데이터가 있고 Weight와 bias를 구하는 것이 목표이다.
Hypothesis: Weight와 bias 0으로 초기화
W = torch.zeros(1,requires_grad = True) #requires_grad=True: 학습할 것
b = torch.zeros(1,requires_grad=True)
hypothesis = x_train * W + bW,b 0으로 선언 후 hypothesis구하고, cost 구한 후 optimizer 적용
#x_train,y_train,W,b, hypothesis 초기화 후
nb_epochs = 1000
for epochs in range(1,nb_epochs+1):
hypothesis = x_train * W + b #Hypothesis 예측,
cost = torch.mean((hypothesis - y_train)**2) #MSE사용
optimizer = optim.SGD([W,b],lr=0.01) #Optimizer 정의 시 아래 3줄 따라옴
optimizer.zero_grad() #Gradient 초기화
coist.backward() #Gradient 계산
optimizer.step() #step()으로 Gradient descentMulti Linear Regression 에서
hypothesis = x_train.matmul(W) + b+
nn.Module 상속해 모델 생성 + Cost 계산 가능
Logistic Regression, Softmax Classification 등 모두 비슷하게 가능.
각종 Optimizer이 함수들은 추후 필요하면 정리할 예정
위 내용은 모두를 위한 딥러닝 시즌1,2(Pytorch)를 바탕으로 작성되었습니다.
https://hunkim.github.io/ml/
https://deeplearningzerotoall.github.io/season2/lec_pytorch.html
