CQRS 패턴이 무엇인가?
CQRS 패턴은 아키텍처 레벨에서 Command 모델과 Query 모델을 명확히 분리하는 것입니다.
이 패턴은 Application을 벗어나 DB Layer까지 고려한 방법입니다.
왜 CQRS 패턴이 필요한가?
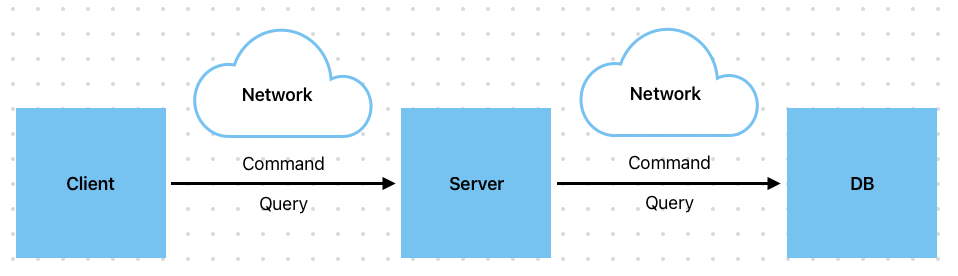
보통 일반적인 CRUD 패턴에서는 그림과 같이 서버와 DB가 네트워크를 두고 존재할겁니다. 서버로 요청된 api는 Command든 Query든 상관 없이 모두 하나의 DB에 접근하게 됩니다. 하지만, 서버에서 정해둔 DB의 CP(Connection Pool)은 한정되어 있습니다. 실제로 사용자가 처리하는 대부분의 작업은 Read 작업이고, 보통 Read 작업은 Indexing, Caching 등을 활용해 효율을 극대화하는 방법을 사용합니다. 하지만 CP가 한정되어 있고 cahce miss가 발생한다면 스레드가 Connection를 얻기 위해 대기하며 네트워크 병목 과 Command로 인한 DB 서버 cpu 및 memory 경합 이 발생할 수 있습니다.
우리는 이를 대비하기 위해 적당한 CP를 선정할 필요가 있습니다. 하지만, 이론 상 적당한 CP의 개수는 core_count * 2 + spindle count 입니다. green winit은 ssd 기반 ebs volume을 사용하는 ec2 환경에서 배포하므로 spindle count를 알 수 없습니다. 그래서 보통 안정적으로 작게 시작하는데, t2.micro 기준 1 core * 2 ~ 1 core * 4 = 2 ~ 4 개 정도의 CP가 적당할 것으로 보입니다.
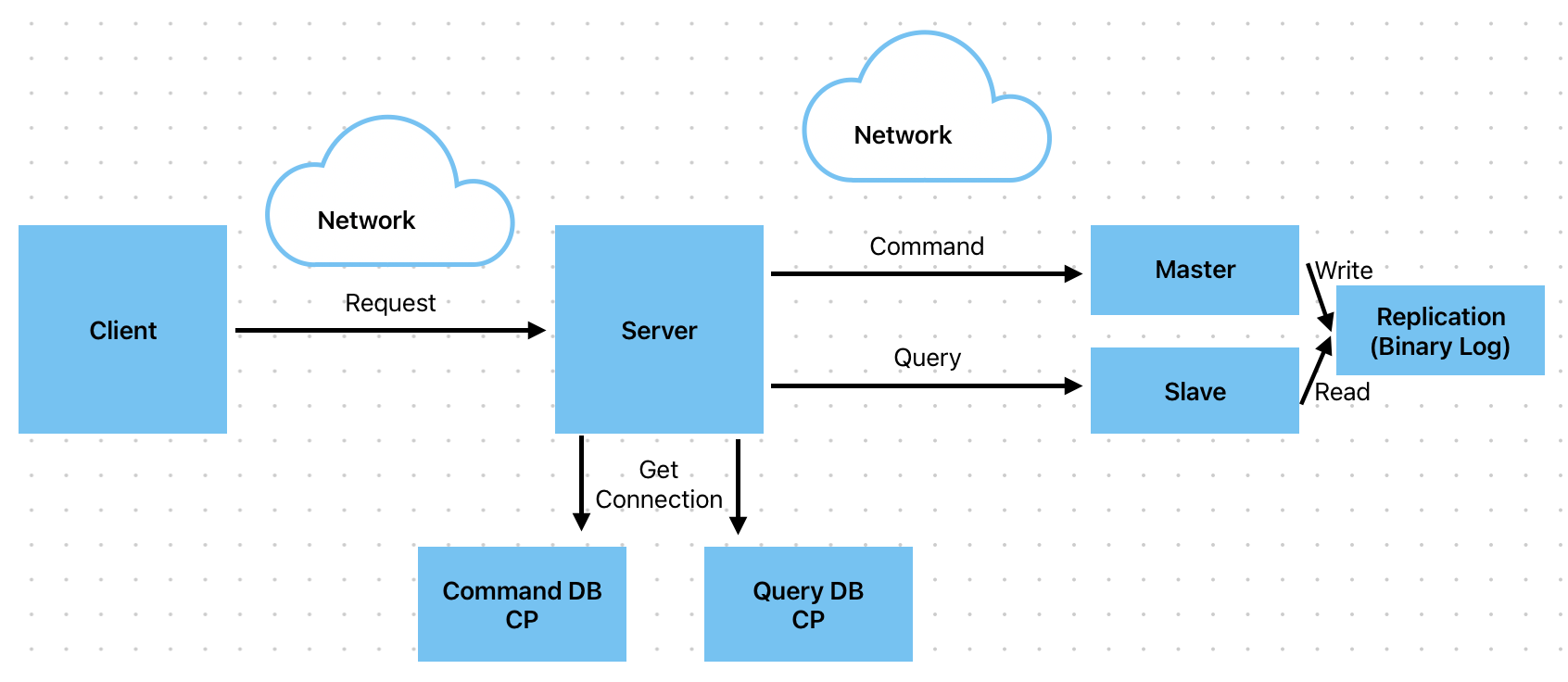
선정 기준을 바탕으로 Boot에서 최대 4개의 CP를 할당했다고 했을 때, CRUD 패턴에서는 Command와 Query가 같은 CP를 공유하게 될겁니다. 그럼 위에서 언급된 문제들이 발생하게 될 것이고 우리는 이를 개선하기 위해 DB는 Master/Slave 전략으로, 서버에서는CQRS 패턴을 도입하며 앞서 언급한 문제점을 해결 할 수 있습니다.
여기서 중요한 포인트는 CQRS 패턴은 아키텍처 레벨에서 분리하는 것으로 DB와는 연관이 없음을 인지할 수 있습니다!
실제 발생 할 수 있는 시나리오 (3개의 CP를 선정)
챌린지 인증 Command 중 이미지 업로드는 I/O bound 작업으로 상당한 시간이 소요됩니다. 특히, 외부 서비스와 연동된 만큼 AWS 트래픽에 따라 처리 속도는 더욱 느려질 수 있습니다. T type 인스턴스의 경우 버스터블 성능으로 동시간대 여러 사용자가 이미지 업로드를 한다면 CPU 크레딧이 빨리 소진되어 처리 속도는 매우 떨어집니다.
이런 상황을 고려해서 이미지 업로드 작업은 2s가 소요된다고 가정하겠습니다.
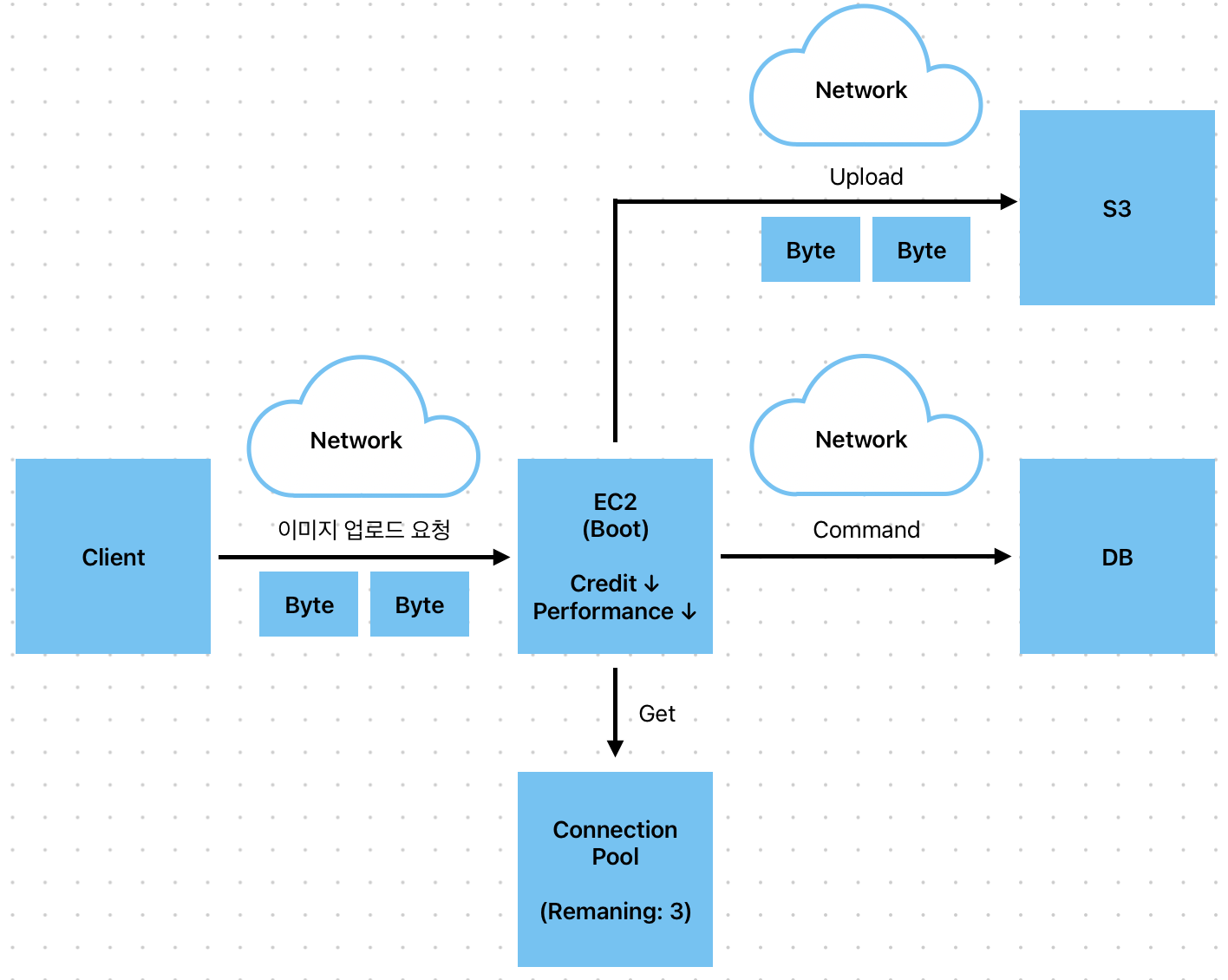
그림과 같이 이미지 업로드 요청이 3건이 발생했을 때, DB 커넥션이 모두 소진되고 약 2초 간 다음 작업은 아무것도 하지 못하게 될 것입니다. GreenWinit 기능을 예시로, 팀 챌린지 인증 시 팀원이 모두 한 장소에서 인증 을 하는 시나리오가 발생할 수 있습니다. 이 때, 약 20명 정도가 한 번에 이미지 업로드를 하고 그 때 CP가 모두 소진되어 READ 작업에서는 CP에 잔여 Connecion 객체가 생길 때까지 대기할 수 밖에 없습니다.
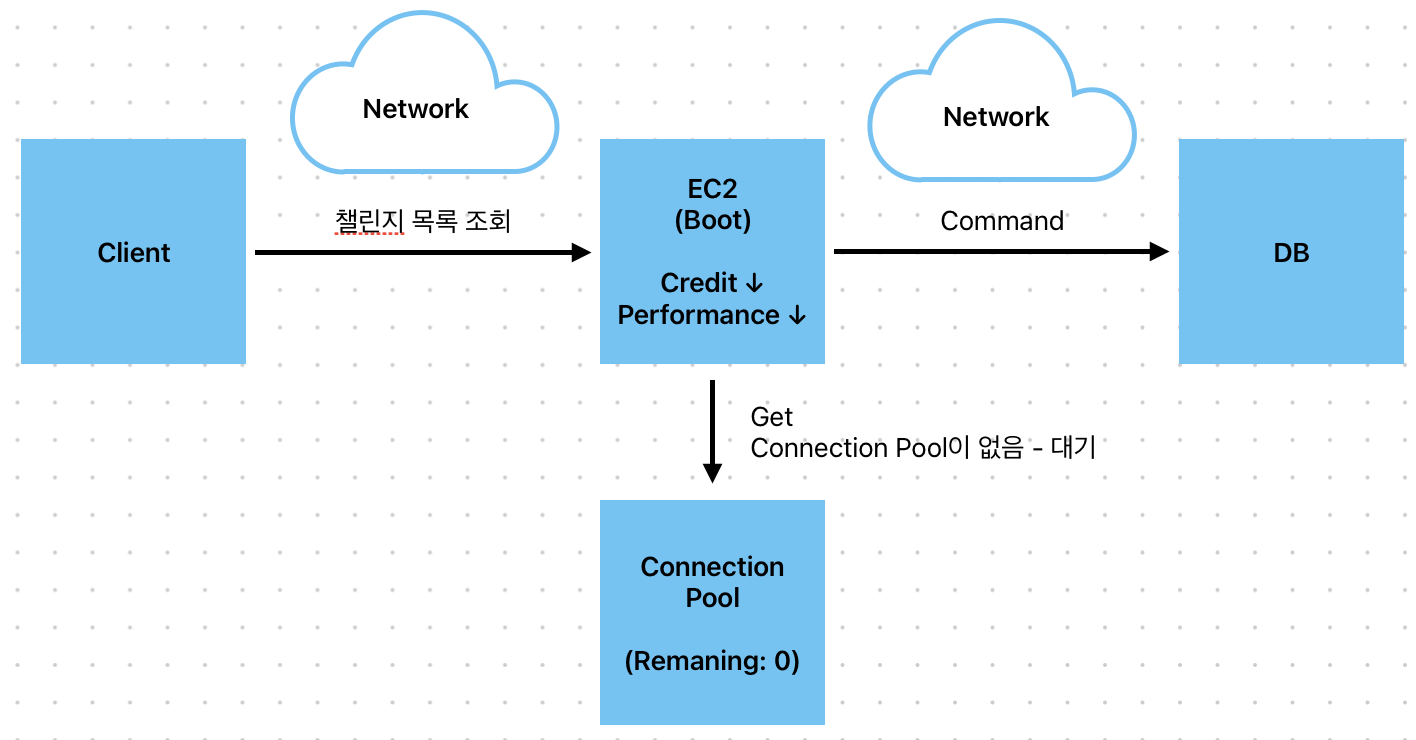
물론 Caching을 도입해서 RDB Connection 객체를 얻기 전, Redis와 같은 NoSQL Connection 객체를 통해 RDB Connection 문제에서 벗어날 수 있습니다. 하지만, 캐시도 리소스 제한으로 인해 hit rate가 100%가 될 수 없기 때문에 결국 RDB Connection을 점유하게 됩니다. 그리고 모든 Read Data가 Caching 대상이 될 수도 없기 때문에 CQRS 아키텍처를 도입해 이 문제를 해결 할 수 있습니다.
우리는 CQRS 패턴을 왜 도입하는가?
앞서 시나리오를 바탕으로 필요한 상황이 발생할 수 있다는 것은 알 수 있습니다. 이를 대비하기 위해서 CQRS 패턴을 도입하는가? 에 대한 질문이 온다면, 저는 반은 맞고 반은 틀리다라고 답할 것 같습니다.
현재는 MVP 작업을 진행하고 있고, DB Replica까지 고려한다면 너무 과한 설정이라는 생각이 듭니다. 그래서 CQRS 아키텍처가 아니라 CQRS 패턴만 도입하면서 명확한 책임의 코드를 작성하는 것에 중점을 두려고 합니다!
CQRS를 도입했을 때 장점 1 - 명확한 책임 분리
public class Controller {
private final Service service;
public Api<?> get() {
var result = service.getData();
return Api.ok(result);
}
public Api<?> set() {
var result = service.setData();
return Api.ok(result);
}
}
public class Service {
private final Repository repository;
public Object getData() {
return repository.findById(1L).orElseThrow();
}
public Object setData() {
Object obj = repository.findById(1L).orElseThrow();
obj.setData("any");
return obj;
}
}예시 코드와 같이 일반적인 CRUD 패턴을 사용하면 한 코드에서 Service와 Query가 공존하면서 코드를 한 번에 식별하기 힘들어집니다. 이를 CQRS 패턴으로 분리하면객체지향 생활 체조 원칙 에 따라 클래스를 50줄 이하로 유지 할 수 있습니다.
public class QueryService {
private final Repository repository;
public Object getData() {
return repository.findById(1L).orElseThrow();
}
}
public class CommandService {
private final Repository repository;
public Object setData() {
Object obj = repository.findById(1L).orElseThrow();
obj.setData("any");
return obj;
}
}변경된 코드와 같이 커맨드는 커맨드 작업만, 쿼리는 쿼리 작업만 진행하면서 명확한 책임을 분리할 수 있습니다.
단지 이 이유밖에 없지만, 코드 리뷰를 진행하는 저희 협업 방식 상 코드 가독성 측면에서 큰 이점을 가져올 수 있습니다. 그리고 추후 미래의 유지보수에도 큰 장점을 가져올 수 있습니다.
단지 이 이유밖에 없지만, 코드 리뷰를 진행하는 저희 협업 방식 상 코드 가독성 측면에서 큰 이점을 가져올 수 있습니다. 그리고 추후 미래의 유지보수에도 큰 장점을 가져올 수 있습니다.
추후 어떤 장점을 가져올 수 있을까?
진정한 CQRS 아키텍처로의 발전
앞서, CQRS에 대한 설명으로 DB에서 Master/Slave 전략을 사용하는 예시를 들었습니다. 예시를 들었을 뿐 CQRS 아키텍처에서 Command와 Query를 분리하기 위해 저장소는 다양하게 조합해서 사용할 수 있습니다. 미래에 우리는 조금 더 나은 성능을 위해 Command는 Maria DB로 마이그레이션, Query는 NoSQL 기반으로 마이그레이션 했을 때 각 Service 코드만 DB 구현체에 맞게 수정해주면 됩니다.
하지만, 그만큼 복잡도가 증가합니다. Command와 Query가 분리되면서 데이터 정합성을 위해 동기화 처리를 해줘야합니다. 그래서 우리는 이 복잡도를 제외하고 MVP에서는 코드 레벨에서만 집중하며 객체지향적이고 미래에 개선가능한 아키텍처로 설계했습니다.
로깅과 모니터링의 이점
쿼리의 로깅은 실제로 많은 조회를 요구하지 않습니다. 특히 비즈니스 로직이 없는 경우 더 더욱 로그는 무의미해집니다. 만약 Service에서 통합적으로 로깅을 한다면 CRUD 패턴에서는 무의미한 Query 작업에도 로그가 남게됩니다. 이를 분리하면서 Command 전체에는 일괄적으로 로그 및 응답 시간을 확인할 수 있고 Query에는 필요에 따라 중요한 로직에만 로그 및 응답 시간을 확인할 수 있습니다.
협업의 이점
앞서 언급했듯, 책임이 명확하고 간소화 된 코드로 집중 된 코드 리뷰를 통해 큰 이점을 가져올 수 있습니다. 뿐만 아니라 Command와 Query에서 동시에 버그가 발생 했을 때, 팀원 간 병렬로 문제를 해결 할 수 있습니다.
마치며
CQRS 패턴이 무엇인지?, CQRS 패턴이 왜 필요한지?, 우리 서비스에 도입 시 어떤 장점이 있는지? 등에 대해 정리해봤습니다.
핵심은 "단계적 접근"입니다.
처음부터 완벽한 CQRS 아키텍처를 구축하려 하지 않고, MVP 단계에서는 코드 레벨 분리를 통해 명확한 책임과 가독성을 확보하는 것에 집중했습니다. 이를 통해 팀 협업 효율성을 높이고, 미래 확장 가능성을 열어두는 것이 현재 우리에게 가장 현실적이고 가치 있는 선택이라고 판단했습니다.
물론 이 방식이 완벽한 해답은 아닙니다. 서비스가 성장하면서 실제 성능 병목이 발생할 때, 그때 DB 분리나 NoSQL 도입 등을 고려해도 늦지 않다고 생각합니다.
오버 엔지니어링보다는 적정 기술을 택한 셈이죠.
제가 고려한 포인트들이 팀원들에게도 설득력 있게 다가갔으면 좋겠고, 다른 관점이나 개선 방향이 있다면 언제든 피드백을 받고 싶습니다. 이런 기술적 고민과 토론 과정 자체가 팀 전체의 성장에 도움이 된다고 믿습니다.
더 자세한 내용은 아래 레퍼런스를 참고하면 CQRS 패턴에 대한 자세한 설명이 작성되어 있습니다!
