시작하며
"관리자 페이지에서 데이터를 엑셀로 내려받고 싶어요"
흔한 요구사항이지만, 막상 구현하려니 의외로 고민거리가 많았습니다.
- 이게 REST API로 처리하는 게 맞나?
- Spring에서 파일 다운로드는 어떻게 하지?
- 팀원들이 각자 다르게 구현하면 어떡하지?
- ...
작년 처음 Java를 학습 할 때 Apache POI를 활용해서 간단하게 excel 파일을 추출한 경험이 있었지만, 실제 프로젝트에서 사용하는 것은 처음이다보니 여러 고민 포인트가 발생했습니다.
이 포스트에서 구현하기까지 어떤 고민 거리를 만나고 어떻게 해결했는지 경험을 담아내려고 합니다.
우선 구현하기
Spring Web MVC에서 파일 다운로드를 위한 기술을 제공하는가?
Spring Boot 자동 구성으로 MappingJackson2HttpMessageConverter을 지원하는 것은 여러 문서에서 소개하고 있으므로 Spring Web MVC 자동 구성 기술을 더 깊이 파헤쳐봐야 했습니다.
@AutoConfiguration(
after = {DispatcherServletAutoConfiguration.class, TaskExecutionAutoConfiguration.class, ValidationAutoConfiguration.class}
)
@ConditionalOnWebApplication(
type = Type.SERVLET
)
@ConditionalOnClass({Servlet.class, DispatcherServlet.class, WebMvcConfigurer.class})
@ConditionalOnMissingBean({WebMvcConfigurationSupport.class})
@AutoConfigureOrder(-2147483638)
@ImportRuntimeHints({WebResourcesRuntimeHints.class})
public class WebMvcAutoConfiguration {
...
}우선 org.springframework.boot.autoconfigure.web.servlet 패키지에서 자동 구성 설정을 보니 Conditional을 통해 리플렉션 처리하는 것을 알 수 있습니다. 그래서 WebMvcConfigurationSupport를 한 번 확인해봤습니다.
protected final void addDefaultHttpMessageConverters(List<HttpMessageConverter<?>> messageConverters) {
messageConverters.add(new ByteArrayHttpMessageConverter());
messageConverters.add(new StringHttpMessageConverter());
messageConverters.add(new ResourceHttpMessageConverter());
messageConverters.add(new ResourceRegionHttpMessageConverter());
messageConverters.add(new AllEncompassingFormHttpMessageConverter());
...
}기본적으로 Web MVC에서 제공하는 모든 Converter를 다 제공하는 것을 확인 할 수 있었습니다. 이를 바탕으로 우선, byte로 excel file을 반환하도록 구현해봤습니다.
테스트를 위한 테스트 객체 생성
@Entity
@Getter
@NoArgsConstructor(access = AccessLevel.PROTECTED)
public class TestEntity {
private static final Random RANDOM = new Random();
@Id
@GeneratedValue(strategy = GenerationType.IDENTITY)
private Long id;
private String name;
private int count;
private double price;
private boolean isActive;
private LocalDateTime date;
private LocalDate birthDate;
private BigDecimal amount;
private Integer score;
public TestEntity(String name) {
this.name = name;
this.count = RANDOM.nextInt(10000);
this.price = RANDOM.nextDouble() * 1000;
this.isActive = RANDOM.nextBoolean();
this.date = LocalDateTime.now().minusDays(RANDOM.nextInt(365));
this.birthDate = LocalDate.now().minusYears(20 + RANDOM.nextInt(50));
this.amount = BigDecimal.valueOf(RANDOM.nextDouble() * 9999)
.setScale(2, RoundingMode.HALF_UP);
this.score = RANDOM.nextBoolean() ? RANDOM.nextInt(100) : null;
}
}다양한 자료형이 엑셀 파일에 제대로 저장되는지 확인하기 위해 여러 자료형을 field로 선언했습니다. 그리고 랜덤한 데이터로 객체를 채워 넣도록 했습니다.
@RestController
@RequestMapping("/examples")
@RequiredArgsConstructor
public class ExampleExcelController {
private final TestRepository testRepository;
@PostConstruct
@Transactional
void test() {
List<TestEntity> testEntities = new ArrayList<>();
for (int i = 1; i <= 10000; i++) {
testEntities.add(new TestEntity("테스트" + i));
}
testRepository.saveAll(testEntities);
}
}컨트롤러에서는 초기에 1000개의 랜덤 테스트 데이터를 삽입합니다.
이제 한 번 엑셀 파일로 다운로드 받아보겠습니다.
ByteArrayHttpMessageConverter로 구현
@Component
public class ExcelGenerator {
public byte[] createByteExcel(
List<String> headers,
List<List<Object>> dataRows
) throws IOException {
try (Workbook workbook = new XSSFWorkbook();
ByteArrayOutputStream outputStream = new ByteArrayOutputStream()) {
Sheet sheet = workbook.createSheet();
// 헤더 생성
Row headerRow = sheet.createRow(0);
for (int i = 0; i < headers.size(); i++) {
Cell cell = headerRow.createCell(i);
cell.setCellValue(headers.get(i));
}
// 데이터 생성
for (int rowIndex = 0; rowIndex < dataRows.size(); rowIndex++) {
Row dataRow = sheet.createRow(rowIndex + 1);
List<Object> rowData = dataRows.get(rowIndex);
for (int colIndex = 0; colIndex < rowData.size(); colIndex++) {
Cell cell = dataRow.createCell(colIndex);
Object value = rowData.get(colIndex);
if (value != null) {
if (value instanceof BigDecimal) {
cell.setCellValue(value.toString());
} else if (value instanceof Number) {
cell.setCellValue(((Number)value).doubleValue());
} else {
cell.setCellValue(value.toString());
}
}
}
}
workbook.write(outputStream);
return outputStream.toByteArray();
}
}
}POI에 대한 자세한 설명은 다른 곳에서 많이 소개 되므로 작성하지 않겠습니다. ExcelGenerator는 POI 기술을 활용해 가볍게 구현해봤습니다.
@GetMapping("/excel/bytes")
public ResponseEntity<byte[]> downloadExcelAsBytes(
@RequestParam(defaultValue = "1000") int limit,
HttpServletResponse response
) throws IOException {
List<String> headers = generateExcelFields();
List<TestEntity> entities = findAllEntities(limit);
List<List<Object>> dataRows = convertRowsFromEntities(entities);
byte[] excelBytes = excelGenerator.createByteExcel(headers, dataRows);
String fileName = "test-data-bytes-" + entities.size() + "rows.xlsx";
response.setHeader("Content-Disposition", "attachment; filename=\"" + fileName + "\"");
response.setHeader("Content-Type", "application/vnd.openxmlformats-officedocument.spreadsheetml.sheet");
return ResponseEntity.ok(excelBytes);
}그리고 컨트롤러에서는 Content-Disposition 옵션을 통해 web browser에게 명확히 첨부파일임을 알려주고 Content-Type 또한 명확히 엑셀 파일임을 명시합니다.
해당 부분은 파일에 확장자를 명확히 작성했다면 Content Type을 Octet-Stream으로 처리해도 되지만, Excel to DB의 작업이 추가될 수도 있으니 서버에서 검증을 위해 명확히 처리해줍시다.
해당 방식의 문제점
Byte 기반 Excel 파일 생성은 큰 문제점이 있었습니다.
기획 측에서한 sheet에 모든 데이터를 출력해주세요!라고 요구한 바가 있습니다. 해당 방식은 요구사항을 충족하기에 너무 많은 메모리를 차지합니다.
실제 문제점을 확인하기 위해 간단한 모니터링 도구를 작성해 Byte 기반 Excel File Downloader의 메모리 상태를 추적해봤습니다. 현재 Boot는-Xmx256m -Xms128m 설정을 통해 힙 메모리 제한이 있습니다.
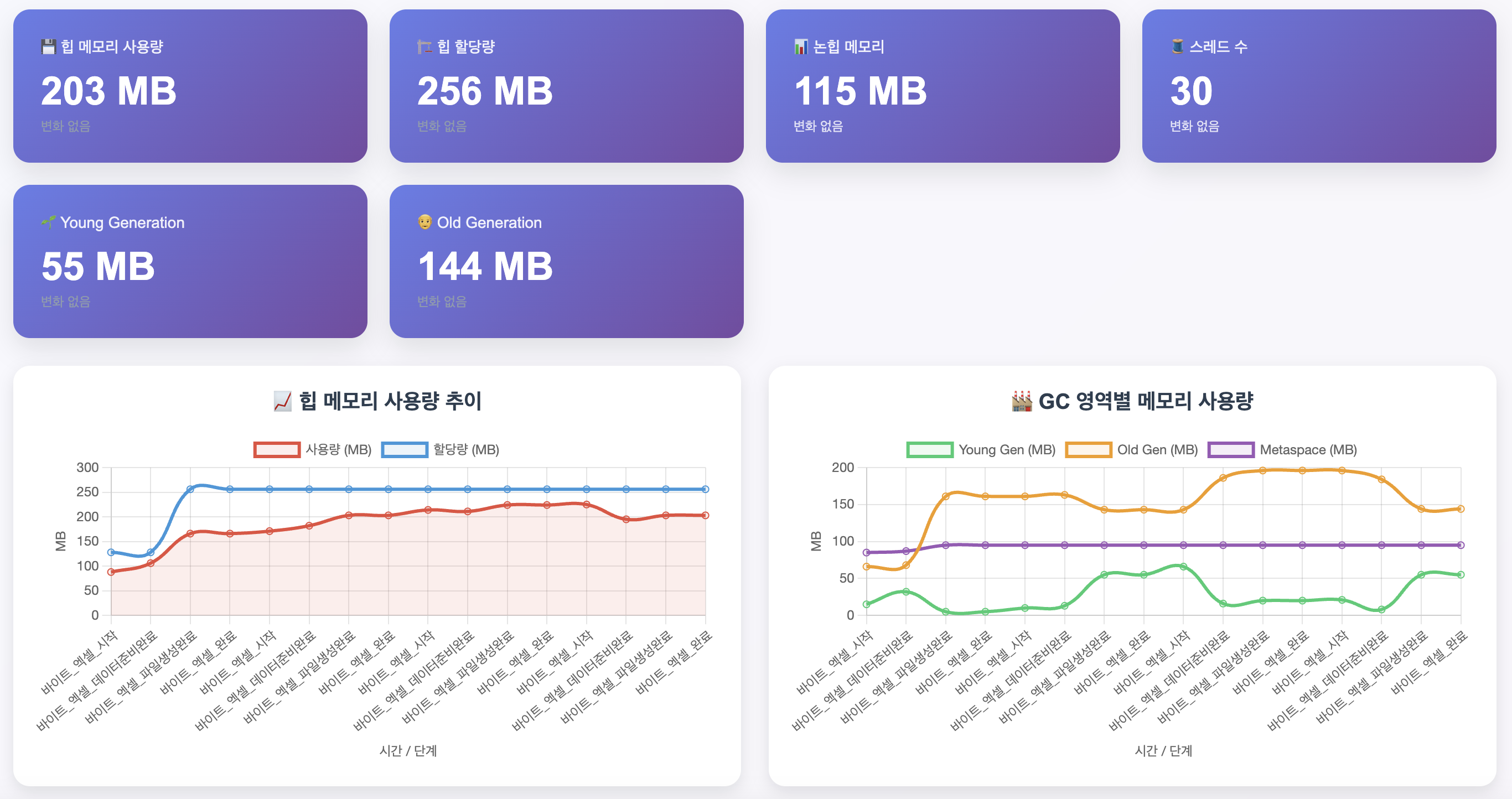
엑셀 파일을 다운로드 요청을 여러번 한 결과, 그림과 같이 메모리 사용량이 너무 많아진 것을 확인할 수 있습니다. 특히 Old Gen이 쌓이면서 Major GC가 발생하고 있습니다. Major GC는 처리 속도가 느리므로 자주 발생할수록 모놀리식 아키텍처에서는 전체적으로 성능 저하의 원인이 됩니다.
2025-06-08 11:53:15.644 [http-nio-8080-exec-4] INFO c.e.g.d.e.service.HttpTestService - 🌐 HTTP 테스트 완료: GET http://localhost:8080/examples/excel/bytes?limit=10000 (응답시간: 1413ms, 상태: 200 OK)
실행시간을 확인해보니 약 1.4s가 걸렸네요.
이것이 우리 서비스에 어떤 부가적인 문제점을 초래하는가?
현재 모놀리식 아키텍처로 서비스를 제작하면서 사용자 API와 관리자 API가 같이 제공되고 있습니다. 특히, 사용자들은 챌린지를 인증하면서 빠르게 데이터가 쌓이게 될 것입니다.
관리자는 서버의 구현 상태를 명확히 모르므로 다운로드 중 아래와 같은 오류로 서버가 종료될 수 있습니다.

실제로, 데이터를 10만개로 바꾸고 테스트 해 본 결과 바로 OOM이 발생했습니다.
Connected Stream으로 구현
// repository
public interface TestRepository extends JpaRepository<TestEntity, Long> {
@Query("SELECT t FROM TestEntity t")
Stream<TestEntity> findAllStream();
}// controller
@GetMapping("/excel/connected-stream")
@Transactional(readOnly = true)
public void downloadExcelAsStream(
@RequestParam(defaultValue = "1000") int limit,
HttpServletResponse response
) throws IOException {
List<String> headers = generateExcelFields();
Stream<TestEntity> streams = testRepository.findAllStream().limit(limit);
Stream<List<Object>> convertedStreams = streams.map(this::entityToRow);
response.setContentType("application/vnd.openxmlformats-officedocument.spreadsheetml.sheet");
response.setHeader("Content-Disposition",
"attachment; filename=\"test-data-stream-" + limit + "rows.xlsx\"");
excelGenerator.createStreamExcel(headers, convertedStreams, response.getOutputStream());
}// excel
public void createStreamExcel(
List<String> headers,
Stream<List<Object>> dataRows,
OutputStream stream
) throws IOException {
try (SXSSFWorkbook workbook = new SXSSFWorkbook(500)) {
Sheet sheet = workbook.createSheet();
// 헤더 생성
...
// 데이터 생성
AtomicInteger rowIndex = new AtomicInteger(1);
dataRows.forEach(rowData -> {
Row dataRow = sheet.createRow(rowIndex.getAndIncrement());
for (int colIndex = 0; colIndex < rowData.size(); colIndex++) {
// setValue ...
}
});
workbook.write(stream);
}
}Apache POI에서 제공하는 SXSSFWorkbook 객체를 동해 Stream 기반으로 엑셀 파일을 생성할 수 있습니다.
JPA에서 부터 Stream으로 연결하면서 1000행씩만 파일을 생성하도록 했습니다. https://andriymz.github.io/misc/apache-poi-slow-excel-generation
해당 블로그에서 window size가 실행속도에 큰 차이가 없었다는 실험 결과를 확인했습니다. 그럼, window Size는 I/O Bound와 밀접한 연관성보다는 minor gc와 연관성이 있다는 것을 확인했고 모니터링을 통해 500행이 적정하다 판단하고 선택했습니다.
byte의 문제점 해결
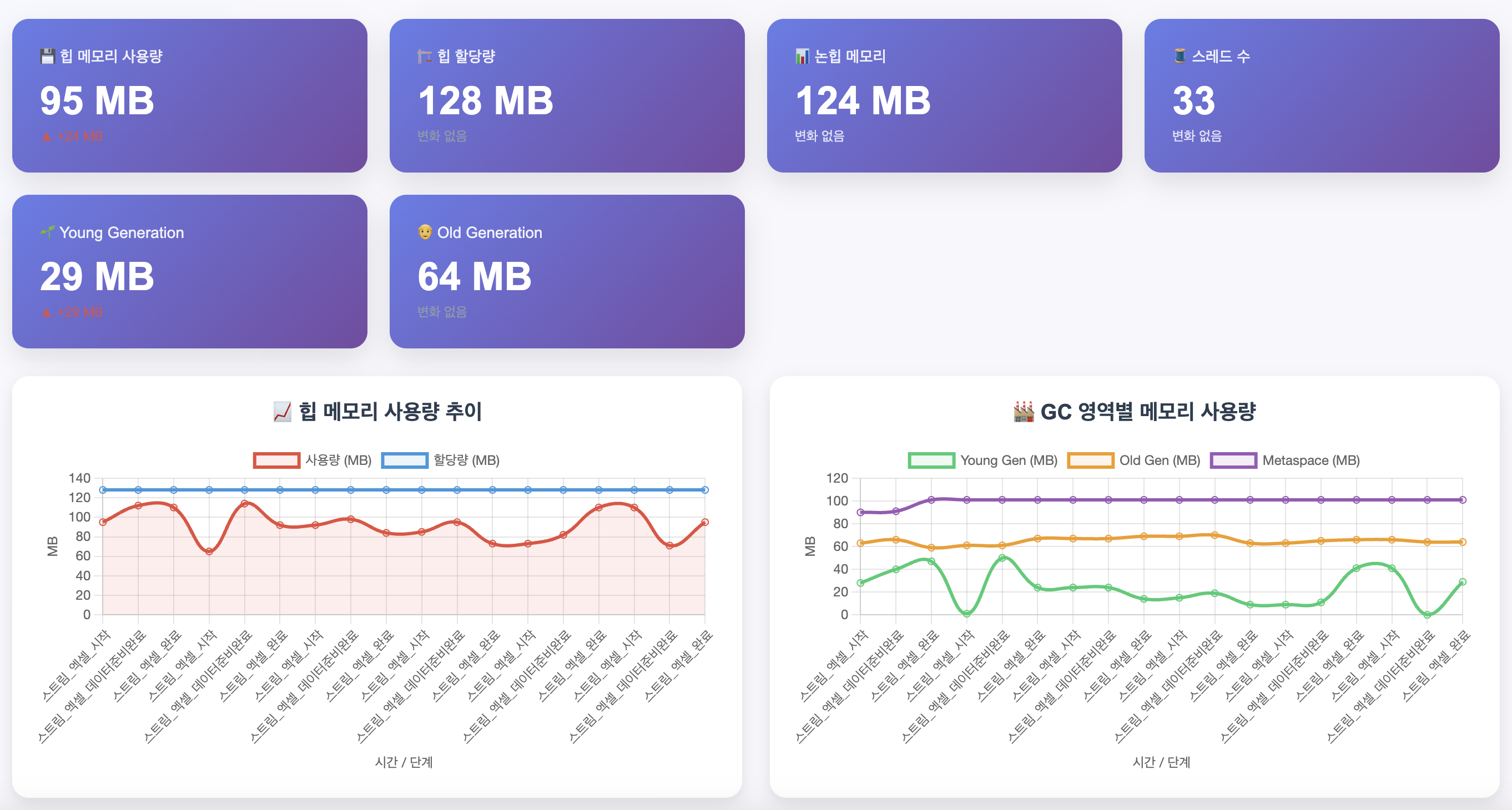
10000행에 대해 여러번 호출했음에도 불구하고 Major GC는 거의 발생하지 않고 Minor GC로 효율적으로 처리되는 것을 확인할 수 있었습니다.
2025-06-08 11:59:43.104 [http-nio-8080-exec-6] INFO c.e.g.d.e.service.HttpTestService - 🌐 HTTP 테스트 완료: GET http://localhost:8080/examples/excel/connected-stream?limit=10000 (응답시간: 275ms, 상태: 200 OK)
약, 1만건의 데이터는 275ms가 소요됐네요. 1만건의 row에서 byte 방식보다 약 6배의 성능 향상을 보였습니다.
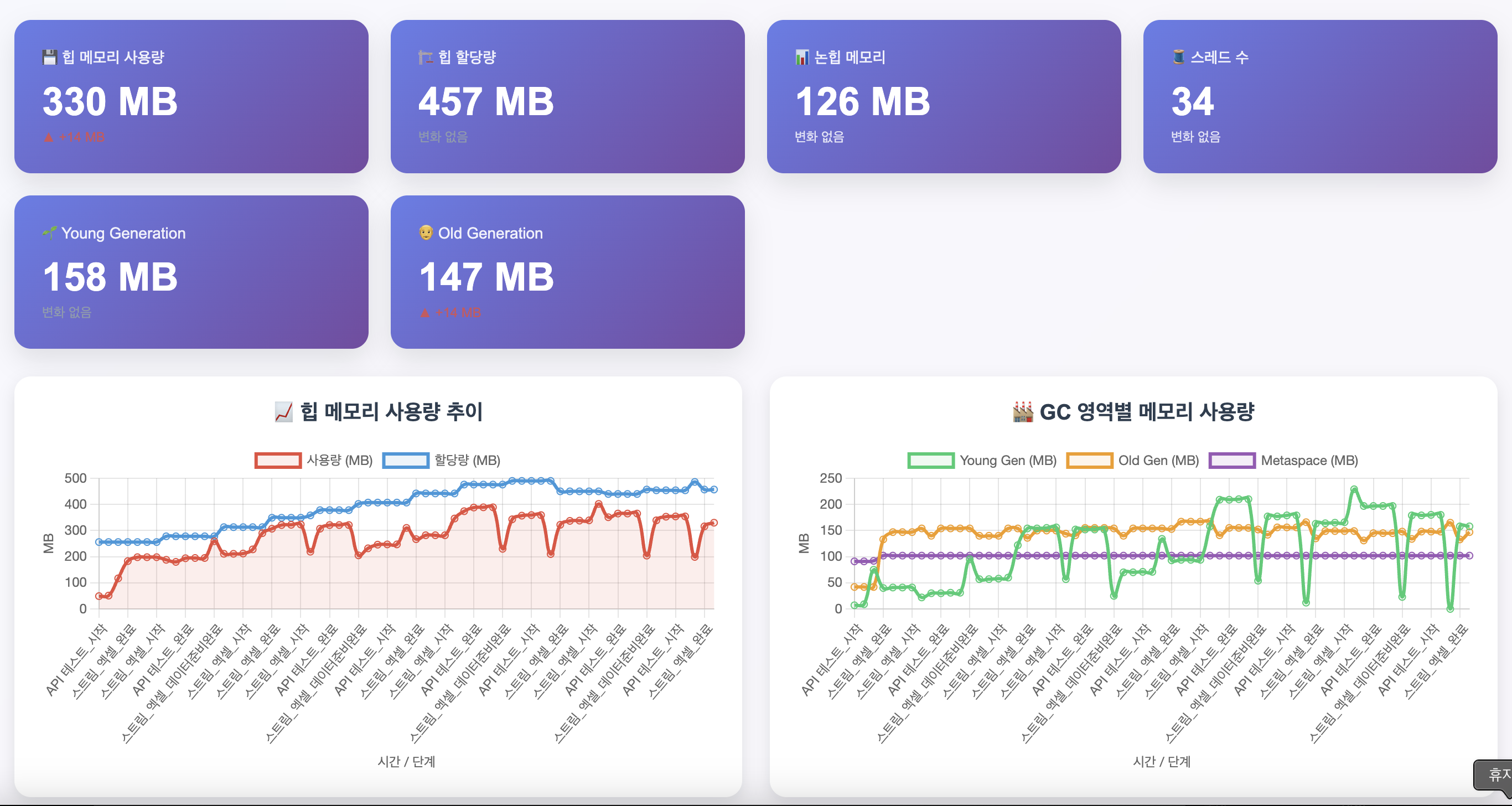
최소, 최대 힙 할당량을 2배로 늘린 뒤 10만건의 데이터에서 확인했을 때도 잘 처리가 되고 있는 것을 볼 수 있습니다.
2025-06-08 16:04:08.564 [http-nio-8080-exec-2] INFO c.e.g.d.e.service.HttpTestService - 🌐 HTTP 테스트 완료: GET http://localhost:8080/examples/excel/connected-stream?limit=100000 (응답시간: 1893ms, 상태: 200 OK)
`
10만건의 데이터에서는 약 1.9s가 소요되는 것을 확인했습니다.
해당 방식의 문제점
10만건의 데이터를 여러번 동시에 조회한 결과 아래와 같은 오류가 발생했습니다.
2025-06-08 15:50:00.302 [http-nio-8080-exec-10] ERROR o.a.c.c.C.[.[.[.[dispatcherServlet] - Servlet.service() for servlet [dispatcherServlet] in context with path [] threw exception [Handler dispatch failed: java.lang.OutOfMemoryError: Java heap space] with root cause
java.lang.OutOfMemoryError: Java heap space
...GC가 발생하기 전에 연결된 Stream이 모두 메모리에 상주하면서 OOM이 발생하는 것입니다.
Detached Stream 으로 구현
public void createStreamExcel(
List<String> headers,
List<List<Object>> dataRows,
OutputStream stream
) throws IOException {
try (Workbook workbook = new SXSSFWorkbook(500)) {
Sheet sheet = workbook.createSheet();
// 헤더 생성
...
// 데이터 생성
for (int rowIndex = 0; rowIndex < dataRows.size(); rowIndex++) {
Row dataRow = sheet.createRow(rowIndex + 1);
List<Object> rowData = dataRows.get(rowIndex);
for (int colIndex = 0; colIndex < rowData.size(); colIndex++) {
// setValue ...
}
}
workbook.write(stream);
}
}
@GetMapping("/excel/detached-stream")
public void downloadExcelAsStream(
@RequestParam(defaultValue = "1000") int limit,
HttpServletResponse response
) throws IOException {
List<String> headers = generateExcelFields();
List<TestEntity> entities = findAllEntities(limit);
List<List<Object>> dataRows = convertRowsFromEntities(entities);
// 파일명에 레코드 수 포함
response.setContentType("application/vnd.openxmlformats-officedocument.spreadsheetml.sheet");
response.setHeader("Content-Disposition",
"attachment; filename=\"test-data-stream-" + entities.size() + "rows.xlsx\"");
excelGenerator.createStreamExcel(headers, dataRows, response.getOutputStream());
}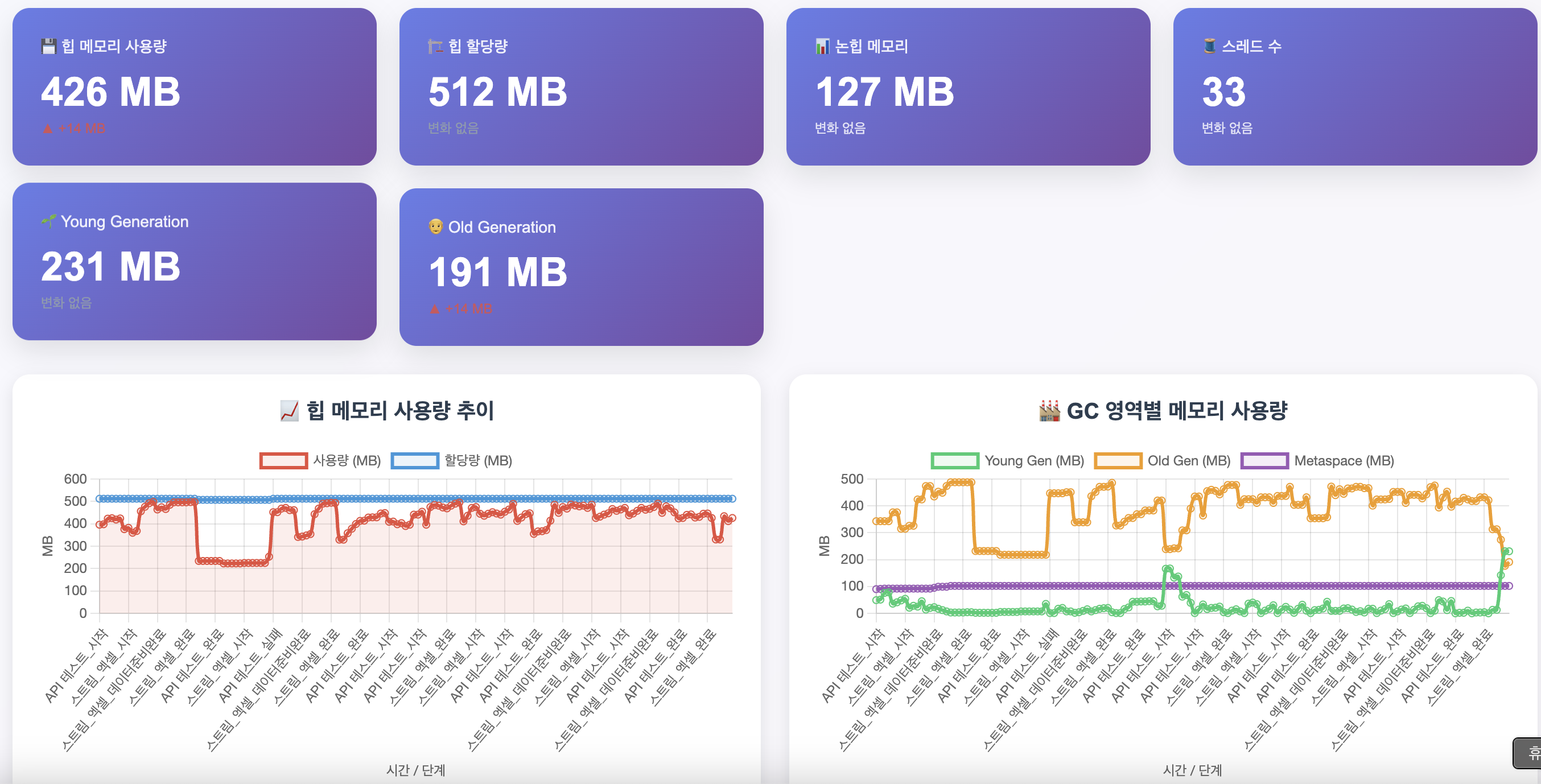
Stream 대신 List 객체를 받도록 수정후 여러번 API를 요청한 결과, 최대 Heap 할당량에서 OOM이 발생하지 않고 Major GC가 발생하면서 안정적으로 처리할 수 있습니다.
2025-06-08 16:04:54.066 [http-nio-8080-exec-7] INFO c.e.g.d.e.service.HttpTestService - 🌐 HTTP 테스트 완료: GET http://localhost:8080/examples/excel/detached-stream?limit=100000 (응답시간: 1752ms, 상태: 200 OK)
응답 처리 속도도 Connected Stream 방식보다 약 100ms 성능 향상을 보였습니다.
구현 방식의 결과 비교
각 구현 방식에서 왜 다양한 문제가 발생하고 어떻게 성능이 개선된건지 그림과 함께 이해해보도록 하겠습니다.
Byte vs Stream
Byte 방식과 Stream 방식은 마치 물을 퍼나르는 장면이 떠오릅니다.
Byte 방식
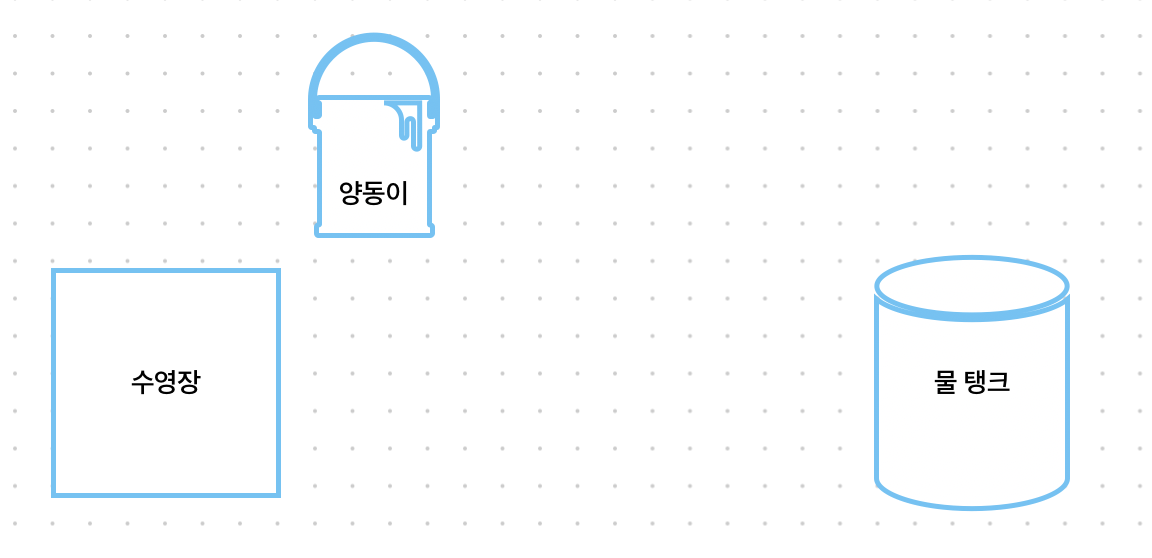
우선 byte 방식에서 클라이언트: 수영장, 서버의 자원: 양동이, DB: 물 탱크로 생각해보겠습니다.
byte 방식은 마치 양동이로 퍼나르는 것과 유사합니다. 양동이 크기 제한이 있으면 어떻게 될까요? 물 탱크에서 물을 퍼나르더라도 넘쳐흐르게 될 것 입니다. 이것이 OOM이 발생하는 원인입니다.
Stream 방식

반면 Stream 방식은 하나의 수도관이 생성되고 필요할 때 마다 수도 꼭지를 틀어 물을 받아오는 방식입니다. 즉, 한계가 없게 되는거죠.
시간 측면
Byte 방식은 사람이 직접 양동이에 물을 채우는 과정 + 물을 나르는 과정 때문에 시간이 오래 걸립니다. 반면, Stream 방식은 수도꼭지를 틀면 물이 채워지기 때문에 시간이 오래 걸리지 않습니다.
Connected Stream vs Detached Stream
Byte vs Connected Stream 에서는 많은 부분을 생략해서 이미지를 그렸습니다.조금 더 명확히 표현해 Connected Stream 과 Detached Stream 의 차이를 알아보겠습니다.
수영장 = Client, 정화소 = 스레드,
수영장 전용 물탱크 = 영속성 컨텍스트, 전체 물탱크 = DB
Connected Stream
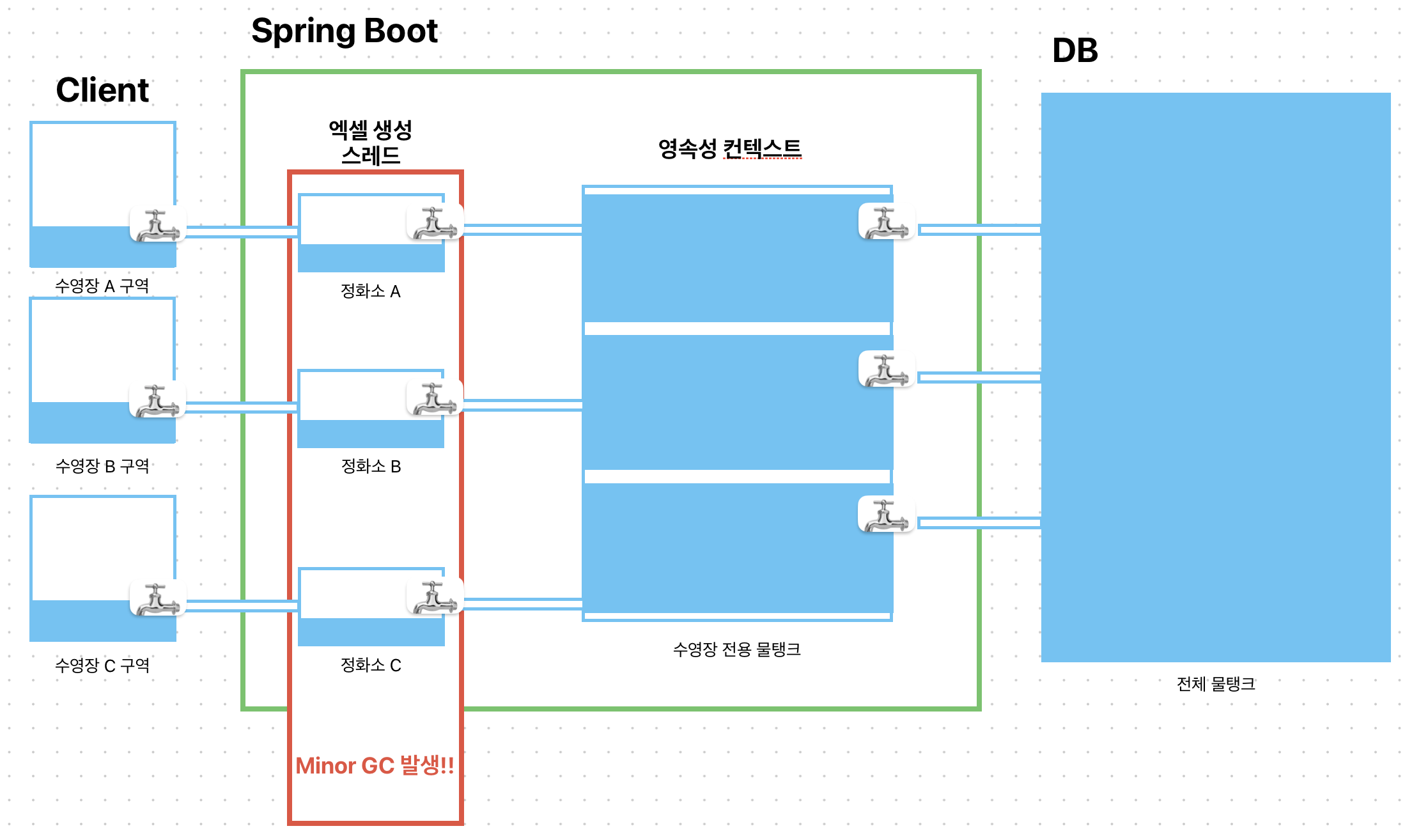
보이는 이미지와 같이 connected-stream 방식의 치명적인 문제가 있습니다. Jpa 영속성 컨텍스트는 1차 캐시에 DB에서 가져온 데이터를 먼저 저장합니다! 이것을 수영장 전용 물탱크의 각 공간으로 표현했습니다.
각 수영장에서 물을 채워달라는 요청이 올 때마다 전체 물탱크에서 수영장 전용 물탱크에 물을 받게 됩니다. 그리고 각 수영장 별로 정화소에서 수영장 전용 물탱크에서 받아온 물을 정화하고 수영장에 물을 채우게 됩니다. 이것이 엑셀 파일을 500행 만들 때마다 Stream에 데이터를 전달하는 것으로 이해할 수 있습니다.
그 과정에서 정화소에 채워진 물을 비우며 다시 수영장 전용 물탱크에서 받고 이 과정을 반복합니다. 이 때, 정화소를 비우는 과정이 Minor GC가 발생하는 과정입니다.
🤔 ⁇ "그럼 이게 어떻게 OOM이 발생할까요?"
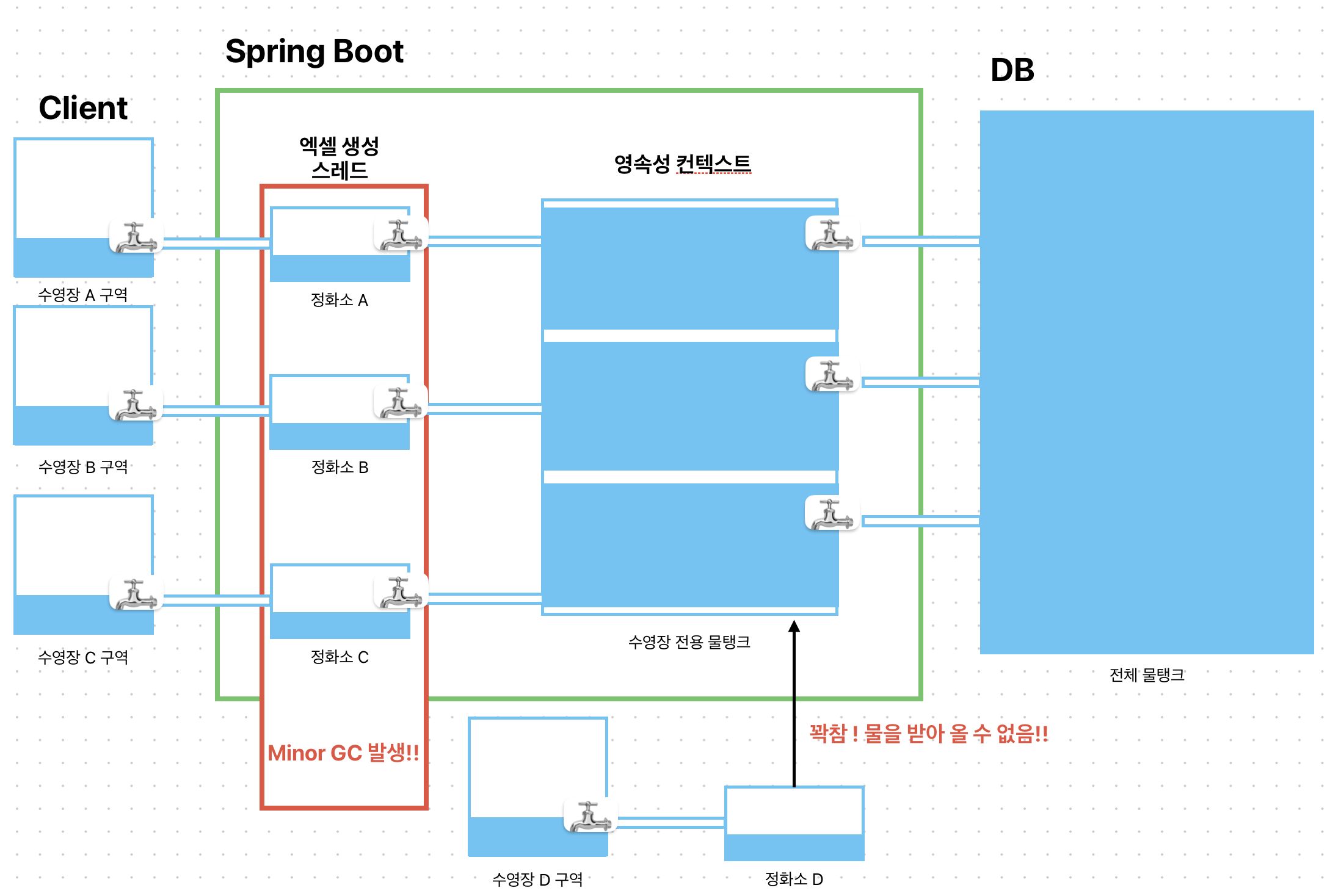
Connected Stream으로 연결되어있기 때문에 ScrollableResults와 JDBC 연결이 유지되면서 Transaction이 끝날 때까지 영속성 컨텍스트의 메모리 해제가 불가능한 상태입니다.
그럼 새로운 수영장 구역에서 물을 채워달라고 요구 할 때, 수영장 전용 물탱크(영속성 컨텍스트)가 이미 포화 상태이므로 OOM이 발생하게 됩니다.
Detached Stream
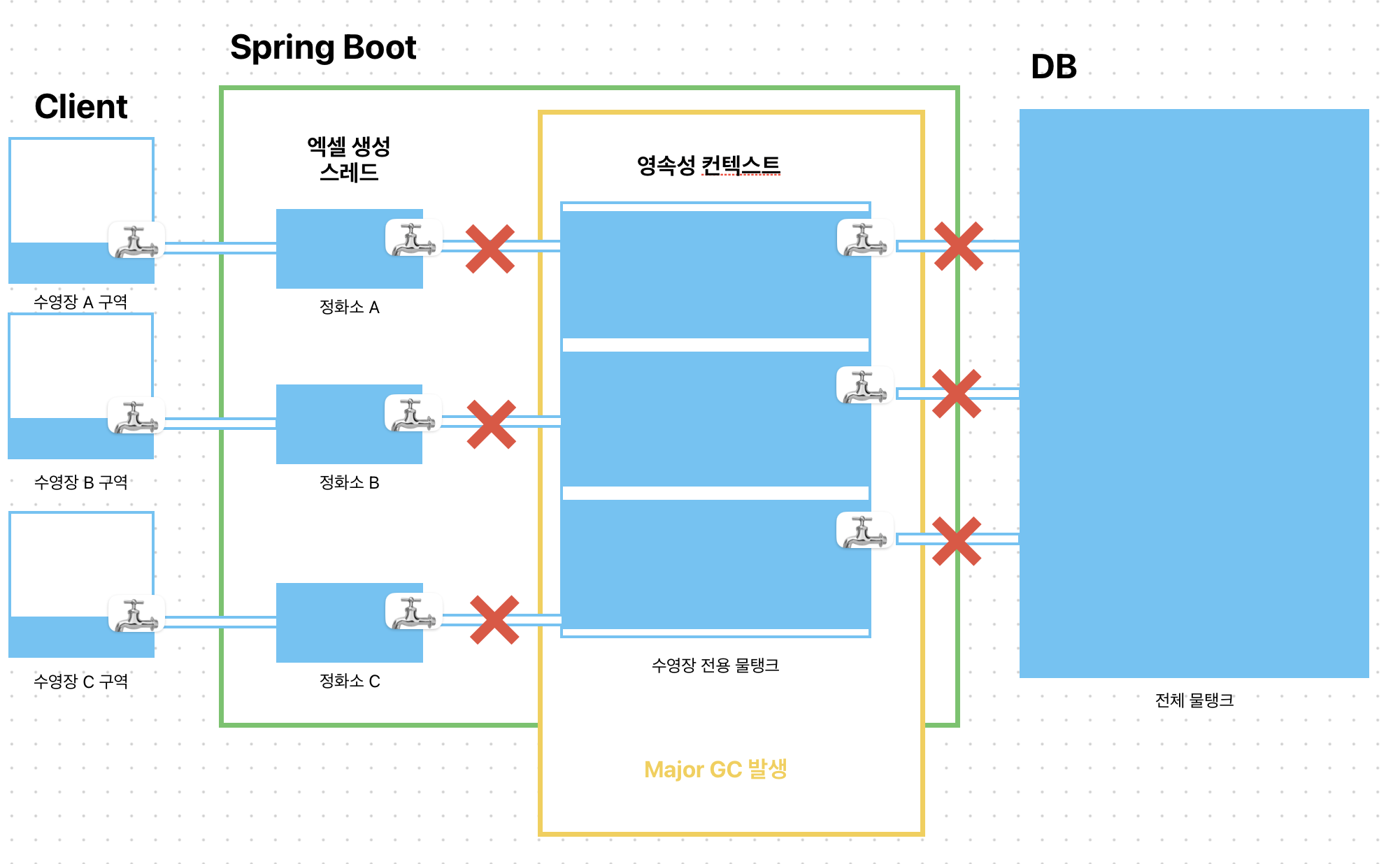
반면 Detached Stream 조회의 경우, 스레드에서 필요한 데이터를 가져오면서 Transaction Connection이 끊기면서 메모리 해제가 가능한 상태가 됩니다.
그럼, 영속성 컨텍스트의 1차 캐시에 있던 정보는 Old Generation으로 이동하게 되고 Major GC에 의해 비워지게 됩니다.
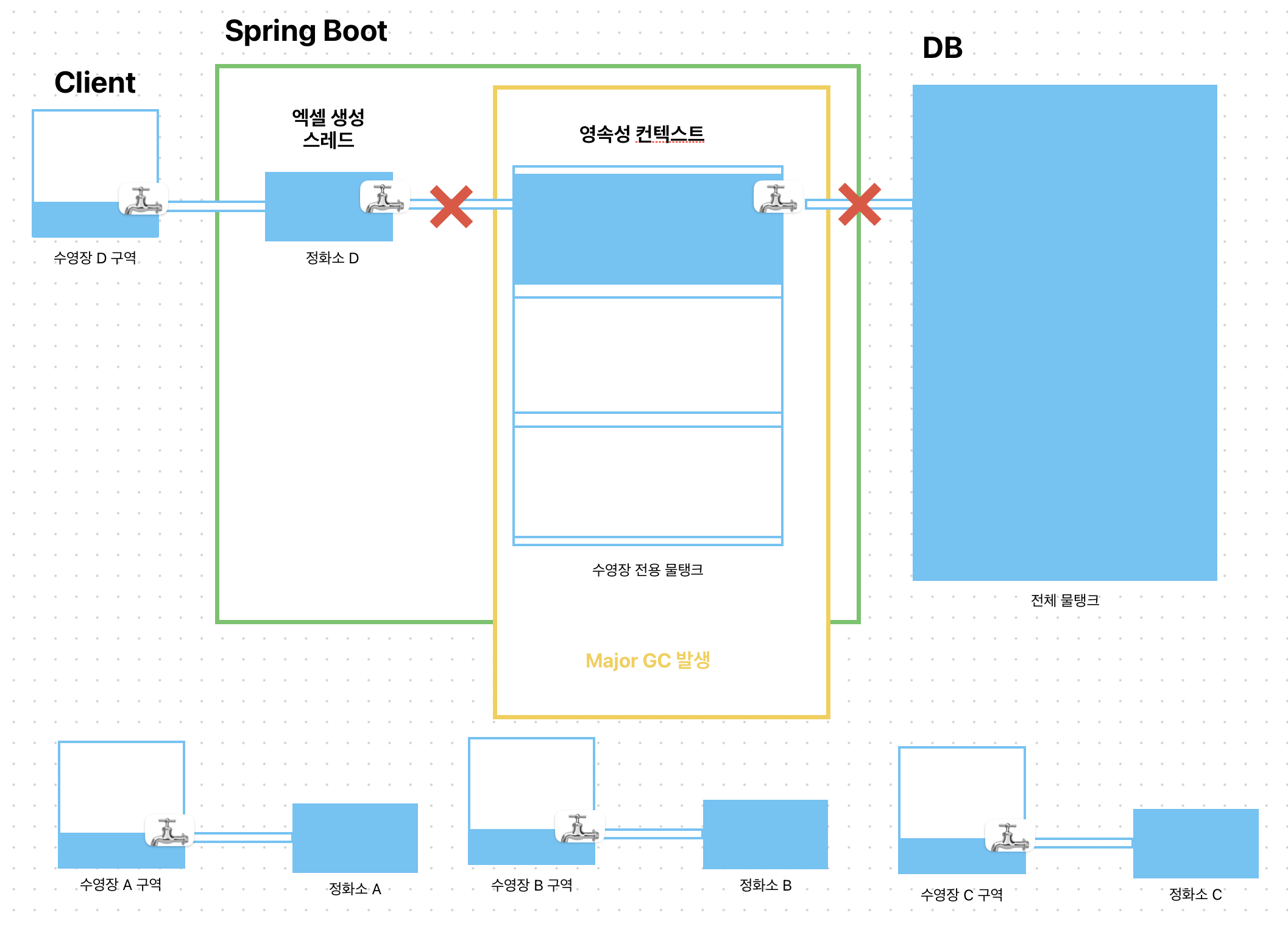
그럼 새로운 수영장 구역에 물을 채워달라는 요청이 와도 수영장 전용 물탱크가 비워져 있으므로 새로 물을 채울 수 있게 되면서 OOM이 발생하지 않게 됩니다.
Stream의 오해와 진실
사실, Stream이 성능면에서 뛰어나다는 말도 있고 뛰어나지 않다는 말도 있습니다.
현재까지의 정보가 이 두가지를 모두 보여주는 사례라고 생각됩니다.
생각해보면 Connected Stream 방식은 이론 상 성능이 더 우수해야되는데, Detached Stream에서 Collection으로 조회하면서 성능이 100ms 정도 낮았던 것을 직접 관측했습니다.
그 이유는 Minor GC가 많이 발생해서 그런데 Minor GC 수십번 vs Major GC 1번에서 성능 차이가 발생한 것입니다.
Yong Generation 메모리가 충분하게 설정되지 않았다면 모든 정보를 Stream으로 처리하는 것은 오히려 성능 저하가 발생할 수 있습니다.
추상화
엑셀 생성 파일은 관리자 컨텍스트에서 여러 컨텍스트의 정보를 다운로드하기 위한 기능입니다. 즉, 공통 모듈인데 팀원 간 어떻게 하면 일관되게 처리할 수 있도록 추상화 할 수 있을까 고민을 해봤습니다.
* 엑셀 데이터 매핑을 위한 공통 인터페이스
* 각 도메인에서 이 인터페이스를 구현하여 자신만의 엑셀 포맷을 정의할 수 있습니다.
*
* @param <T> 엑셀로 변환할 데이터 타입
*/
public interface ExcelDataMapper<T> {
/**
* @return 생성할 엑셀 파일명
*/
String getFileName();
/**
* 이 Mapper가 처리할 데이터 타입을 반환합니다.
* Registry에서 적절한 Mapper를 찾기 위해 사용됩니다.
*
* @return 처리할 데이터 타입의 Class 객체
*/
Class<T> getDataType();
/**
* 엑셀 헤더에 사용될 필드 정보들을 반환합니다.
* 필드 순서가 엑셀 컬럼 순서가 됩니다.
*
* @return 엑셀 필드 정보 리스트 (순서 보장 필요)
*/
List<ExcelField> getFields();
/**
* 하나의 데이터 객체에서 엑셀 행 데이터를 추출합니다.
* 반환되는 배열의 순서는 getFields()와 일치해야 합니다.
*
* @param data 엑셀로 변환할 데이터 객체
* @return 엑셀 행 데이터 배열 (getFields() 순서와 일치)
*/
Object[] extractRowData(T data);
/**
* 엑셀 시트명을 반환합니다.
* 기본 구현은 "Sheet1"을 사용하며, 필요에 따라 오버라이드 가능합니다.
*
* @return 엑셀 시트명
*/
default String getSheetName() {
return "Sheet1";
}
}Mapper를 통해 어떤 정보로 다운로드 할 지 각 팀원이 작성만 하면 됩니다.
@Component
@Slf4j
public class ExcelDataMapperRegistry {
private final Map<Class<?>, ExcelDataMapper<?>> mapperMap = new ConcurrentHashMap<>();
public ExcelDataMapperRegistry(List<ExcelDataMapper<?>> mappers) {
for (ExcelDataMapper<?> mapper : mappers) {
Class<?> dataType = mapper.getDataType();
checkDuplicateMapper(mapper, dataType);
mapperMap.put(dataType, mapper);
log.info("ExcelDataMapper 등록 완료: {} -> {}",
dataType.getSimpleName(),
mapper.getClass().getSimpleName());
}
}
...
}그럼 Spring DI에 의해 모든 Mapper를 수집할 수 있습니다.
@Component
@RequiredArgsConstructor
@Slf4j
public class SXSSFExcelDownloader implements ExcelDownloader { // @checkstyle:ignore
private static final String DISPOSITION_FORMAT = "attachment; filename=\"%s.%s\"";
private static final String EXCEL_FILE_EXTENSION = "xlsx";
private static final int WINDOW_SIZE = 100;
private final ExcelDataMapperRegistry registry;
@Override
public <T> void downloadAsStream(List<T> dataList, HttpServletResponse httpServletResponse) {
if (dataList.isEmpty()) {
throw new ExcelException(ExcelExceptionMessage.EMPTY_DATA);
}
@SuppressWarnings("unchecked") Class<T> dataType = (Class<T>)dataList.getFirst().getClass();
ExcelDataMapper<T> mapper = registry.getMapper(dataType);
setupExcelResponse(httpServletResponse, mapper.getFileName());
try {
downloadAsStream(dataList, mapper, httpServletResponse.getOutputStream());
} catch (IOException e) {
log.error("엑셀 파일 생성 중 오류 발생: 데이터 타입={}", mapper.getDataType().getSimpleName(), e);
throw new ExcelException(ExcelExceptionMessage.EXCEL_GENERATION_FAILED);
}
}
...
}그럼 SXSSF 엑셀 다운로더에서 Registry 정보로 부터 dataType과 동일한 매퍼를 가져와서 엑셀 파일로 다운로드를 진행합니다.
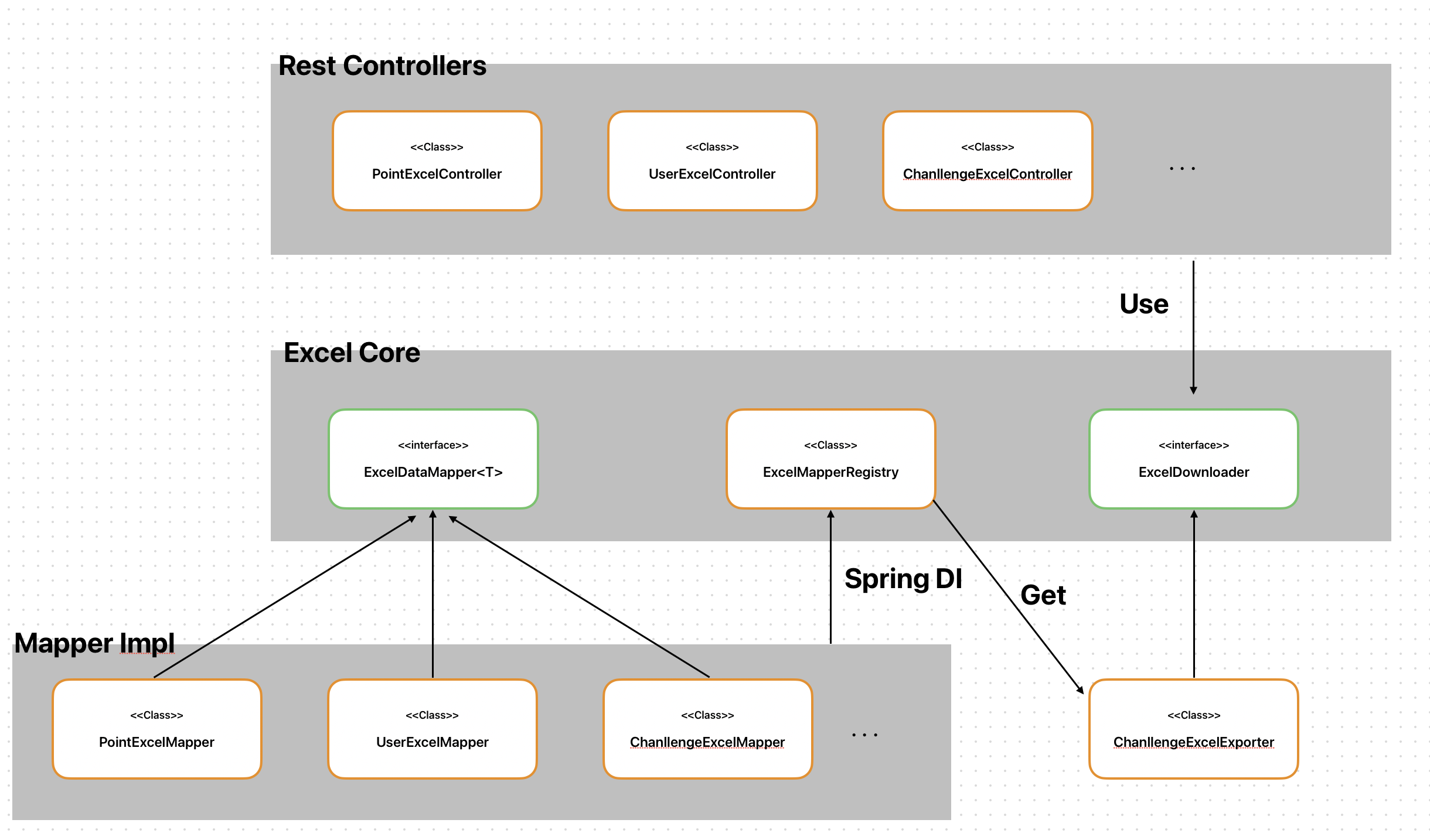
우아한 기술 블로그(https://techblog.woowahan.com/2698)에서 리플렉션을 활용한 방법을 소개하고 있었습니다. 저도 이것을 도입할까 고민했지만 어노테이션 메타 데이터가 너무 무거워 질 것 같아서 그냥 인터페이스 방식으로 구현했습니다.
예상한대로 결과는 잘 다운로드가 됐네요.
마치며
엑셀 다운로드라는 흔한 요구사항이었지만 막상 구현해보니 성능, 메모리, 팀 협업까지 고려해야 할 요소들이 정말 많았습니다.
🔍 이번 경험에서 얻은 교훈들
"일단 돌아가게" 만드는 것과 "제대로" 만드는 것의 차이
Byte 방식으로도 작은 데이터는 문제없이 처리됐지만, 실제 운영 환경에서는 OOM으로 서비스 전체가 다운될 수 있었습니다.
Stream이 항상 답은 아니다
Connected Stream이 이론적으로는 더 효율적이지만, JPA 영속성 컨텍스트와 GC의 동작 방식을 이해하지 못하면 오히려 독이 될 수 있다는 것을 깨달았습니다.
추상화의 적절한 수준
리플렉션 기반의 복잡한 구조보다는, 인터페이스 기반의 단순하지만 확장 가능한 구조가 팀 프로젝트에서는 더 효과적일 것으로 보입니다. Uncommon Case는 복잡하고 느려도 된다고 하지만, 처음부터 복잡할 필요가 있는가? 고민하게 됐습니다. YAGNI 원칙에 따라 리플렉션은 추후에 변경하는 방향으로 적용해봐야겠습니다 ㅎ
소감
무엇보다 "왜 이렇게 동작하는가?" 를 끝까지 파헤쳐보는 과정이 정말 즐거웠습니다. 단순해 보이는 기능 하나에도 이렇게 많은 학습 포인트가 숨어있다니, 개발의 재미를 다시 한번 느꼈습니다.
팀원들과 함께 이런 기술적 고민을 나누고, 더 나은 코드를 위해 고민하는 문화가 계속 이어지길 바랍니다. 🎯
