들어가기
DBT 는 데이터 가공 도구로 ETL에서 Transform에 더 초점을 맞춘 ELT 도구이다. DBT를 사용하는 방법으론 DBT Cloud, DBT CLI 2가지 방법이 있는데 DBT Cloud를 사용하기 위해서는 과금이 필요하다. DBT를 사용하는 사용자가 많아질 수록 선형적으로 과금이 증가하게 된다.
이에 무료로 DBT를 사용하기 위해서는 cli를 이용하여서 운영환경을 구축해주어야한다. DBT Cloud에서는 job기능이 있는데 이를 통해서 원하는 orchestrator을 구축할 수 있다.
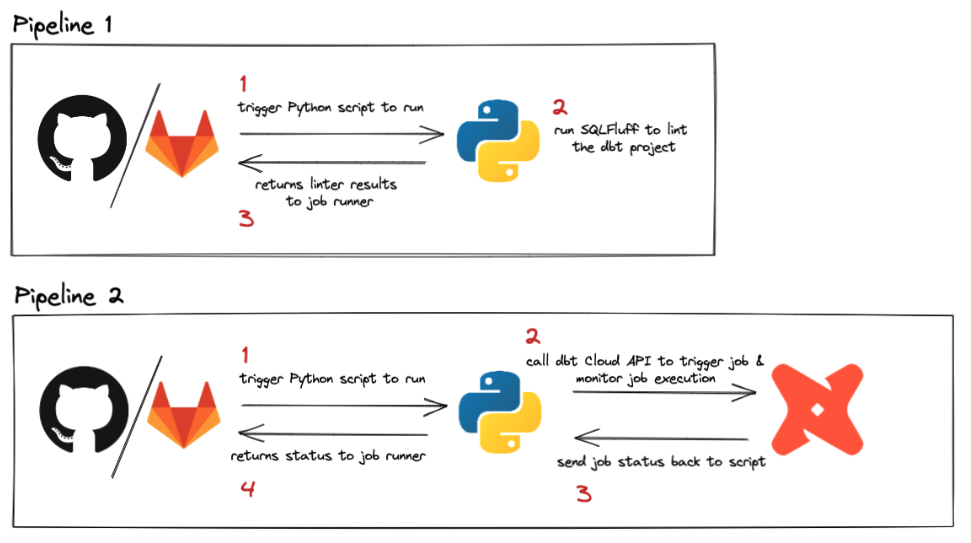
하지만 DBT CLI에서는 이 같은 기능을 사용할 수는 없기 때문에 따로 Orchestrator 을 구현해주어야 하는데 이에 Airflow를 이용할 수 있다.
DBT Cloud 에서도 이 Airflow를 활용할 수 있는데 아래와 같은 케이스에 사용하기 좋다.
- 팀내에서 이미 Airflow를 사용하고 있을 때.
- DBT Process를 돌리기 전에 DBT 외부 프로세스를 돌려야할 때.
- DBT Job간에 좀 더 복잡한 스케쥴링이 필요할 때.
위와 같은 이유로 실제 DBT with Airflow 인프라를 구축한 경험을 적어본다.
목표
- DA( Data Analyst ) 가 기획한 데이터 테이블을 Ingestion하는 자동화 파이프라인 구축
- 기존 Airflow 환경에 적용하기
- DBT 가이드라인을 작성하여 사용자의 허들 낮추기
- 데이터의 신뢰성 높이기.
소프트웨어 아키텍처
Software architecture
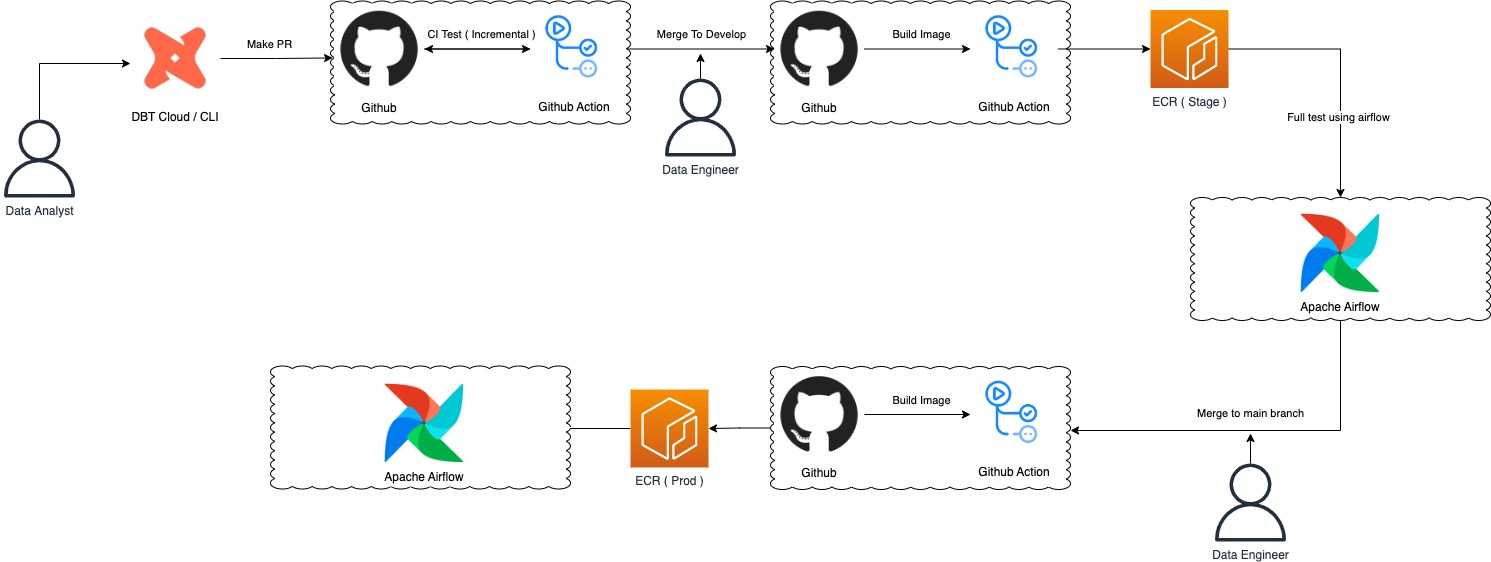
- DBT + Github + Airflow ( EKS ) 를 활용하여 Data abstraction pipeline을 구축.
- branch의 merge 과정에서 만 DE 가 개입하면 되도록 자동화 프로세스를 구성.
- DBT image 를 만들어서 이를 Airflow KubernetesPodOperator를 이용하여 서로의 환경설정에 구애받지 않고 운영할 수 있도록 구성.
- dbt 의 select flag를 이용한 lean test, stage 단계에서의 full test를 통한 solid한 데이터 상태 유지.
DA & DE user flow
Data Analyst (DA), Data engineer (DE)
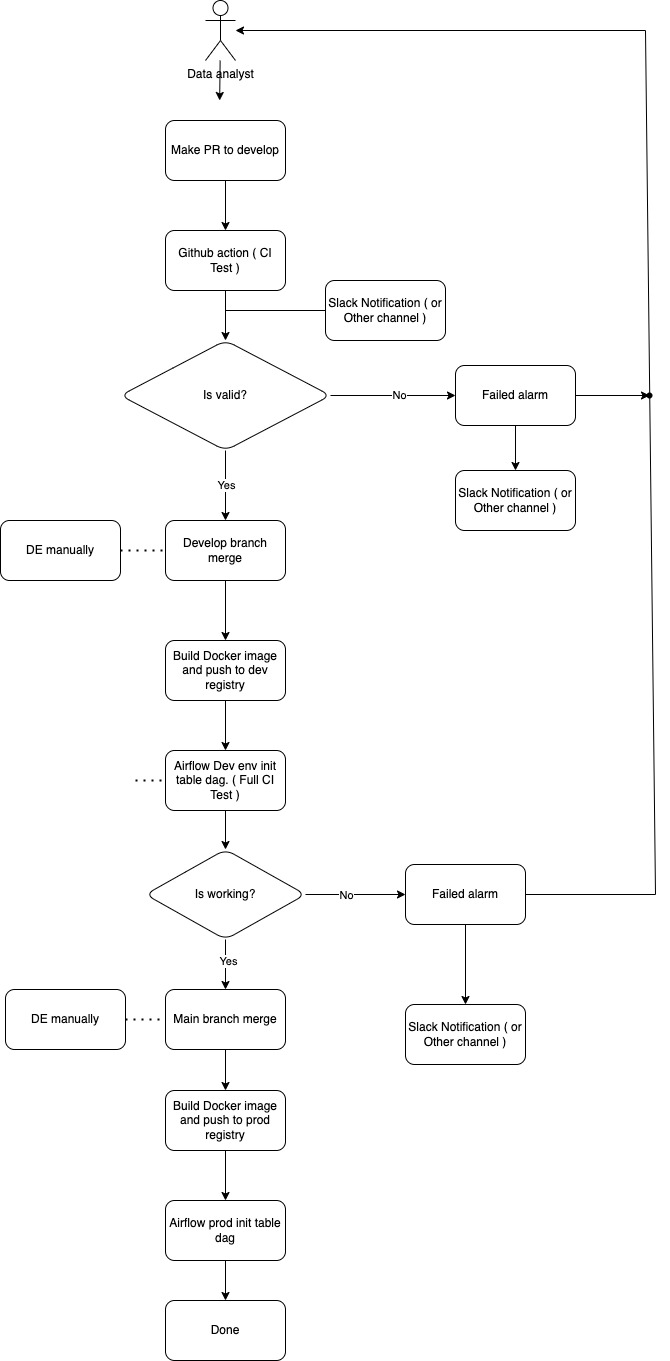
- DA가 기획한 테이블을 commit 하고 Develop branch에 Pull request ( PR )를 날린다.
- PR 이 생성되면 slack notification을 info 채널로 날린다.
- Github action 을 통해서 변경된 Model에 대해서만 dbt run, test를 진행한다.
- slim test 는 dbt profile의 dev를 target으로 하여 진행한다.
- dev 환경은 DA 가 자유롭게 사용할 수 있는 Playground
- Validation
- If success ) Develop branch에 머지할 수 있는 상태가 되고 정기적으로 Dev에 반영을 한다.
- if fail ) Slack notification이 발생하고 merge는 할 수 없게 된다.
- Develop branch에 merge가 되면 github action을 통해 docker image를 빌드하고 dev ecr에 push 한다. 그 후 airflow api 를 이용하여 full test를 진행하는 init dag을 실행한다.
- stage full test 의 target은 dbt profile의 stage.
- Airflow dev 환경에서 업데이트된 image를 이용하여 model, seed를 init 하는 dag을 돌립니다. 성공 및 실패에 대한 slack notification을 채널에 날립니다.
- init dag은 dbt streaming dag 이 running 하고 있지 않을 때만 돌아감. 반대로 streaming dag 도 동일. ( Airflow PythonSensor를 활용하여 구현 )
- Dev test 가 모두 성공했다면 main branch merge를 진행 dev 에서 진행했던 일련의 과정을 다시 진행한다.
- dbt profile target은 prod.
DBT
DBT Repository
TBD
DBT Profile
bigquery:
target: dev
outputs:
dev:
type: bigquery
method: service-account
project: "{{ env_var('GOOGLE_PROJECT_ID', '') }}"
dataset: "{{ env_var('GOOGLE_PROJECT_DATASET', '') }}"
threads: 1
location: US
job_creation_timeout_seconds: 30
job_execution_timeout_seconds: 600
job_retries: 5
job_retry_deadline_seconds: 1200
maximum_bytes_billed: 1000000000 # 1GB
scopes:
- https://www.googleapis.com/auth/bigquery
keyfile: "{{ env_var('GOOGLE_KEYFILE_PATH', '') }}"
stage:
type: bigquery
method: service-account
project: "{{ env_var('GOOGLE_PROJECT_ID', '') }}"
dataset: "{{ env_var('GOOGLE_PROJECT_DATASET', '') }}"
threads: 1
location: US
job_creation_timeout_seconds: 30
job_execution_timeout_seconds: 600
job_retries: 5
job_retry_deadline_seconds: 1200
maximum_bytes_billed: 1000000000 # 1GB
scopes:
- https://www.googleapis.com/auth/bigquery
keyfile: "{{ env_var('GOOGLE_KEYFILE_PATH', '') }}"
prod:
type: bigquery
method: service-account
project: "{{ env_var('GOOGLE_PROJECT_ID', '') }}"
dataset: "{{ env_var('GOOGLE_PROJECT_DATASET', '') }}"
threads: 1
location: US
job_creation_timeout_seconds: 30
job_execution_timeout_seconds: 600
job_retries: 5
job_retry_deadline_seconds: 1200
maximum_bytes_billed: 1000000000 # 1GB
scopes:
- https://www.googleapis.com/auth/bigquery
keyfile: "{{ env_var('GOOGLE_KEYFILE_PATH', '') }}"DBT Profile 환경은 3가지로 구분하였습니다.
Dev
DA분들이 자유롭게 사용할 수 있는 개발 환경으로 PR 에 대한 lean test 가 진행될 때 해당 target으로 배포가 진행되어서 기존의 데이터의 validation을 깨지 않는지 확인하는데 이용됩니다.
Stage
Stage는 실제 운영 단계로 올라가기전 전반적인 데이터에 대한 재구성 및 테스트를 진행합니다. 모든 dbt model에 대한 full test가 진행됩니다.
Prod
실제 운영 단계에서 사용되는 단계입니다.
Github action
CI/CD 에 사용될 툴은 가장 익숙한 github action을 활용했다. 많은 샘플 예제와 marketplace에 유저들이 미리 만들어놓은 action들을 사용하면 보다 빠르게 구축이 가능하다.
Check PR github action
name: Check PR
on:
pull_request:
branches: ["develop"]
jobs:
build:
...
- name: Get keyfile from s3
env:
AWS_S3_KEYFILE_BUCKET: ${{ secrets.AWS_S3_KEYFILE_BUCKET }}
AWS_S3_DBT_MANIFEST_BUCKET: ${{ secrets.AWS_S3_DBT_MANIFEST_BUCKET }}
GOOGLE_KEYFILE_PATH: ${{ github.workspace }}/core/profile
DBT_MANIFEST_PATH: ${{ github.workspace }}
shell: bash
run: |
aws s3 cp $AWS_S3_KEYFILE_BUCKET $GOOGLE_KEYFILE_PATH
aws s3 cp $AWS_S3_DBT_MANIFEST_BUCKET $DBT_MANIFEST_PATH --recursive # prod 기반의 manifest.json 파일을 가져온다.
- name: Check PR validation
env:
GOOGLE_KEYFILE_PATH: ${{ github.workspace }}/core/profile/keyfile.json
GOOGLE_PROJECT_DBT_TEST_ID: ${{ secrets.GOOGLE_PROJECT_DBT_TEST_ID }}
GOOGLE_PROJECT_DBT_TEST_DATASET: ${{ secrets.GOOGLE_PROJECT_DBT_TEST_DATASET }}
METRIC_DB_ENDPOINT_RO: ${{ secrets.METRIC_DB_ENDPOINT_RO }}
METRIC_DB_ID_RO: ${{ secrets.METRIC_DB_ID_RO }}
METRIC_DB_PW_RO: ${{ secrets.METRIC_DB_PW_RO }}
DBT_MANIFEST_PATH: ${{ github.workspace }}/target
AWS_S3_DBT_MANIFEST_BUCKET: ${{ secrets.AWS_S3_DBT_MANIFEST_BUCKET }}
shell: bash
run: |
cd ${{ github.workspace }}
./ci.sh slimkeyfile 관리
dbt 에서 bigquery와의 credential을 위해서 keyfile.json 파일이 필요한데 처음에는 환경변수를 이용해서 github action 내에서 json 파일을 만들어서 사용을 하려고 했으나 해당 과정이 복잡했다. ( github action 환경에서 하다보니 path 문제도 있고 str 타입을 json 으로 컨버팅해주는 로직도 구현해주는 등… )
그래서 간단하게 s3 에 keyfile.json 을 저장하고 필요할 때마다 가져와서 쓸 수 있도록 구현했다. 따로 작업해줄 것도 없이 그냥 cli 한 줄이면 해결돼서 편리하다.
slim test

CI/CD 를 구현함에 있어 최대한 빠르게 진행될 수 있도록 고민을 했다. 속도를 내기 위해서 pip install, docker build를 할 때 cache를 사용할 수 있도록 구성하였고, dbt model 을 테스트 함에 있어서 full test를 하지 않고 slim test 를 할 수 있도록 구성하였다.
slim test 란 변경된 model 에 대해서만 dbt run을 돌려서 불필요하게 변경되지 않은 model들은 돌리지 않도록 하여 빠르게 테스트를 진행하는 방식이다.
dbt 에서는 기본적으로 dbt run 을 하게 되면 manifest.json 파일이 해당 프로젝트의 target 폴더 아래 생성된다.
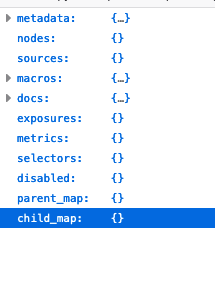
위와 같이 다양한 정보들이 담겨져 있는데 model에 대한 정보들 또한 담겨있다. 이를 바탕으로 변경된 코드로 dbt run을 다시 돌리게 됐을 때 그 차이를 분석하여서 변경된 model들만 dbt run or test를 진행할 수 있다. 이 와 유사한 방식으로 dbt 에서 제공되는 incremental type table이 돌아간다.
따라서 이를 구현하기 위해서는 manifest.json 파일을 관리해줘야 하는데 이 부분을 s3를 통해서 해결했다.
airflow dbt prod init dag 의 작업이 완료되게 되면 init을 진행한동안 새로 만들어진 manifest.json 파일을 s3 에 덮어쓰는 방식으로 관리가 된다.

이를 통해 manifest.json 은 항상 prod와 싱크가 맞춰서 update가 되고 prod 기반으로 model의 변경 사항을 테스트 해볼 수가 있다.
Dev build image & push github action
name: Dev build image & push
on:
push:
branches: ["develop"]
jobs:
build:
...
- name: Get keyfile from s3
env:
AWS_S3_KEYFILE_BUCKET: ${{ secrets.AWS_S3_KEYFILE_BUCKET }}
AWS_S3_DBT_MANIFEST_BUCKET: ${{ secrets.AWS_S3_DBT_MANIFEST_BUCKET }}
GOOGLE_KEYFILE_PATH: ${{ github.workspace }}/core/profile
DBT_MANIFEST_PATH: ${{ github.workspace }}
shell: bash
run: |
aws s3 cp $AWS_S3_KEYFILE_BUCKET $GOOGLE_KEYFILE_PATH
aws s3 cp $AWS_S3_DBT_MANIFEST_BUCKET $DBT_MANIFEST_PATH --recursive
- name: Build & Push Image
uses: docker/build-push-action@v2
with:
context: ${{ github.workspace }}
push: true
tags: ${{ secrets.DBT_REGISTRY_ENDPOINT }}:${{ secrets.DBT_REGISTRY_VERSION }}
cache-from: type=gha
cache-to: type=gha,mode=max
- name: Trigger Airflow init dag
env:
AIRFLOW_WEBSERVER_ENDPOINT: ${{ secrets.AIRFLOW_WEBSERVER_ENDPOINT }}
AIRFLOW_WEBSERVER_ID: ${{ secrets.AIRFLOW_WEBSERVER_ID }}
AIRFLOW_WEBSERVER_PASSWORD: ${{ secrets.AIRFLOW_WEBSERVER_PASSWORD }}
AIRFLOW_DBT_INIT_DAG_ID: ${{ secrets.AIRFLOW_DBT_INIT_DAG_ID }}
shell: bash
run: |
curl "$AIRFLOW_WEBSERVER_ENDPOINT/api/v1/dags/$AIRFLOW_DBT_INIT_DAG_ID/dagRuns" --user "$AIRFLOW_WEBSERVER_ID:$AIRFLOW_WEBSERVER_PASSWORD" -H 'Content-Type: application/json' -d '{}'Trigger airflow init dag
Image build 가 완료되면 airflow webserver 에 api call을 날려서 test를 위한 dag을 trigger한다.
init dag은 실행되기전에 PythonSensor를 통해 streaming dag이 현재 돌아가고 있는지 판단하고 진행된다. 따라서 중복 실행은 발생되지 않는다.
Airflow
처음에는 airflow image를 만들 때 dbt도 같이 더해서 하나의 image로 사용하려고 했었다.
하지만 airflow ( 2.2.3 ), dbt (1.2.0) 프레임워크 둘 사이의 package dependency가 강하게 묶여있고 각각 지원하는 버전의 차이가 심해서 함께 운영을 하기 위해서는 airflow의 버전을 높이거나 dbt의 버전을 낮출 수 밖에 없었다.
그래서 dbt image를 따로 관리하고 KuberntesPodOperator를 활용하여 운영하도록 구성했다.
KubernetesPodOperator Code sample
run_operator = KubernetesPodOperator(
task_id="full_init_table",
name="full_init_table",
cmds=["bash", "-cx"],
arguments=[args],
is_delete_operator_pod=True,
namespace=AirflowObject.AIRFLOW_NAMESPACE,
service_account_name=AirflowObject.AIRFLOW_AGG_METRIC_SA,
secrets=[secret_env],
env_from=configmaps,
image=f"{os.getenv('DBT_REGISTRY_ENDPOINT')}:{os.getenv('DBT_REGISTRY_VERSION', 'live')}",
affinity = {
'nodeAffinity': {
'requiredDuringSchedulingIgnoredDuringExecution': {
'nodeSelectorTerms': [{
'matchExpressions': [{
'key': 'alpha.eksctl.io/nodegroup-name',
'operator': 'In',
'values': [
'ng-spot',
]
}]
}]
}
}
}
)환경변수에 설정되어 있는 DBT image의 endpoint 와 버전 정보를 가져와서 해당 image를 기반으로 pod 를 띄울 수 있게 설정했다.
Dag sensor
Init용 dag, streaming용 dag을 따로 만들어서 운영을하면, 서로 동시에 돌 수 없고 무조건 하나의 dag만 running 을 해야하기 때문에 PythonSensor를 만들어 서로의 동작을 확인하고 실행할 수 있게 하였다.
abstraction_streaming_sensor = PythonSensor(
task_id="is_abstraction_streaming_dag_run",
python_callable=is_not_dag_run,
op_args=[DagId.ABSTRACTION_STREAMING_DAG, State.RUNNING],
poke_interval=30,
dag=dag,
)이 또한 webserver api를 통해 특정 Dag 의 running 상태를 받아오고 만약 돌고 있다면 pending 상태가 되어 기다리고 30초 간격으로 해당 sensor를 동작시킨다.
Streaming Dag
DBT의 model을 각각의 task로 나누어서 관리를 할 수 있도록 하였다. 이를 통해서 각각의 model들을 multiprocessing으로 빠르게 업데이트 할 수 있고 각각의 model을 graph 형태로 관리 할 수 있기 때문에 어떤 model에서 문제가 생겼고 그 관련 model들도 한 눈에 확인할 수 있다.
또한 문제가 생긴 model을 수정하고 해당 task만 clear를 해주면 연관 되어 있는 자식 task들도 순차적으로 업데이트를 진행할 수 있어 편리하다.
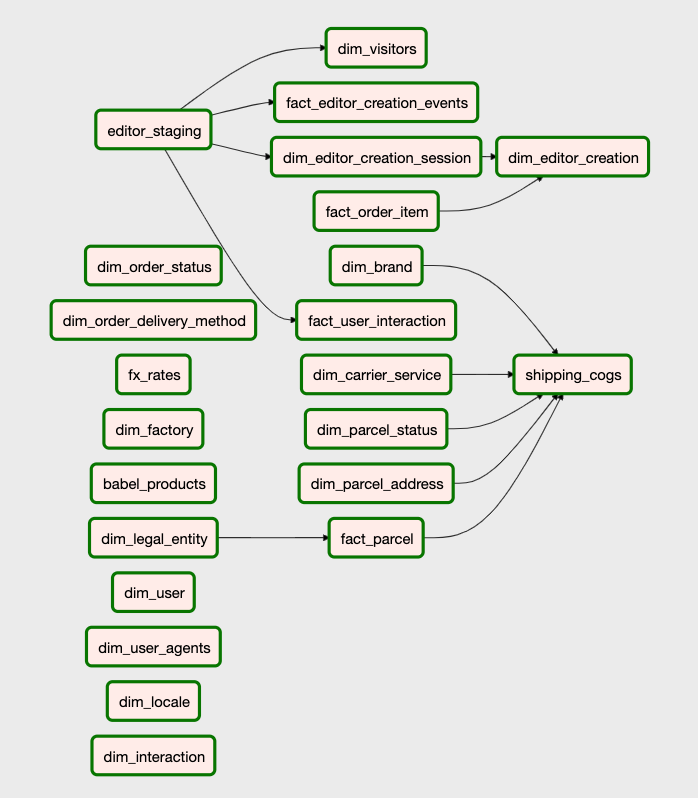
이와 같이 dbt 의 model들의 리니지 정보를 얻고 task로 만들기 위해서 manifest.json파일을 가져와서 사용한다. init dag을 통해서 update된 manifest.json 파일을 토대로 streaming dag을 파싱하여 task를 만들게 되는데 코드로 보면 아래와 같다.
PARENT_MAP = 'parent_map'
def get_manifest() -> dict:
"""
Get manifest.json file from s3.
"""
s3 = boto3.resource('s3')
manifest_object = s3.Object(DBTS3.DBT_BUCKET, DBTS3.DBT_MANIFEST)
file_content = manifest_object.get()['Body'].read().decode('utf-8')
json_content = json.loads(file_content)
return json_content
def sanitise_node_names(value: str) -> str:
"""
Sanitise node name value format is like models.{project_name}.{table_name}
so using split method remove models.{project_name}.
"""
segments = value.split('.')
if segments[0] == 'model':
return value.split('.')[-1]
def get_node_structure() -> dict:
"""
the json file parent map key's value format is
{
model.{project_name}.{table_name} : [
'0': seed.{project_name}.{table_name}, '1': model.{project_name}.{table_name}. ...
],
model.{project_name}.{table_name} : [
'0': model.{project_name}.{table_name}, '1': model.{project_name}.{table_name}. ...
],
...
,
seed.{project_name}.{table_name} : [],
seed.{project_name}.{table_name} : [],
...
}
"""
manifest = get_manifest()
ancestors_data = manifest[PARENT_MAP]
tree = {}
for node in ancestors_data:
if node.startswith("model"):
ancestors = list(set(ancestors_data[node]))
clean_ancestors = [sanitise_node_names(ancestor) for ancestor in ancestors]
clean_node_name = sanitise_node_names(node)
if clean_node_name is not None:
tree[clean_node_name] = clean_ancestors
return tree- get_manifest() 함수를 통해서 s3 에 연동을 하여 manifest.json 파일을 가져온다.
- sanitise_node_names() 함수를 이용하여 json 파일에 있는 model 정보를 sanitise시킨다.
- get_node_structure() 함수를 통해서 model 계보를 tree방식으로 저장한다.
nodes = get_node_structure()
operators = {}
with models.DAG(
dag_id=DagId.ABSTRACTION_STREAMING_DAG,
schedule_interval='* 1 * * *',
start_date=datetime.today(),
default_args=default_args,
tags=["dbt", "abstraction"]
) as dag:
...
# Parse nodes and assign operator dependencies
for node in nodes:
for parent in nodes[node]:
if (parent != None):
abstraction_init_sensor >> operators[parent] >> operators[node]- get_node_structure() 함수를 통해 얻어낸 node tree 정보를 이용하여 iteration을 돌아 task를 tree 형태로 만든다.
Reference
https://airflow.apache.org/docs/apache-airflow/stable/tutorial.html
https://docs.getdbt.com/docs/building-a-dbt-project/documentation
https://tech.socarcorp.kr/data/2022/07/25/analytics-engineering-with-dbt.html
https://docs.getdbt.com/blog/dbt-airflow-spiritual-alignment
