TLDR
DA 분들의 SQl코드 리뷰를 진행하다가 Window function의 활용이 많이 보여 찾아보고 정리할 필요를 느낌.
What is window function?
Window function 은 query row 세트에 대한 aggregation-like (aggregation 과 비슷해보이지만 다르다. )과 같은 동작을 수행한다. aggregation 동작은 query rows를 모아 하나의 query row의 결과값을 보여주지만 window function은 각각의 query row의 결과를 보여준다.
aggregate vs window function
SELECT block_height, SUM(output_total) as sum_of_output_total FROM `tech-abstraction-dev-360405.raw_data_bitcoin_temp.btc_bitcoin_transaction` where block_height = 110000 group by block_height order by block_height desc;Result
[{
"block_height": "110000",
"sum_of_output_total": "754.57"
}]SELECT block_height, SUM(output_total) OVER(partition by block_height) as sum_of_output_total FROM `tech-abstraction-dev-360405.raw_data_bitcoin_temp.btc_bitcoin_transaction` where block_height = 110000 order by block_height desc;Result
[{
"block_height": "110000",
"sum_of_output_total": "754.57"
}, {
"block_height": "110000",
"sum_of_output_total": "754.57"
}, {
"block_height": "110000",
"sum_of_output_total": "754.57"
}, {
"block_height": "110000",
"sum_of_output_total": "754.57"
}, {
"block_height": "110000",
"sum_of_output_total": "754.57"
}, {
"block_height": "110000",
"sum_of_output_total": "754.57"
}, {
"block_height": "110000",
"sum_of_output_total": "754.57"
}, {
"block_height": "110000",
"sum_of_output_total": "754.57"
}, {
"block_height": "110000",
"sum_of_output_total": "754.57"
}, {
"block_height": "110000",
"sum_of_output_total": "754.57"
}, {
"block_height": "110000",
"sum_of_output_total": "754.57"
}, {
"block_height": "110000",
"sum_of_output_total": "754.57"
}]위와 같이 aggregation은 하나의 single row가 나오게 되고 window function은 계산에 참여했던 모든 row 의 값들을 반환해주게 된다.
Window function 의 format
기본적인 window function 의 포맷은 아래와 같다.
select Fucntion() OVER(partition by column order by column) as test_column From table;order by 는 생략해줄 수도 있다 그럼 unordered 한 상태로 return 된다.
Aggregation function
아래 aggregation function 모두 Over clause를 사용할 수 있다. 실제 aggregation 의 용도로 사용할 때는 over 가 생략되고 aggregation function의 기능을 하지만 OVER 를 명시해주면 window function으로 사용이 가능하다.
AVG()
BIT_AND()
BIT_OR()
BIT_XOR()
COUNT()
JSON_ARRAYAGG()
JSON_OBJECTAGG()
MAX()
MIN()
STDDEV_POP(), STDDEV(), STD()
STDDEV_SAMP()
SUM()
VAR_POP(), VARIANCE()
VAR_SAMP()
Window function
CUME_DIST()
DENSE_RANK()
FIRST_VALUE()
LAG()
LAST_VALUE()
LEAD()
NTH_VALUE()
NTILE()
PERCENT_RANK()
RANK()
ROW_NUMBER()
다양한 window function이 존재한다.
많이 사용되는 window function
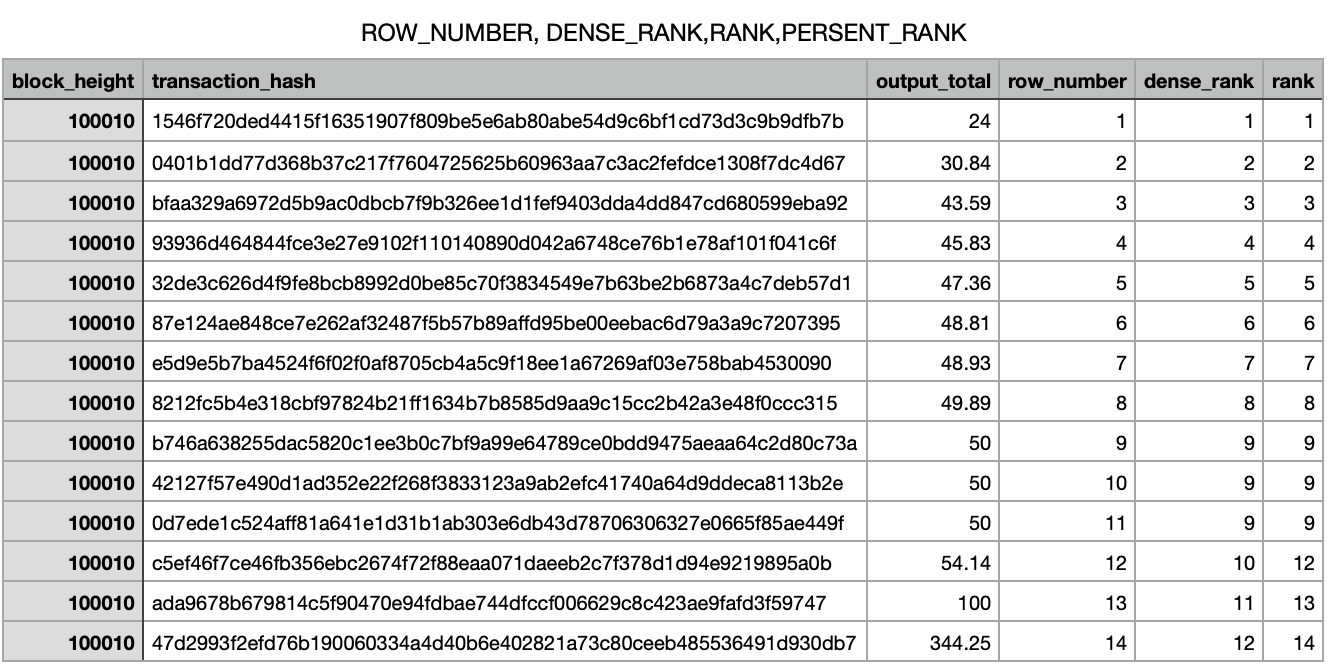
DENSE_RANK(), ROW_NUMBER(), RANK()
Row number는 같은 값상관 없이 모두 unique 하게 rank를 부여한다.
Rank 는 같은 값이라면 같은 rank를 부여하고 다음 rank 부여에 gap이 생기게 된다. ( 중복된 부여 수 만큼 )
Dense rank 는 rank와 다른점은 gap 이 없이 rank 부여가 된다는 점.
SELECT block_height,
transaction_hash,
output_total,
ROW_NUMBER() OVER(partition by block_height order by output_total) as row_number,
DENSE_RANK() OVER(partition by block_height order by output_total) as dense_rank,
RANK() OVER(partition by block_height order by output_total) as rank,
PERCENT_RANK() OVER(partition by block_height order by output_total) as percent_rank,
FROM `tech-abstraction-dev-360405.raw_data_bitcoin_temp.btc_bitcoin_transaction` where block_height = 100010 order by output_total asc;Result
LAG(), LEAD()
lag는 이전 행의 값, lead는 바로 이후의 행의 값을 가져온다.
Optional 하게 몇 번쨰 이전, 이후의 값을 사용할 것인지를 설정할 수 있다.
e.g. lag(column, 3) 3번째 이전, lead(column, 3) 3번째 이후
SELECT block_height, transaction_hash, output_total, LAG(output_total) OVER (partition by block_height order by output_total) as prev_output_total, LEAD(output_total) OVER (partition by block_height order by output_total) as next_output_total FROM `tech-abstraction-dev-360405.raw_data_bitcoin_temp.btc_bitcoin_transaction` where block_height = 110000 order by output_total desc;Result
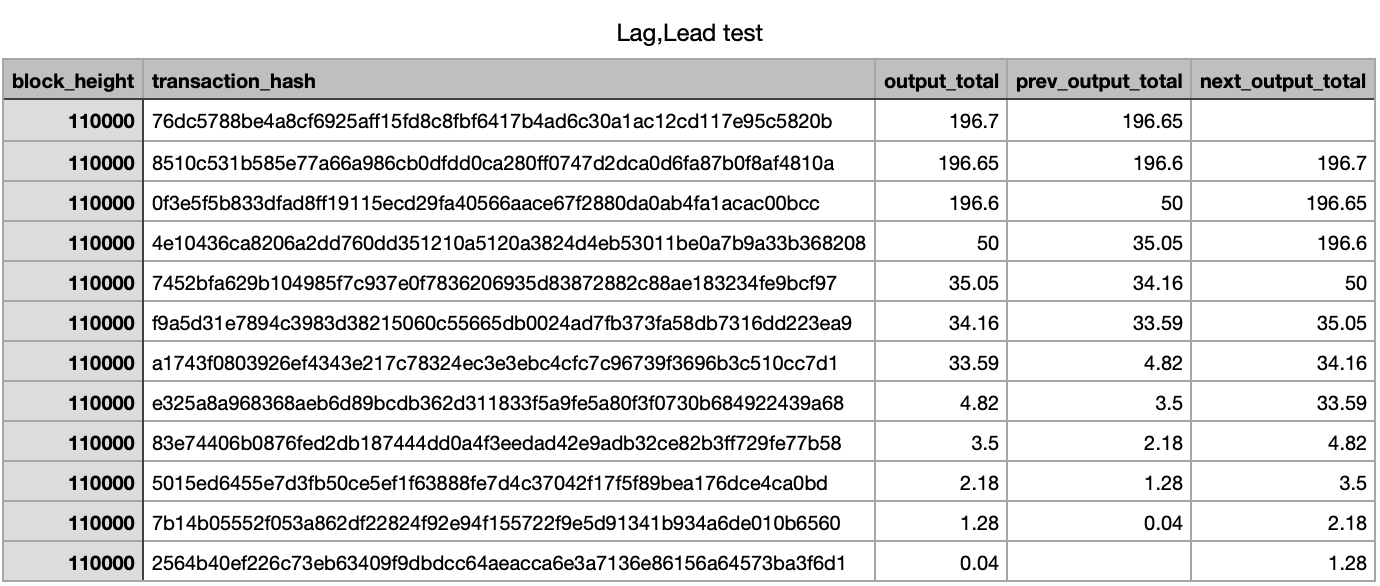
이전 혹은 이후 값이 없는 경우는 null로 채워지게 된다.
FIRST_VALUE(), LAST_VALUE(), NTH_VALUE()
해당 partition 의 첫 번째, 마지막 row의 값을 의미한다.
NTH_VALUE 는 n 번째 value의 값을 의미한다.
SELECT block_height,
transaction_hash,
output_total,
LAG(output_total) OVER (partition by block_height order by output_total) as prev_output_total,
LEAD(output_total) OVER (partition by block_height order by output_total) as next_output_total,
FIRST_VALUE(output_total) OVER (partition by block_height order by output_total) as fisrt_value,
LAST_VALUE(output_total) OVER (partition by block_height order by output_total) as last_value,
NTH_VALUE(output_total, 2) OVER (partition by block_height order by output_total) as nth_value,
FROM `tech-abstraction-dev-360405.raw_data_bitcoin_temp.btc_bitcoin_transaction` where block_height = 110000 order by output_total desc;Result
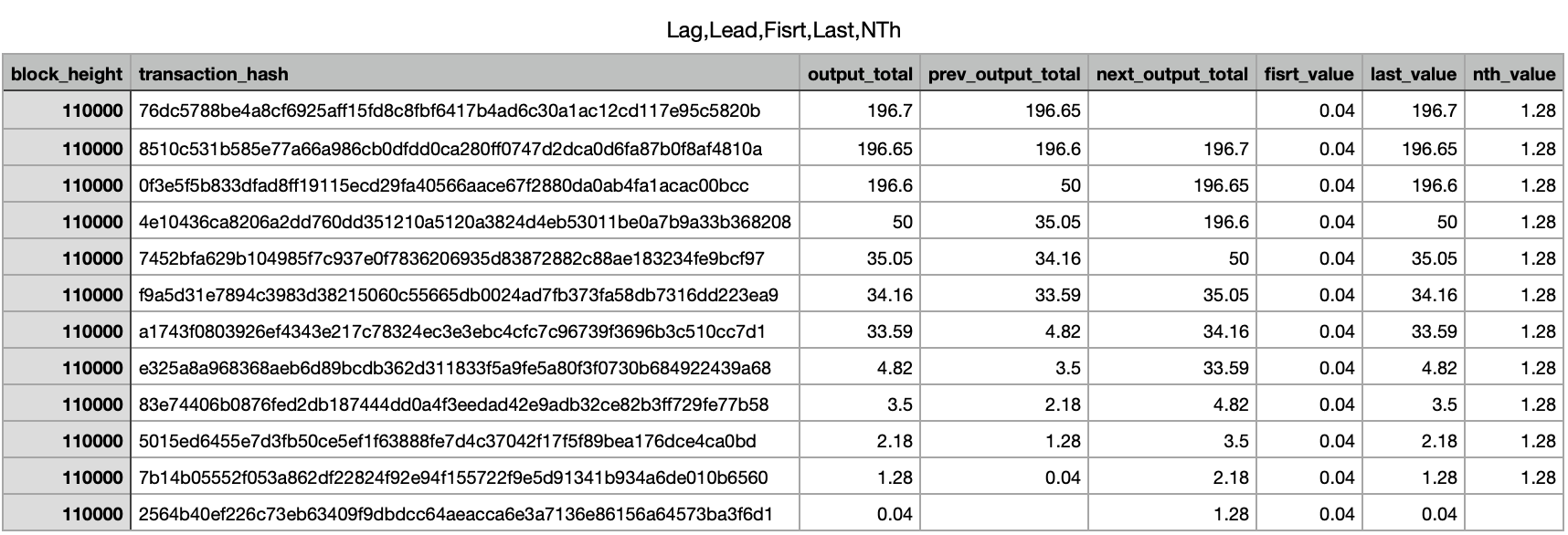
First, Last, n번째 value 가 채워짐을 확인할 수 있다. ( Desc 라 순서가 반대임 )
재밌는 부분은 nth_value에서 n 번째 value를 채우고 그 이전 index의 row 들은 null이 채워진다.
Reference
https://docs.oracle.com/cd/E17952_01/mysql-8.0-en/window-functions-usage.html
