⌚ 활동 시간 : 2023년 1월 7일 오후 8시 ~ 오후 11시
✨ 목표 : [모두의 딥러닝] 4~6장 공부
모두의 딥러닝 4, 5, 6장 내용을 읽고 정리하였다.
4장을 공부하기 전에, 3장에서 나온 최소 제곱법, MSE를 계산하는 코드를 책을 참고하며 작성하였다.
과정을 하나씩 천천히 이해하며 공부하는 것이 즐거운 과정임을 느꼈다.
🎈 3장
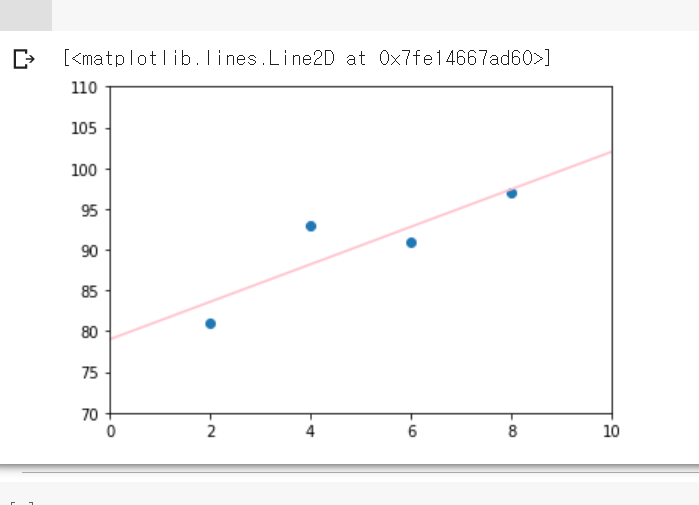
1. 선형 회귀 실습1 - 최소 제곱법
최소 제곱법을 수행하는 코드를 작성하고 이를 그래프로 그렸다.
# 선형 회귀 - 최소 제곱법
# 참고자료 : [모두의 딥러닝] p.63~64
import numpy as np
import matplotlib.pyplot as plt
x = [2,4,6,8]
y = [81, 93, 91, 97]
mx = np.mean(x) #x의 평균
my = np.mean(y) #y의 평균
a = (sum([(x[i]-mx)*(y[i]-my) for i in range(len(x))]))/(sum([(i-mx)**2 for i in x])) #기울기 a
b = my - (mx * a) #기울기 b
plt.scatter(x, y) # 주어진 데이터 표시
plt.xlim([0, 10]) #x축 최소값, 최대값 지정
plt.ylim([70, 110]) #y축 최소값, 최대값 지정
predict = [i * a + b for i in range(0, 11)] #선형 회귀 함수값 계산
plt.plot([x for x in range(0, 11)],predict, color='pink') #선형 회귀 함수 표시
2. 선형 회귀 실습2 - 평균 제곱 오차
평균 제곱 오차를 계산하는 코드를 작성하고 이를 그래프로 그렸다.
# 선형 회귀 - 평균 제곱 오차
# 참고자료 : [모두의 딥러닝] p.69~73
import numpy as np
import matplotlib.pyplot as plt
temp_a_b = [3, 76] # 평균 제곱 오차를 구하기 위해 임의로 정한 기울기 a와 절편 b
data = [[2, 81],[4, 93],[6, 91],[8, 97]] # 짝으로 묶인 데이터
x = [i[0] for i in data] # 독립변수 x
y = [i[1] for i in data] # 종속변수 y
def predict(x):
return temp_a_b[0]*x + temp_a_b[1] # ax + b 구현
def mse(y, y_hat):
return ((y-y_hat)**2).mean() # 평균 제곱 오차 계산
predict_result = [] # 함수 예측 결과 저장
for i in range(len(x)):
predict_result.append(predict(x[i])) # predict 함수로 예측값 계산하기
print(mse(np.array(y), predict_result)) # mse 계산하기
plt.scatter(x, y) # 주어진 데이터 표시
plt.xlim([0, 10]) #x축 최소값, 최대값 지정
plt.ylim([70, 110]) #y축 최소값, 최대값 지정
plt.plot([2, 4, 6, 8], predict_result, color='pink') #선형 회귀 함수 표시🎈 4장
경사 하강법과 학습률에 대해 소개한다.
경사 하강법
평균 제곱 오차 계산 과정을 통해 기울기 를 적절하게 지정해야 오차를 줄일 수 있음을 확인했다. 오차와 기울기 의 관계는 아래로 볼록한 이차 함수 그래프로 표현할 수 있다.
오차가 가장 작은 지점은 이차 함수 그래프의 최저점이 되는 곳이다. 그것은 이차 함수 그래프를 미분하였을 때 미분 값이 0이 되는 지점이다. 이를 찾는 과정은 아래와 같다.
- 에서 함수를 미분한다.
- 1에서 계산한 미분값에 -1을 곱한 방향으로 얼마간 이동시킨 지점 에서 미분값을 구한다.
- 2에서 계산한 미분 값이 0이 아니면 1-2를 반복한다.
경사 하강법은 기울기 를 변화시키며 미분값이 0이 되는 기울기를 를 찾는다.
학습률
경사 하강법에서 부호를 바꾸며 를 이동시킬 때 적절한 거리를 찾지 못하면 값이 으로 수렴하지 못하는 경우가 생긴다. 이를 방지하기 위해 적절한 이동 거리를 찾아야 하는데 이를 찾는 것이 학습률이다.
경사 하강법은 오차와 기울기의 관계를 이차 함수 그래프로 만들고, 기울기 값이 에 수렴할 수 있도록 적절한 학습률을 설정해서 미분 값이 0인 지점을 구하는 것이다.
다중 선형 회귀
독립변수 x가 2개 이상일 경우 다중 선형 회귀를 이용한다.
2차원 그래프가 아닌, 3차원 그래프로 표현할 수 있다.
🎈 5장
로지스틱 회귀에 대해 설명한다.
로지스틱 회귀는 선형 회귀와 마찬가지로, 예측을 위해 적절한 선을 그어가는 과정이다. 그러나 로지스틱 회귀는 직선이 아니라 참(0), 거짓(1)과 같은 것을 구분하는 S자 형태의 선을 그어주는 작업이다. 이를 위해 시그모이드 함수를 사용한다. 시그모이드 함수를 이용하여 로지스틱 회귀를 풀어나가는 공식은 아래와 같다.
위 식에서 a는 그래프의 경사도를 결정한다. a값이 클수록 경사도가 커진다. b는 그래프의 이동을 결정한다.
a와 b는 오차를 결정한다. a가 작아질수록 오차는 무한대로 커지고, a가 커질수록 오차는 작아진다. 하지만 a가 무한대로 커진다고 해서 오차가 사라지는 것은 아니다. b에 따른 오차는 이차함수 그래프와 유사한 형태를 띈다. 따라서 a와 b의 적절한 값을 찾는 것이 오차를 줄이는 방법이다.
이를 위해서 경사 하강법을 이용할 수 있다. 경사 하강법을 이용하기 위해서는 오차를 계산하는 과정이 먼저 필요한데 이는 시그모이드 함수의 특성을 사용하여 도출할 수 있다.
실제 값이 0일때는 예측 값이 1에 가까울 수록 오차가 큰 것이고 실제 값이 1일때는 예측 값이 0에 가까울수록 오차가 큰 것이다. 이는 로그함수를 이용하여 공식으로 만들 수 있다.
🎈 6장
퍼셉트론에 대해 설명한다.
인공 신경망은 인간의 뉴런과 비슷한 메커니즘을 사용하는 기술이다. 여러 층의 퍼셉트론을 연결시키고 조합하여, 주어진 입력 값에 대한 판단을 하는 것이 기본 구조이다.
신경망을 이루는 기본 단위는 퍼셉트론(perceptron)이다. 퍼셉트론은 입력 값과 활성화 함수를 사용해서 출력 값을 다음 퍼셉트론으로 넘기는 가장 작은 신경망 단위이다.
선형 회귀, 로지스틱 회귀 단원에서 사용한 용어인 기울기 는 가중치 로, 절편 는 바이어스 로 표현할 수 있다. 입력값 와 가중치 의 곱을 모두 더하고 바이어스 를 더한 값을 가중합이라고 한다. 가중합의 결과를 0 또는 1로 판단하는 활성화 함수를 사용하여 다음 퍼셉트론으로 보낼 수 있다.
XOR문제
XOR문제는 퍼셉트론의 한계를 설명한다. AND게이트와 OR게이트는 직선을 그어서 결과값이 1인 경우와 0인 경우를 분류할 수 있지만, XOR게이트의 경우는 불가능하다. 이는 퍼셉트론으로 XOR게이트 문제를 해결 할 수 없음을 의미한다. 이로 인해 인공지능 연구가 한동안 침체기를 겪는다. 10여 년 후, 다층 퍼셉트론 개념이 등장하면서 문제가 해결된다.
참고 자료
https://ggodong.tistory.com/47
https://wikidocs.net/92082
https://velog.io/@nestory/XOR-%EB%AC%B8%EC%A0%9C%EC%99%80-%ED%95%B4%EA%B2%B0%EB%B0%A9%EB%B2%95
GitHub
실습 결과 GitHub
