
과적합(overfitting)
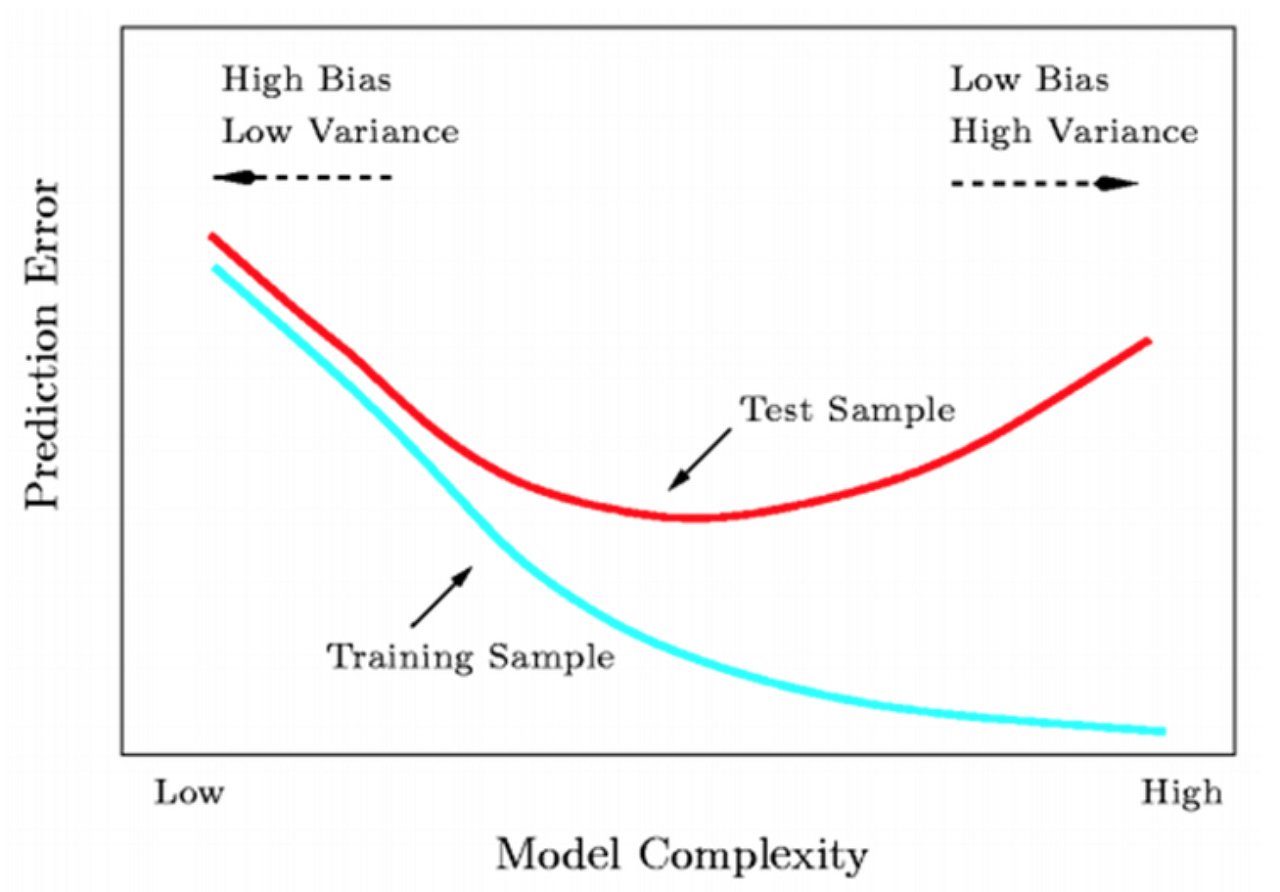
학습 데이터에 모델이 과적합되는 현상은 모델의 성능을 떨어트리고 편향된 결과를 가져올 수 있는 주요 이슈임. 훈련 데이터의 성능이 높다고 하더라도 검증 데이터나 테스트 데이터에 대해 데이터를 이해하고 나올 수 있는 결과가 아님.
따라서 과적합을 해결하는 방법은 딥러닝을 다루는 사람들한테 필수적으로 알아야 할 내용임.

출처 : https://iotnbigdata.tistory.com/15
1) low training low testing error : good
2) low training, high testing error : overfitting
3) high training, low testing error : psychic ai(무당)
4) high training, high testing error: no training;;
ㅋㅋㅋ 찰떡이어서 가져와봤음.
과적합을 해결하는 방법
일반적으로 과적합을 방지하는 방법에는 다음과 같이 있음.
1) 데이터 수 늘리기
데이터 양이 작으면 특정 패턴이나 잡음을 암기할 가능성이 높아지기 때문에 과적합 현상이 발생할 확률이 늘어남. 따라서 양을 늘리면 데이터의 일반적인 패턴을 학습하여 과적합을 방지할 수 있음.
그러나, 처음부터 데이터 수가 작은 경우에는 의도적으로 데이터를 변형하고 추가하는 augmentation 기법들을 이용하거나 gan 등을 이용하여 진짜와 유사한 데이터를 생성하는 방법 등이 있음.
2) 모델의 complexity 줄이기 == 단순화
DNN에서 모델이 복잡하다는 의미는 은닉층의 수나 매개변수 수 등이 많다는 의미임. 데이터에 비해 모델이 과하게 깊거나 넓을 경우 훈련 데이터에만 적합한 과적합 현상이 생길 수 있음.
이를 방지하기 위해 모델을 가볍게 할 수 있음.
3) 다양한 방법 사용
3-1) 가중치 규제
가중치 규제를 적용함. 이는 2)의 개념의 한 종류인데, 복잡한 모델을 조금 더 간단하게 만들 수 있는 방법임. 대표적으로 2개의 규제를 많이 사용함.
-
L1 규제 : 가중치 W들의 절대값 합계를 loss에 추가함. 주로, 어떤 특성들이 모델에 영향을 주고 있는지 판단할 때 사용한다고 함.
-
L2 규제 : 가중치 W들의 제곱합을 loss에 추가함. L1 규제보다 보통 결과가 좋다고 알려짐. 이 규제를 가중치 감쇠(weight decay)라고도 부름.
3-2) 드롭아웃
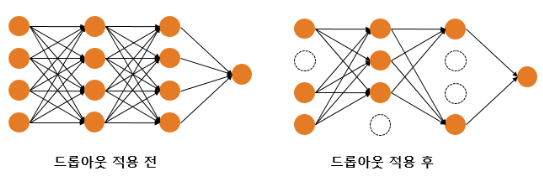
드롭아웃은 신경망의 일부를 계산하지 않는 방법임. 즉, 사용자가 지정한 비율에 따라 계산되지 않는 곳이 존재. 이를 통해 특정 뉴런에만 의존적이지 않게 변하여 과적합을 완화할 수 있음.
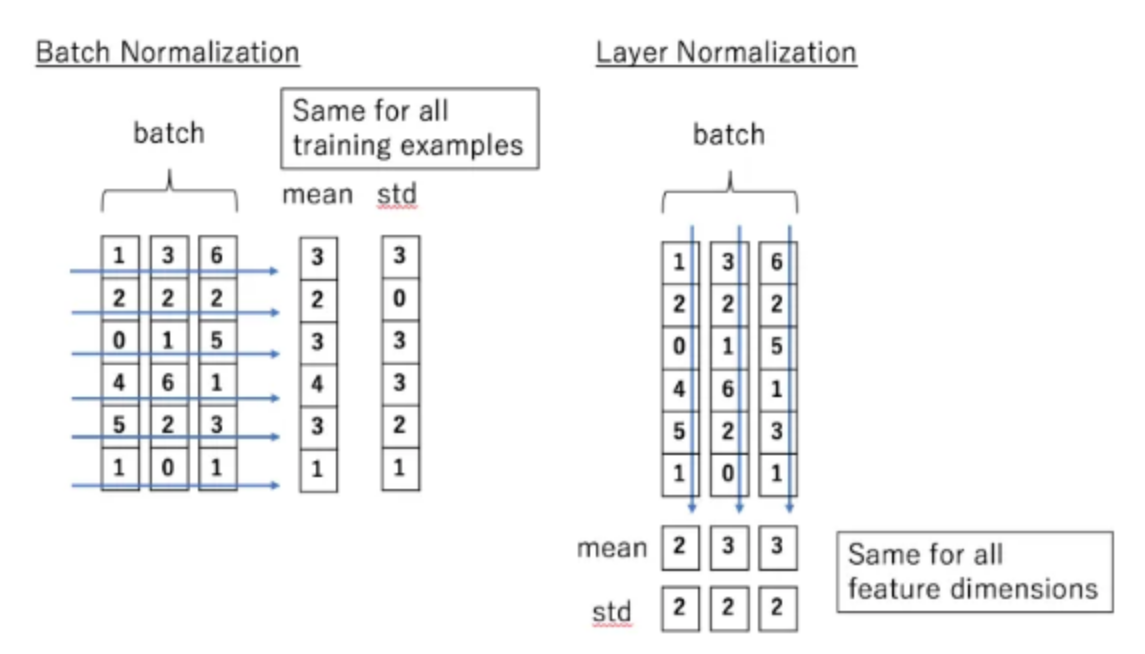
3-3) 정규화
 출처 : https://kwonkai.tistory.com/144
출처 : https://kwonkai.tistory.com/144
배치 정규화, 층 정규화 등이 존재함.
- 배치 정규화(batch normalization) : mini-batch에 대한 평균과 분산을 구함. 학습의 수렴속도를 높일 수 있음.
- 층 정규화(layer normalization) : training case 별로 평균과 분산을 구함. 작은 batch에 대해서도 효과적인 이용이 가능함.
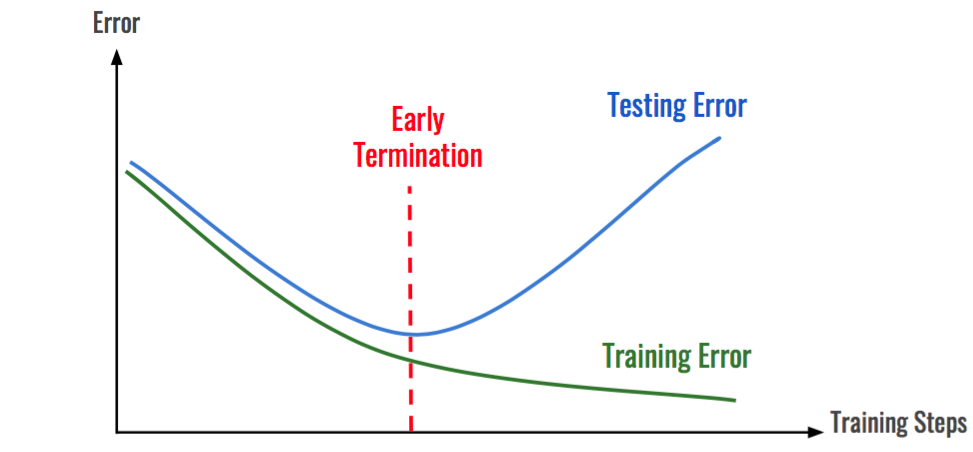
3-4) 조기종료(early stopping)
출처 : https://iotnbigdata.tistory.com/15
조기 종..료.. 학습시 loss가 일정 이상 안떨어지면 학습을 종료하겠다는 의미. 하지만 필자는 조기종료 썼다가 쓰지 말라는 피드백을 받음.. patient를 좀 더 주면 괜찮을 것 같음
4) 그 외
학습 데이터의 적절한 편향을 인정하고 그 사이에서 좋은 균형을 잡아낼 것!
GPT한테 물어본 과적합 방지 TIP!^^
- 앙상블 방법

- 스케줄러

- 자기 지도 학습

학습을 하다보면 흔히 과적합 문제를 많이 만날 수 있게 됨. 이러한 기법들을 써서 문제를 해결하면 좋을 것 같음. 하지만 필자는 아직 해결을 못했음. 조금 더 기법들을 찾아보고 후기를 가져오겠음.
Reference
[1] https://wikidocs.net/61374
[2] https://22-22.tistory.com/35
