

가보자고!
Denoising model
Denoising model은 잡음을 제거하는 모델이다. 이러한 모델은 이미지의 전송, 저장 과정에서 생기는 어쩔 수 없는 잡음을 제거하여 실제 원본 이미지를 가질 수 있게 도와준다.
이전 게시글에서 denoising 분야의 전반적인 모델에 대해서 살펴보았다. 그 중에서 GAN 모델 관련 내용들이 많이 있는 것을 살펴볼 수 있다. 잡음을 제거하여 원래 이미지 형태로 생성하기 때문이라고 이해하면 된다.
오늘 게시글은, 요즘 denoising 분야에서 무조건 쓰이는 DDPM 모델에 대해서 알아보고자 한다.
Denoising Diffusion Probabilitic Model [Ho et al. 2020]
diffusion model(확산 모델)을 활용하여 이미지를 생성하는 모델을 만든 논문으로, DDPM은 확산 모델에서 loss와 parameter 과정을 잘 학습시키는 방향으로 발전시킨 논문이다.
먼저 확산 모델과 타 생성 모델들을 비교하여 어떤 방식을 채택하는지 살펴보자.

하나씩 설명하면 다음과 같다.
- GAN : discriminator와 generator가 서로 적대적으로 학습하면서 데이터를 생성함.
- VAE : 잡음의 평균과 분산을 학습하는 방식으로 데이터를 생성함.
- Flow-based models : 확률 분포에서부터 변환을 해준 뒤 역변환을 하면서 복잡한 분포로 데이터를 생성함.
- Diffusion models : 데이터에 스텝별로 잡음을 더해준 뒤 다시 빼주는 방식으로 데이터를 생성함.
위에 3가지 방식은 거의 비슷한 개념인 거 같다.
잡음을 더해줘서 완벽한 잡음의 분포에서 다시 데이터를 생성하는 방식인 diffusion models에 대해서 알아보자.
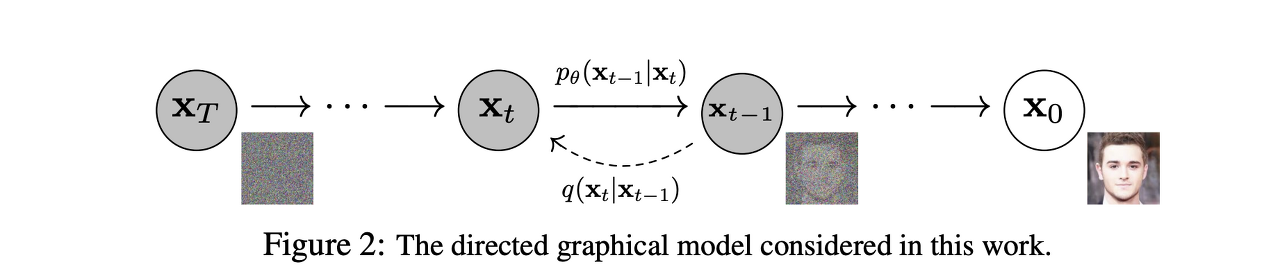
DDPM 에서는 이미지에 잡음을 추가하는 과정(forward process)과 다시 없애는 과정(reverse process)으로 이루어져 있다. 위 사진에서 각 문자가 정의하는 바는 다음과 같다.
- x0 : 원본 이미지
- q : 잡음을 더해주는 과정
- xt : 가우시안 분포를 띄는 잡음
- p : 역으로 잡음을 빼주는 과정
forward process와 reverse process에 대하여 알아보자.
1) forward process
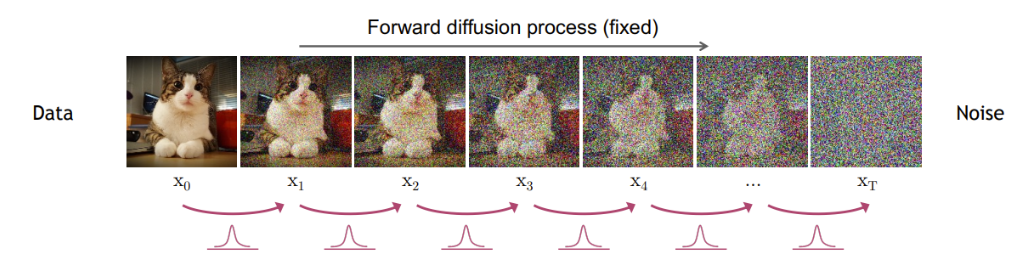
우리는 원본 이미지는 x0에서부터 출발하여 가우시안 분포를 가진 잡음인 xt를 만드는 과정을 forward process라고 부른다.
잡음을 만드는 과정을 간략하게 식으로 나타내면 다음과 같다.
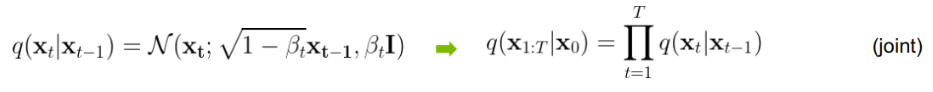
q는 앞서 얘기한 대로 잡음을 더해주는 과정인데 잡음을 더해줄 때 가우시안 분포의 잡음을 미세먼지만큼 더해준다. 0부터 T까지 더해주는 것이 오른쪽 식으로 나와 있다.
여기서 한 스텝 한 스텝 더해주는 것이 아니라 한 번에 여러 스텝을 갈 수 있는 식을 변환하면 다음과 같이 정의할 수 있는데 이를 diffusion kernel이라고도 한다.
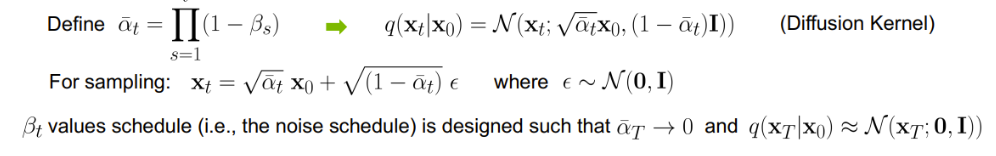
여러 정리를 통해 샘플링을 하게 되면 Xt 즉, 잡음이 다음과 같이 원 데이터 x0에서 일정 값을 곱하고 가우시안 분포 잡음을 더해주는 형태로 샘플링 된다고 한다.
따라서, 이 식에서의 결론은 x0에서 xt까지 갈 때 이 xt를 가우시안 분포와 동일하게 만드는 것에 초점을 둔다고 한다. 즉, 평균과 분산을 가우시안 분포의 평균과 분산처럼 만들고 싶어하는 것이다.
2) reverse process
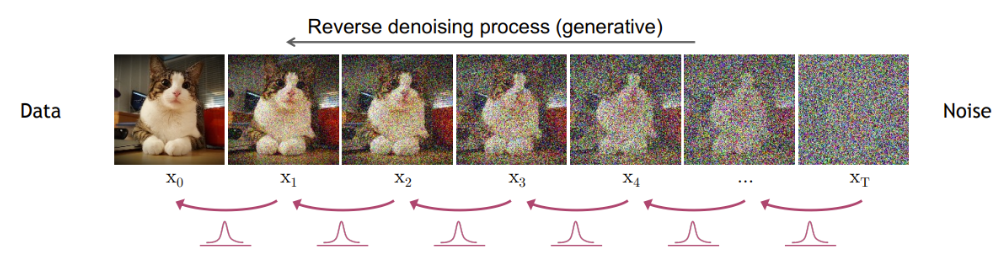
또한 학습 시켜야 할 것이 이 부분이다. reverse process의 경우 잡음으로부터 원 데이터를 얻는 과정을 의미하는데 이 또한 앞서 가우시안 분포의 샘플링 값을 더해준 것처럼 없애주어야 한다.

식으로 나타내면 다음과 같다. reverse process를 다시 얘기해보면 xt에서 xt-1로 갈 때의 평균과 분산을 알 수 있다면, x0로도 갈 수 있다고 얘기하고 그것을 학습시킬 수 있다고 한다.
즉, xt를 보고 그 전 xt-1의 평균과 분산을 예측하는 문제이다.
DDPM의 대략적인 과정에 대해서 살펴보았다.
다음은 논문에서 loss를 어떻게 해결하였는지를 살펴보겠다.
LOSS
loss를 나타내면 다음과 같다. loss를 잡음을 어떻게 제거할 것인가에 초점을 두고 만들어진다.
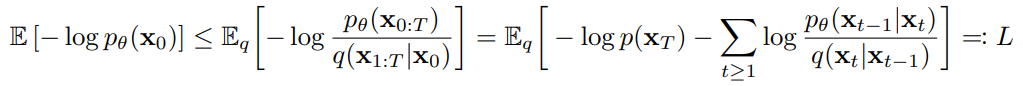
위 loss를 최소화 하면서 reverse process를 학습하여 잡음으로부터 실제 이미지와 유사한 이미지를 생성할 수 있다.
논문에서는 negative log likelihood를 최소화 하는 방향으로 진행하고 VAE와 마찬가지로 ELBO 등을 이용하여 오른쪽 식으로 바꾸어 해결하려고 했다. 하지만 해결할 수 없었고, 이후에 나온 후속 논문에서 이를 증명해서 또 다르게 바꾸었다고 한다.
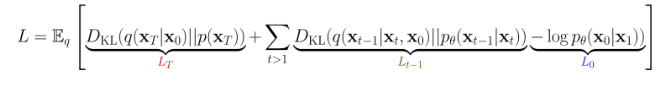
이 loss를 최소화 하는 방향으로 학습한다. 크게 3가지로 나눌 수 있다. Lt, Lt-1, L0이다. 이 3가지 중에서 특히 Lt-1가 제일 중요하다.
1) Lt : regularization term으로 같은 가우시안 분포를 가지고 있으면 0이 된다고 한다.
2) Lt-1 : reconstruction term으로 forward process에서 time에 대한 가우시안 분포가 주어지면 데이터의 재생성이 가능하다는 것을 의미한다. step 별로 잡음을 지우는 과정과 연관되어 있다.
3) L0 : 두 가우시안 분포 사이의 KL divergence이다. 영향력이 작다.
요약
논문에서는 이러한 복잡한 과정들의 결론을 상당히 간단한 algorithm으로 풀어두었다.

Algorithm 1에서는 잡음을 더해가는 학습 과정을 나타내고 있다. 네트워크가 t step에서 잡음이 얼만큼 더해졌는지 학습하고 특정 step의 이미지에 잡음이 얼마나 추가되엇는지 예측한다.
- x0 ~ q(x0) : 데이터로부터 잡음을 추가해가는 과정
- t ~ Uniform(1~T) : t시점
- E : epsilon
- N(0,i) : 가우시안 분포
즉, 학습 과정에서는 최종 잡음(가우시안 분포)과 집음으로 가는 과정(가우시안 분포)을 유사하게 만들게끔 학습을 해야한다는 의미이다.
코드에서는 랜덤 잡음과 t step 별로 잡음이 추가된 이미지를 얻고 이미지를 보고 모델이 잡음이 예측하는 방식으로 학습한다.

Algorithm 2에서는 샘플링 과정을 나타내고 있는데, 이는 다시 돌아오는 reverse process 속에서 진행되며, 다시 돌아오는 t 시점을 거리로 나타내는 것과 비슷하다고 한다.
네트워크를 학습하고 나면 순차적으로 denoising이 가능하다는 것이다.
구현
이 DDPM의 이점 중 하나는 깃허브에 구현이 잘 되어 있다는 점이다. 많은 사람들이 관련 코드를 깃허브에 올려두었으므로 다운받아서 쓰면 된다. 나는 구현할 능력이 되지 않아서, 남들이 구현한 코드를 공부하는 전략을 채택한다..! ㅋㅋㅋ
https://github.com/lucidrains/denoising-diffusion-pytorch
pip install denoising_diffusion_pytorch이 패키지를 설치하면 된다.
위 패키지를 사용한 간단한 예시는 다음 시간에 업로드 하도록 하겠다.
Reference
[1] 논문
[2] https://lilianweng.github.io/posts/2021-07-11-diffusion-models/
[3] https://www.youtube.com/watch?v=uFoGaIVHfoE&t=1s
[4] https://velog.io/@hanlyang0522/DDPM-Denoising-Diffusion-Probabilistic-Models-%EB%85%BC%EB%AC%B8-%EB%A6%AC%EB%B7%B0
