

Paper Name
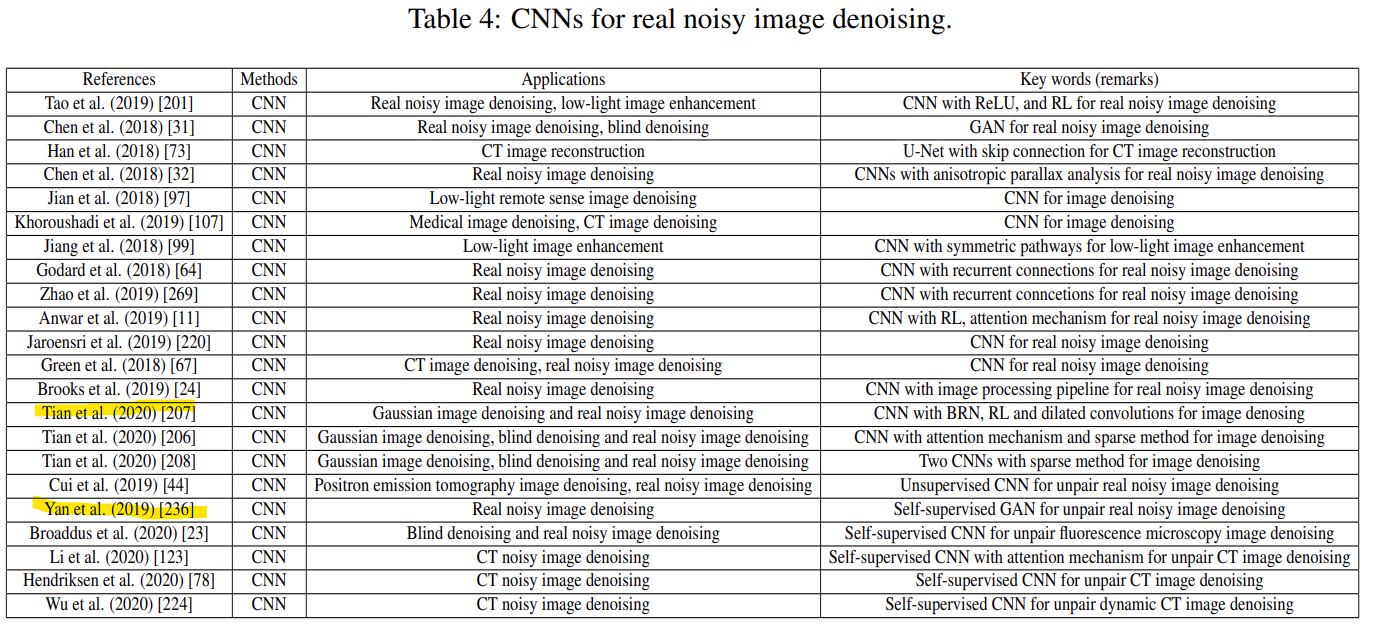
[1] Tian, Chunwei, et al. "Deep learning on image denoising: An overview." Neural Networks 131 (2020): 251-275.인용수 : 726
리뷰 이유 : denoising review paper 중에 인용수가 높음.

Introduce
이 논문의 introduce 구성은 다음과 같음.
1) denoising의 필요성 언급
2) denoising 기술 발전
고전적 방법 -> 머신러닝 방법 -> 딥러닝 방법
3) 논문의 전반적인 세션 언급
하나씩 살펴보도록 하자.
1) denoising의 필요성
전송과 압축 과정에서 이미지 손상이 감.
저하된 이미지에서 깨끗한 이미지로 만들기 위해서는 잡음 제거 기술이 반드시 필요함.
2) denoising 기술 발전
- 고전적 방법
- 비선형 필터
- 적응형 비선형 필터
단점) 정확도가 떨어짐
- 머신러닝 방법
- NCSR
- MRF
- LSSC
- CSF
- TNRD
- GHEP
단점) 각 데이터마다 hyper-parameter가 다름
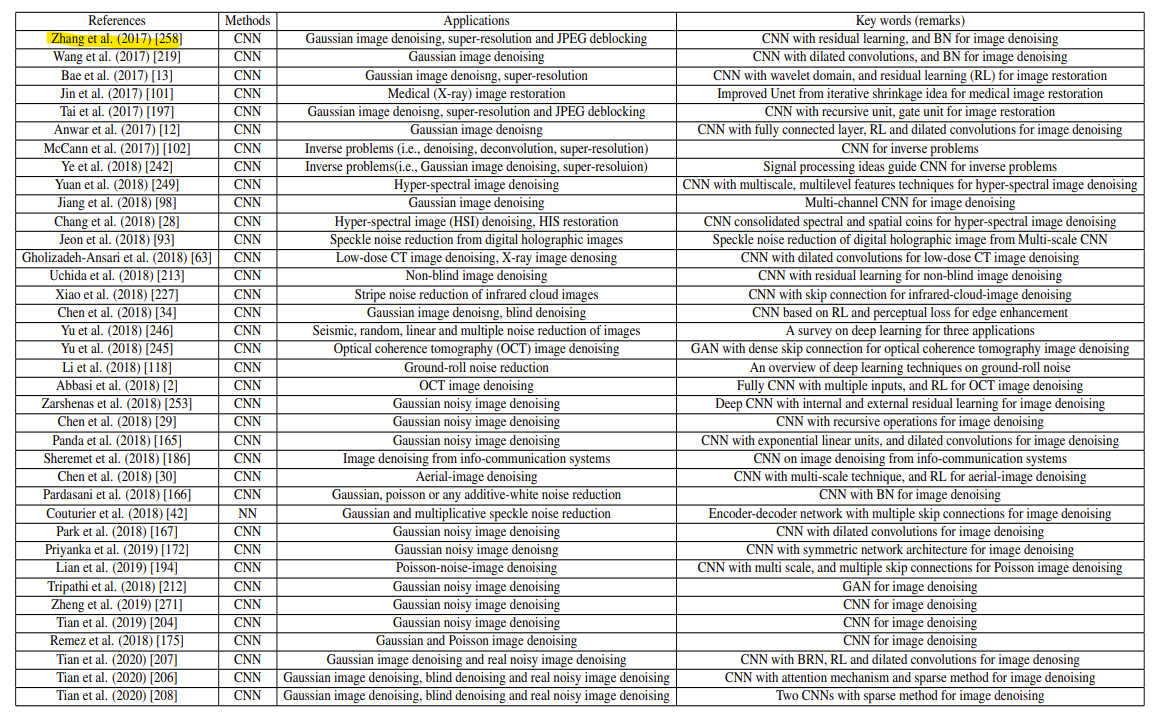
- 딥러닝 방법
딥러닝 기술이 이미지 처리에 처음 사용된 것은 1980년대이며, 이후 딥러닝이 발전하기 시작하고 CNN이 제안되면서 denoising 분야에도 쓰이기 시작했음.- CEEN
- FFDNet
- GAN
- GCBD
- CBDNet
- DPSR
등등
3) 논문의 전반적인 흐름
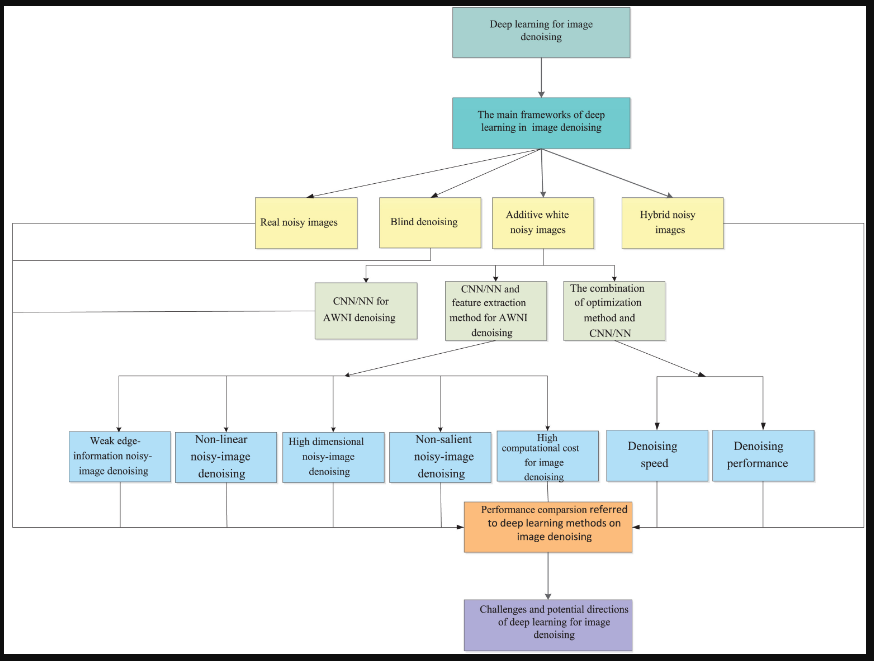
논문은 크게 세션이 6까지 나눠짐.
세션 2. 딥러닝 프레임워크 설명
세션 3. 이미지 DENOISING 딥러닝 범주와 방법 비교, 분석
(그림에서 초록색, 파란색 부분)
세선 4. denoising 방법의 성능 비교
세션 5. 남은 과제와 잠재적인 연구 방향 논의
세션 6. 저자의 결론
여기서 이제 주로 세션 3의 대표 모형에 대해서 살펴보려고 함.
딥러닝 프레임워크 설명 (세션 2)
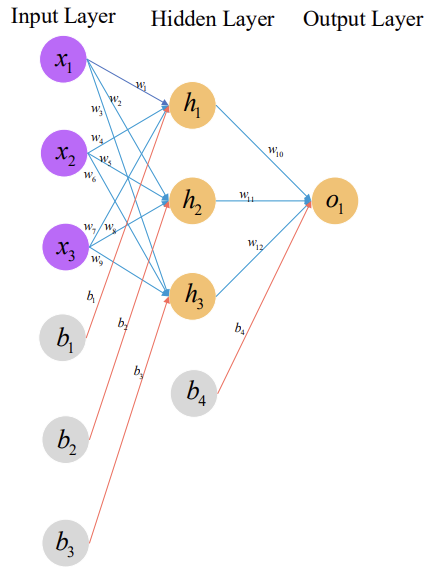
딥러닝에 대한 전반적인 설명이 그려진 그림임.
딥러닝은 크게 input layer, hidden layers, output layer로 구성되고 최종적으로 어떤 것을 분류하거나 회귀하는 형태로 모델링이 진행됨.
일반적인 딥러닝에서의 계산과정을 식으로 나타내면 다음과 같음.
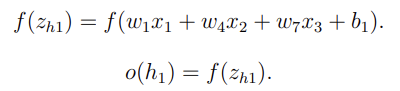
굳.
이 논문에서는 대표적은 CNN 모형들에 대해서도 언급을 함.
-
VGG

-
GoogLeNet
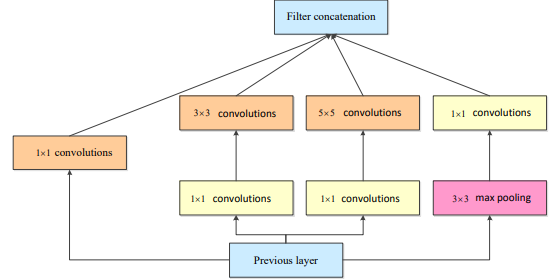
-
ResNet
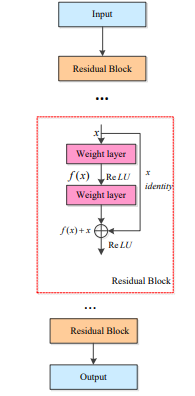
-
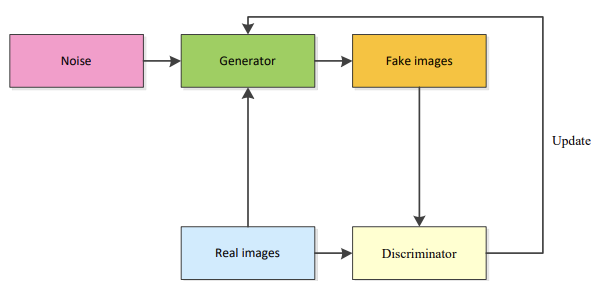
GAN
이미지 노이즈 제거의 딥러닝 기술 (세션 3)
세션 3에서는 이미지 노이즈 제거를 위한 딥러닝 기술을 소개함.
실제 데이터에서는 이미지 noise를 눈으로 보기 어렵기 때문에 여러 noise를 고의로 추가한 후 제거하는 식으로 denoising 연구가 진행됨.
여기에서는 크게 3가지 노이즈에 대한 소개와 딥러닝 기술이 서술되어져 있음.
- AWNI(additive white noisy images, 추가 백색 잡음 이미지)
실제 noise 이미지가 부족하기 때문에 고의적으로 잡음을 추가하고 제거하는 연구 방향을 많이 선택함. 이때 주로 사용되는 잡음의 한 종류임.
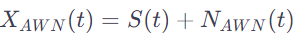 GPT에 물어본 백색 잡음에 대한 식은 다음과 같음.
GPT에 물어본 백색 잡음에 대한 식은 다음과 같음.
신호 s를 x로 표현할 때 백색 잡음을 추가함.(t는 신호)
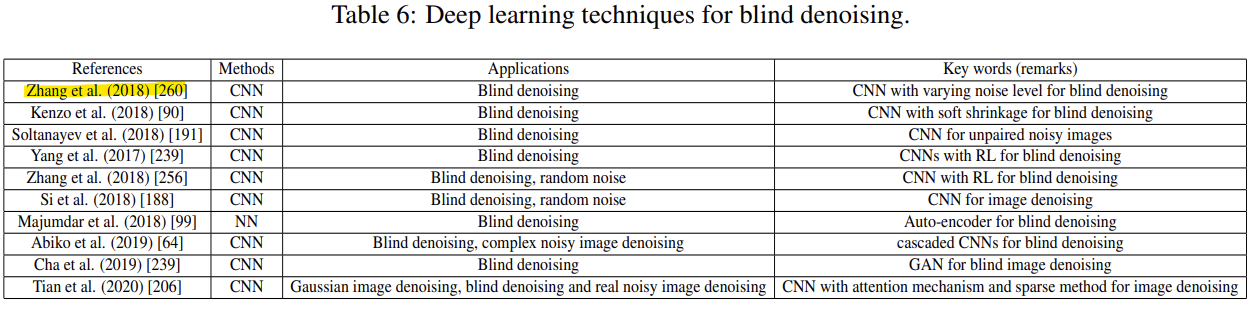
- Blind noise
이 잡음은 일반적으로 일부 특성, 특징 또는 매개변수를 알 수 없거나 쉽게 측정할 수 없는 잡음을 의미함. 즉, 잡음에 대한 사전 지식을 알 수 없는 잡음을 의미함.
감이 좀 안잡혀서, 깃허브에 쳐봄.
# 링크 : https://github.com/zsyOAOA/VDNet/blob/master/demo_test_simulation.py
# 값 정규화
sigma = 10/255.0 + (sigma-sigma.min())/(sigma.max()-sigma.min()) * ((75-10)/255.0)
# 크기 변환
sigma = cv2.resize(sigma, (W, H))
# 잡음 생성
noise = np.random.randn(H, W, C) * sigma[:, :, np.newaxis]
# 잡음 추가
im_noisy = (im_gt + noise).astype(np.float32)
im_noisy = torch.from_numpy(im_noisy.transpose((2,0,1))[np.newaxis,])- Hybrid noise
안녕하세요 ?
각 noise나 모형 별로 인기 있는 denoising 딥러닝 기술을 살펴봄.
인기 있는 이미지 제거 딥러닝 기술
- BM3D(blocking-matching 3d filtering, 2007)
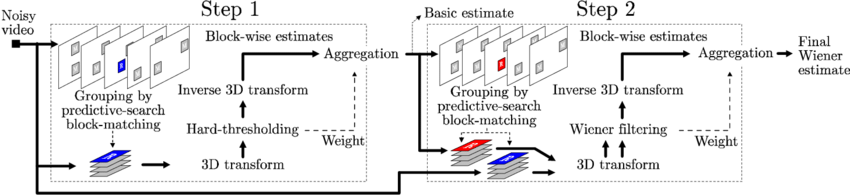
출처 : Dabov, Kostadin & Foi, Alessandro & Egiazarian, Karen. (2007). Video denoising by sparse 3D transform-domain collaborative filtering. 15th European Signal Processing Conference (EUSIPCO). 1.
참조 블록(reference block)과 비슷한 블록들을 구해서 3차원 그룹으로 정렬하고 선형변환을 실행한 후에 임계치에 못 미치는 값을 제거한 다음 역변환을 실행하여 잡음을 제거하는 방법임.
- WNNM(weighted nuclear norm minimization, 2014)
얘도 블록 기반 알고리즘인데, 가중치를 부여한 nuclear norm minimization을 이용해서 이미지 잡음을 반복적으로 제거하는 알고리즘임.
-
TNRD(trainable nonlinear reaction diffusion, 2015)
-
DnCNN(2017)
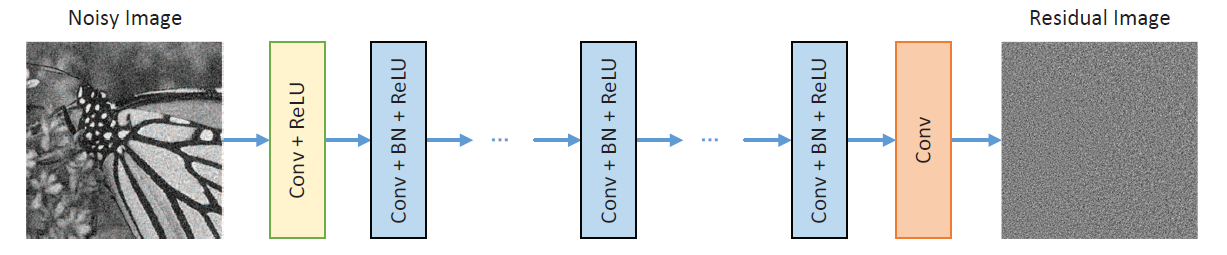
이 모델은 잡음을 출력하는 모델임. 식으로 나타내면 다음과 같음.
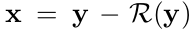
여기서 x는 noisy image이고 y는 clean image, R(y)는 noise를 나타냄.
- FFDNet(fast and flexible solution Net, Zhang et al, 2018)
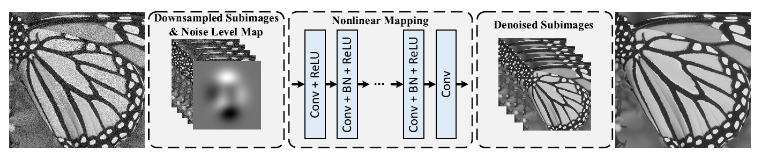
Noise level map
잡음이 있는 영상과 잡음 수준을 함께 input으로 넣음.
Nonlinear mapping
DnCNN 모형과 비슷한 네트워크 + 마지막에 dilated convolution 추가
Denoised subimages
downsampling과 "서브"샘플링 때문에 시간을 많이 줄일 수 있음.
- BRDNet(batch renormalization denoising network, Tian et al, 2020)
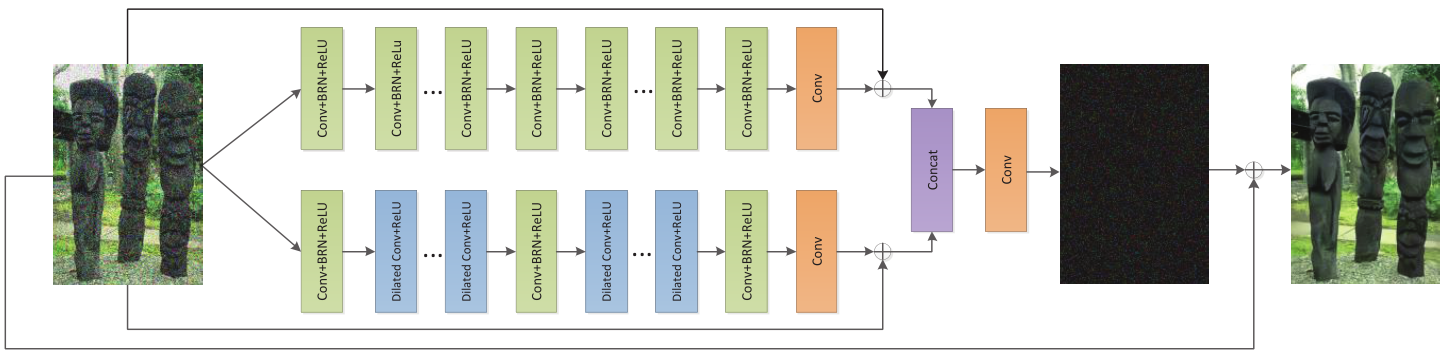
출처. https://github.com/hellloxiaotian/BRDNet
1) CNN 너비를 늘려 학습 능력 향상
2) 배치 재정규화
3) Dilated convolution을 사용하여 수용 필드 확대
- SCGAN(self-consistent, Yan et al, 2019)
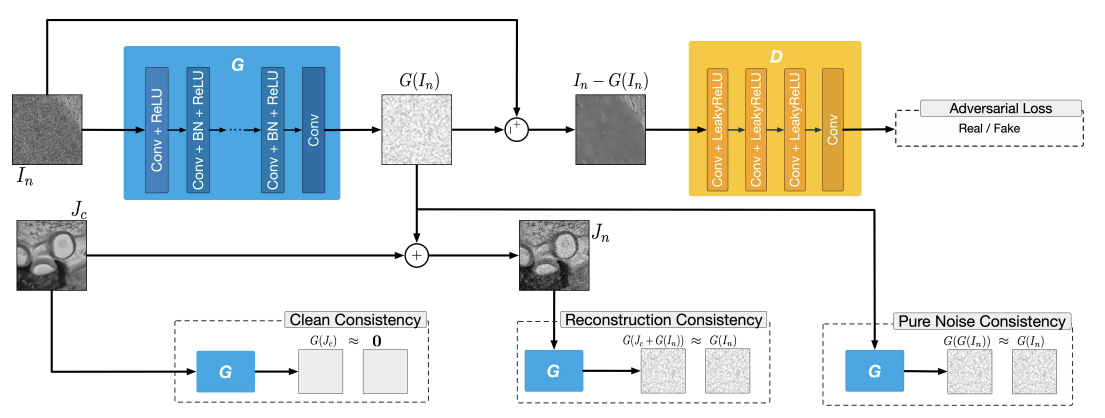
비지도 잡음 모델링을 가능하게 해준 GAN 모형.
여기 이 모형은 서로 보완적인 3가지 제약이 존재.
1) Clean consistency
잡음 모형이 입력에 대해 0 응답을 생성하는 식으로 학습이 진행됨.
2) Reconstruction consistency
순수 잡음이 입력될 때, 동일한 잡음이 출력되야 함.
3) Pure noise consistency
깨끗한 이미지를 입력하면 순수한 노이즈를 생성해야 함.
- DudeNet(denoising dual CNN, 2020)
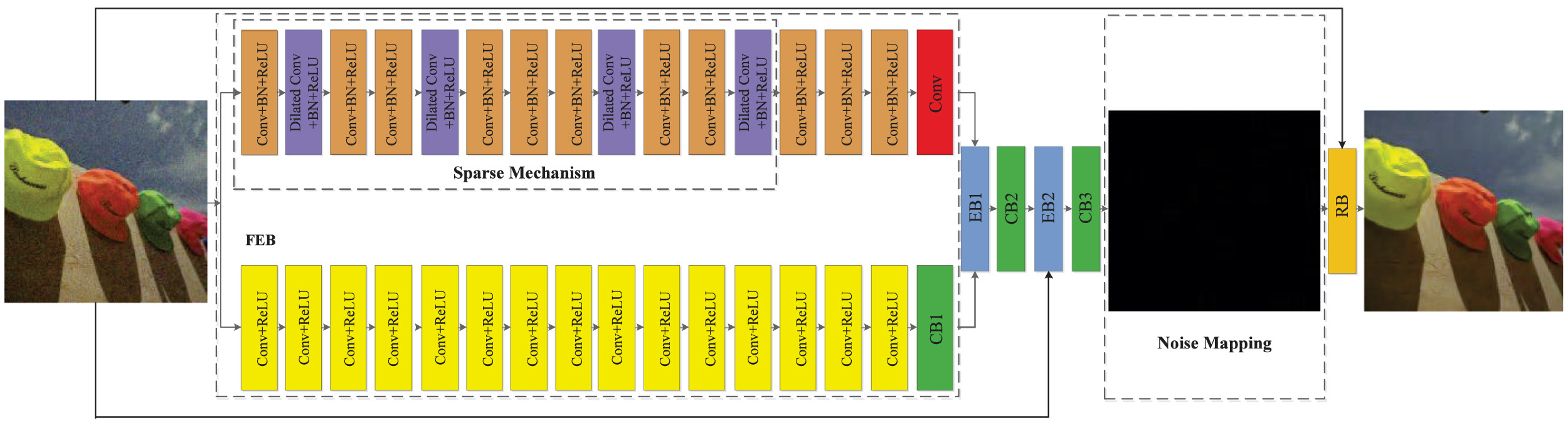
4개의 block이 함께 특징을 추출함.
- FEB(feature extraction block)
2개의 하위 네트워크를 통해 전역 및 로컬 특징을 추출함. - EB(enhancement block, 향상 블록)
글로벌 및 로컬 기능을 수집하고 융합하여 후자 네트워크에 대한 정보 보완을 제공함. - CB(compression block, 압축 블록)
추출된 정보를 정제하고 네트워크를 압축함. - RB(reconstruction block, 재구성 블록)
잡음이 제거된 이미지를 재구성함.
결론
뒤에 다른 세션이 있지만, 다양한 데이터셋에 대해서 결과를 정리함.
실제 잡음 제거를 위한 여러 딥러닝 기술에 사용해볼 내용으로는 다음과 같음.
1) 수용 영역을 확대하면 더 많은 정보를 얻을 수 있음. ex) dilated convolution
2) Prior knowledge를 사용하면 정확한 특징을 얻을 수 있음.
3) residaul block(잔여 연산)과 recursive operation(재귀 연산)을 이용하면 로컬 정보와 글로벌 정보를 결합할 수 있고 이를 통해 잡음을 잘 필터링할 수 있음.
4) 단일 처리 방법을 사용하여 잡음을 필터링할 수 있음.
5) Data augmentation은 학습에 중요한 포인트가 될 수 있음.
6) Transfer learning을 이용.
7) 캡쳐된 이미지에 노이즈가 미치는 영향을 최소화하여 실험해볼 것.
+pca, cnn 같은 차원 축소 방법도 융합!
위 논문들의 denoising 딥러닝 단점들도 함께 나열해줌.
1) 네트워크가 깊어지면 메모리가 많이 듦 + 시간이 오래 걸림.
2) 심층적인 잡음 제거 네트워크는 페어링되지 않은 잡음 이미지에 대해 "안정적인" 솔루션이 아님.
3) 실제 너무 잡음이 많게 캡쳐된 이미지는 훈련 샘플에 부적절함.
4) Deep CNN은 Unsupervised 잡음 제거 작업을 해결하기 어려움.
5) PSNR, SSIM이 좋은 평가 방법이 아닐 수 있음.
본인 데이터에 잡음 수준과 denoising 방법들을 비교해보면서 정리하면 좋을 것 같음.

stable diffusion을 공부하고 있어서 내용이 도움되었습니다~ 감사합니당