지난 포스트에서 수집한 데이터셋을 가지고 LSTM으로 학습을 진행하고 결과까지 확인해보려고 한다.
데이터 셋
- 다음과 같이 .npy 파일로 데이터가 생성되었다.
LSTM 학습 (train.ipynb)
actions = [
'a',
'b',
'c'
]
data = np.concatenate([
np.load('dataset/seq_a_1650133564.npy'),
np.load('dataset/seq_b_1650133564.npy'),
np.load('dataset/seq_c_1650133564.npy')
], axis=0)
data.shape-> 만들었던 데이터 셋을 로드하고 하나로 합쳐준다.
x_data = data[:, :, :-1]
labels = data[:, 0, -1]
print(x_data.shape)
print(labels.shape)-> 데이터셋에는 label값이 포함되어있다. 마지막값이 label값이기 때문에 빼주고, 마지막 값만 label로 만들어 분리한다.
from tensorflow.keras.utils import to_categorical
y_data = to_categorical(labels, num_classes=len(actions))
y_data.shape-> One-hot encoding을 한다. keras에 to_categorical을 사용
✋여기서 잠깐!
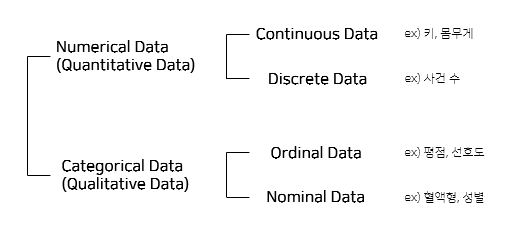
Categorical Data란?
- 자료는 일반적으로 수치형 자료(numerical data)와 범주형 자료(categorical data)로 구분이 된다.
- 수치형 자료(numerical data)
- 관측된 값이 수치로 측정되는 자료를 말한다. (ex. 키, 몸무게, 성적, 사건 수 등등)
- 양적 자료(quantitative data)라고도 불린다.
- 수치형 자료를 관측되는 값의 성질에 따라 다시 연속형 자료(continuous data)와 이산형 자료(discrete data)로 구분된다.
- 범주형 자료(categorical data)
- 관측 결과가 몇 개의 범주 또는 항목의 형태로 나타나는 자료를 말한다. (ex. 성별(남, 여), 선호도, 혈액형, 지역 등이 있다.)
- 질적 자료(qualitative data)라고도 불린다.
- 범주형 자료는 수치형 자료처럼 표현할 수 있다. (ex. 선호도에서 좋다를 3, 보통을 2, 싫다를 1로 표현) 하지만 수치형 자료처럼 각 선호도의 크기가 1만큼만 차이난다는 것도 아니고 좋다와 싫다가 3배 차이난다는 것도 아니다.
- 순위형 자료(ordinal data)와 명목형 자료(nominal data)로 구분할 수 있다. 순위형 자료는 선호도처럼 자료 내에 순서가 존재하고 명목형 자료는 혈액형처럼 순서가 존재하지 않는다.
- 수치형 자료(numerical data)
Categorical Encoding, One-Hot Encoding이란?
- 머신러닝 알고리즘이 데이터를 이해하기 위해서 categorical data(text)를 numerical data로 바꾸는 처리 과정
- categorical encoding에는 크게 Label Encoding과 One-Hot Encoding으로 분류된다.
- Label Encoding은 알파벳 순서로 정렬하고, 정렬한 기준으로 번호를 매긴다. 하지만 label encoding은 명목형 자료형에서는 행크된 숫자정보가 모델에 잘못 반영될 수 있다는 단점이 있다.
- One-Hot Encoding은 n개의 범주형 데이터를 n개의 비트(0, 1) 벡터로 표현한다. 쉽게 말해서 한개의 요소만 true, 나머지 요소는 false로 만들어 주는 기법이다. 하지만 One-Hot Encoding은 변수 하나의 결과가 다른 변수의 도움으로 쉽게 예측되어 질 수 있다는 단점이 있는데 이를 Dummy Variable Trap이라고 한다.
- One-Hot Encoding은 명목형 자료이고 고유값의 개수가 많지 않을 때 사용하고, Label Encoding은 순위형 자료일 때 사용한다.
from sklearn.model_selection import train_test_split
x_data = x_data.astype(np.float32)
y_data = y_data.astype(np.float32)
x_train, x_val, y_train, y_val = train_test_split(x_data, y_data, test_size=0.1, random_state=2021)
print(x_train.shape, y_train.shape)
print(x_val.shape, y_val.shape)-> training set과 test set을 나눠준다. sklearn의 train_test_split 사용
training set은 90%, test set은 10%로 설정했다.
- sklearn(scikit-learn) 설치 방법
- cmd에
pip install scikit-lean
- cmd에
from tensorflow.keras.models import Sequential
from tensorflow.keras.layers import LSTM, Dense
model = Sequential([
LSTM(64, activation='relu', input_shape=x_train.shape[1:3]), # node 개수 64개
Dense(32, activation='relu'), # node 개수 32개
Dense(len(actions), activation='softmax')
])
model.compile(optimizer='adam', loss='categorical_crossentropy', metrics=['acc']) # loss='categorical_crossentropy -> 3개의 action 중 어떤 건지 모델에게 추론하게 함
model.summary()-> model 정의, Sequential API를 사용했고 LSTM과 DENSE를 연결한다.
from tensorflow.keras.callbacks import ModelCheckpoint, ReduceLROnPlateau
history = model.fit(
x_train,
y_train,
validation_data=(x_val, y_val),
epochs=200,
callbacks=[
ModelCheckpoint('models/model.h5', monitor='val_acc', verbose=1, save_best_only=True, mode='auto'),
ReduceLROnPlateau(monitor='val_acc', factor=0.5, patience=50, verbose=1, mode='auto')
]
)-> 학습 과정, 200번 epoch을 돈다. 학습이 완료되면 model을 저장한다.
- 학습을 진행했는데 참고 자료에서는 정확도가 100프로가 나왔는데 나는 정확도가 약 67프로밖에 나오지 않아서 이상함을 느끼고 한 번 더 진행해보았다.

- 두번째 시도에는 약 93프로가 나왔다.

- ❓ 학습할 때마다 정확도가 다르게 나오는 이유는 무엇일까?
✋여기서 잠깐!
epoch이란?
One Epoch is when an ENTIRE dataset is passed forward and backward through the neural network only ONCE- 한 번의 epoch는 인공 신경망에서 전체 데이터 셋에 대해 forward pass/backward pass 과정을 거친 것을 말함. 즉, 전체 데이터 셋에 대해 한 번 학습을 완료한 상태)
import matplotlib.pyplot as plt
fig, loss_ax = plt.subplots(figsize=(16, 10))
acc_ax = loss_ax.twinx()
loss_ax.plot(history.history['loss'], 'y', label='train loss')
loss_ax.plot(history.history['val_loss'], 'r', label='val loss')
loss_ax.set_xlabel('epoch')
loss_ax.set_ylabel('loss')
loss_ax.legend(loc='upper left')
acc_ax.plot(history.history['acc'], 'b', label='train acc')
acc_ax.plot(history.history['val_acc'], 'g', label='val acc')
acc_ax.set_ylabel('accuracy')
acc_ax.legend(loc='upper left')
plt.show()-> 학습이 완료되면 그래프를 그린다.
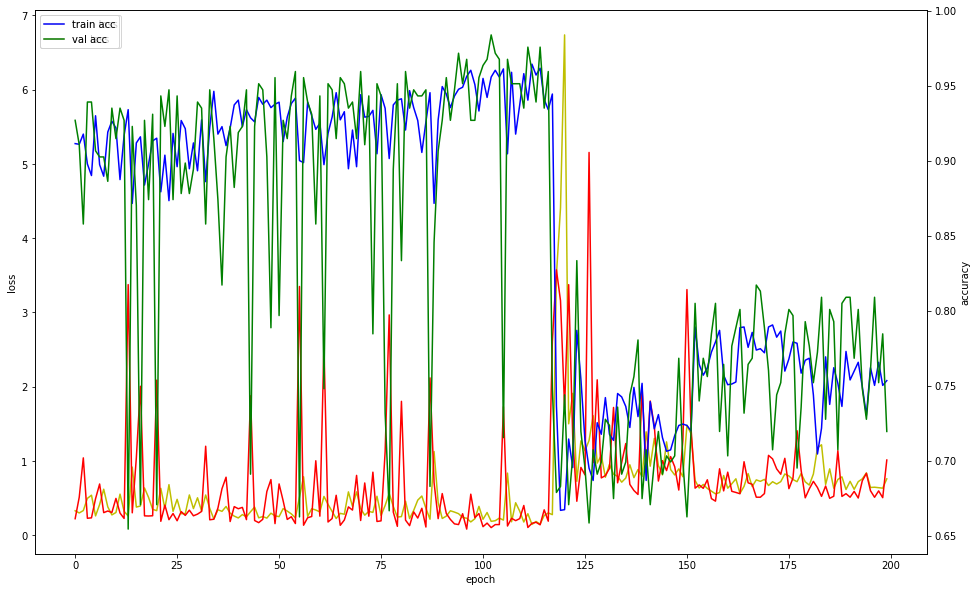
- 그런데 충격적인 그래프를 보았고... 나는 충격을 먹었다...
Test (test.py)
- 그럼에도 불구하고 test를 진행해보고 싶어서 test.py를 진행해보았다.
import cv2
import mediapipe as mp
import numpy as np
from tensorflow.keras.models import load_model
actions = ['a', 'b', 'c']
seq_length = 30
model = load_model('models/model.h5')
# MediaPipe hands model
mp_hands = mp.solutions.hands
mp_drawing = mp.solutions.drawing_utils
hands = mp_hands.Hands(
max_num_hands=1,
min_detection_confidence=0.5,
min_tracking_confidence=0.5)
cap = cv2.VideoCapture(0)
# w = int(cap.get(cv2.CAP_PROP_FRAME_WIDTH))
# h = int(cap.get(cv2.CAP_PROP_FRAME_HEIGHT))
# fourcc = cv2.VideoWriter_fourcc('m', 'p', '4', 'v')
# out = cv2.VideoWriter('input.mp4', fourcc, cap.get(cv2.CAP_PROP_FPS), (w, h))
# out2 = cv2.VideoWriter('output.mp4', fourcc, cap.get(cv2.CAP_PROP_FPS), (w, h))
seq = []
action_seq = []
while cap.isOpened():
ret, img = cap.read()
img0 = img.copy()
img = cv2.flip(img, 1)
img = cv2.cvtColor(img, cv2.COLOR_BGR2RGB)
result = hands.process(img)
img = cv2.cvtColor(img, cv2.COLOR_RGB2BGR)
if result.multi_hand_landmarks is not None:
for res in result.multi_hand_landmarks:
joint = np.zeros((21, 4))
for j, lm in enumerate(res.landmark):
joint[j] = [lm.x, lm.y, lm.z, lm.visibility]
# Compute angles between joints
v1 = joint[[0,1,2,3,0,5,6,7,0,9,10,11,0,13,14,15,0,17,18,19], :3] # Parent joint
v2 = joint[[1,2,3,4,5,6,7,8,9,10,11,12,13,14,15,16,17,18,19,20], :3] # Child joint
v = v2 - v1 # [20, 3]
# Normalize v
v = v / np.linalg.norm(v, axis=1)[:, np.newaxis]
# Get angle using arcos of dot product
angle = np.arccos(np.einsum('nt,nt->n',
v[[0,1,2,4,5,6,8,9,10,12,13,14,16,17,18],:],
v[[1,2,3,5,6,7,9,10,11,13,14,15,17,18,19],:])) # [15,]
angle = np.degrees(angle) # Convert radian to degree
d = np.concatenate([joint.flatten(), angle])
seq.append(d)
mp_drawing.draw_landmarks(img, res, mp_hands.HAND_CONNECTIONS)
if len(seq) < seq_length:
continue
input_data = np.expand_dims(np.array(seq[-seq_length:], dtype=np.float32), axis=0)
y_pred = model.predict(input_data).squeeze()
i_pred = int(np.argmax(y_pred))
conf = y_pred[i_pred]
if conf < 0.9:
continue
action = actions[i_pred]
action_seq.append(action)
if len(action_seq) < 3:
continue
this_action = '?'
if action_seq[-1] == action_seq[-2] == action_seq[-3]:
this_action = action
cv2.putText(img, f'{this_action.upper()}', org=(int(res.landmark[0].x * img.shape[1]), int(res.landmark[0].y * img.shape[0] + 20)), fontFace=cv2.FONT_HERSHEY_SIMPLEX, fontScale=1, color=(255, 255, 255), thickness=2)
# out.write(img0)
# out2.write(img)
cv2.imshow('img', img)
if cv2.waitKey(1) == ord('q'):
break- 하지만 test.py에서는 다음과 같은 오류가 생겼다. model.h5파일이 존재하지 않는다는 이야기인데 model.h5는 models 하위 폴더에 잘 존재하고있고, train.ipynb를 실행할 때는 잘 돌아갔었는데 갑자기 오류가 나서 당황했다.
Traceback (most recent call last):
File "c:/Users/JH/Documents/VSCodeSonsuProjects/GESTURE_RECOGNITION/test.py", line 9, in <module>
model = load_model('model.h5')
File "C:\Users\JH\AppData\Local\Programs\Python\Python38\lib\site-packages\tensorflow\python\keras\saving\save.py", line 211, in load_model
loader_impl.parse_saved_model(filepath)
File "C:\Users\JH\AppData\Local\Programs\Python\Python38\lib\site-packages\tensorflow\python\saved_model\loader_impl.py", line 111, in parse_saved_model
raise IOError("SavedModel file does not exist at: %s/{%s|%s}" %
OSError: SavedModel file does not exist at: model.h5/{saved_model.pbtxt|saved_model.pb}모델을 학습하는 것부터 다시 해보기로 했다.
- 이번에는 약 96%의 정확도가 나왔다.

- 그래프는 아까의 그래프와는 완전히 다른 모습을 보인다.
❓ 하지만 학습이 100%의 정확도가 나오지 않았는데 왜 그래프의 모양이 저렇게 되어있는지가 궁금하다.
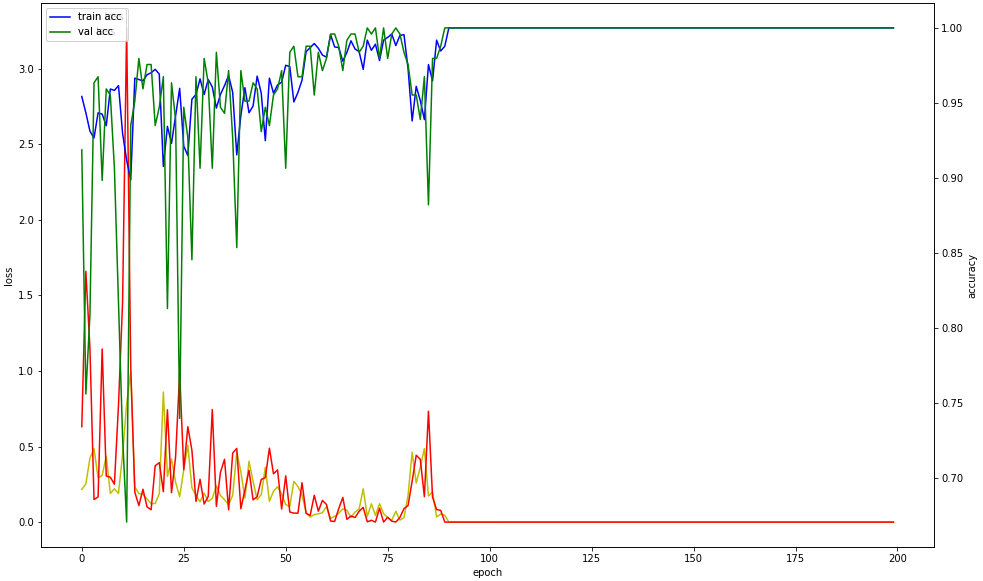
- 하지만 test.py에서 똑같은 오류가 났다. model.h5 파일을 이동도 시켜보고 경로도 바꿔봤지만 똑같았다.
Trouble Shooting
#1
OSError: SavedModel file does not exist at: model.h5/{saved_model.pbtxt|saved_model.pb}-
해결책 1.
pip install h5py-> 이미 설치되어있다.
https://stackoverflow.com/questions/61699140/oserror-savedmodel-file-does-not-exist-at-dnn-mpg-model-h5-saved-model-pbt/65014543#65014543
https://arca.live/b/programmers/44902070?p=1 -
해결책 2. NodeJS에서 실행하는 PythonShell에서는 H5모델이 아닌 Savedmodel만 읽을 수 있다.
https://blog.naver.com/PostView.naver?blogId=heyji1230&logNo=222146936643&redirect=Dlog&widgetTypeCall=true&directAccess=false
https://www.tensorflow.org/guide/keras/save_and_serialize?hl=ko-
따라서 위의 train에서는 모델을 h5로 저장하고 있기 때문에 savedmodel로 변환해주는 코드를 train.ipynb에 추가했다.
import tensorflow as tf model = tf.keras.models.load_model('model.h5') tf.saved_model.save('model')-> 이 코드를 실행하면 model이라는 폴더가 생성되고 내부에 assets폴더와 variables폴더, saved_model.pb 파일이 생성된다.
-
-
하지만 여전히 같은 오류가 발생했다. 구글링을 하다보니 savedModel을 load하는 함수와 h5를 load하는 함수가 다르다는 생각이 들었고 해당 내용을 찾아봤다.
https://www.tensorflow.org/api_docs/python/tf/saved_model/load : Loading Keras models을 참고했다.
test.py에서 model을 load 하는 코드를 다음 코드로 수정하였다.model = tf.keras.Model(...)
=> 오류 해결!
#2
- 위의 오류가 해결되고 실행 후 웹캠까지 켜졌지만, 수어 동작을 하면 다음과 같은 오류가 뜨면서 종료된다.
NotImplementedError: When subclassing the `Model` class, you should implement a `call` method.- 해당 오류는 call method가 없어서 뜨는 것이라고 한다. 다양한 자료들이 call method를 추가함으로써 오류를 해결할 수 있다고 한다.
https://lifesaver.codes/answer/subclass-of-tf-keras-model-throws-notimplementederror-when-fit-with-custom-data-43173
def call(self, inputs, *args, **kwargs):
return self.model(inputs)-> 출처
def call(self, inputs):
self.total.assign_add(tf.reduce_sum(inputs, axis=0))
return self.total-> 출처
import tensorflow as tf
class MyModel(tf.keras.Model):
def __init__(self):
super().__init__()
self.dense1 = tf.keras.layers.Dense(4, activation=tf.nn.relu)
self.dense2 = tf.keras.layers.Dense(5, activation=tf.nn.softmax)
def call(self, inputs):
x = self.dense1(inputs)
return self.dense2(x)
model = MyModel()-> 출처
오류해결 진행중
참고
[기초통계] 수치형 자료(numerical data)와 범주형 자료(categorical data)
머신 러닝 - epoch, batch size, iteration의 의미
