- 이 글은 가장 기본적인 basic k-means에 대해 다루고 있습니다
K-means Clustering
최초의 K개의 초기 지점(initial centroids)을 선택한다 for ( centroids가 변경되지 않을 때까지 ) 각각의 centroid에서 가까운 지점들을 하나의 cluster로 묶는다. cluster 내의 point들의 위치를 토대로 새로운 centroid를 선택한다 return
위의 과정을 수행하는 데에 있어서, initial centroid를 선택하는 것은 매우 중요한 문제이다. 이 지점을 어떻게 선택하느냐에 따라서 reasonable한 clustering이 도출될 수도 있고, 전혀 그렇지 않을 수도 있기 때문이다. 따라서 이 최초 지점을 단지 랜덤하게 고르는 것은 매우 위험한 발상이 된다.
그렇다면 initial centroid를 고르는 방법론에는 어떠한 것들이 있는지 알아보자.
Initial Centroids Problem
1. Multiple Runs
말 그대로, Reasonable한 결과를 도출할 때까지 계속 clustering을 진행하는 방법이다. 하지만 이러한 방법은 분석을 무한정 실행해야 하므로 computing resource를 크게 낭비하는 방법일 뿐만 아니라, 결과값이 reasonable한지를 어떻게 평가해야 하는지의 문제도 생겨나게 된다.
2. Sampling & Using Hierarchical Clustering
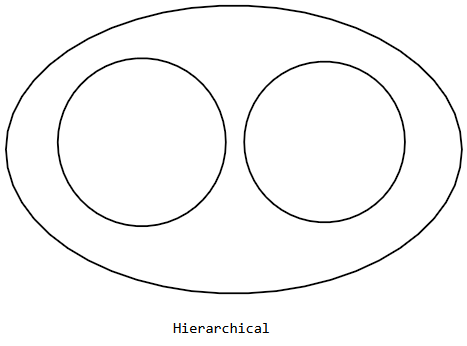
hierarchical clustering은 overlapping이나 non-exclusive clustering과는 달리, 여러 cluster 간에 포함관계를 가지는 clustering을 말한다.
-
Non-Exclusive
-
Overlapping
-
Hierarchical
두 번째 방법은 다음과 같다.
- 주어진 Data Point에서 n개의 sample을 추출한다
- 이 Sample들에 대해 Hierarchical Clustering을 진행한다
- Sampling이 완료된 cluster들의 centroid들을 initial centroid로 사용한다.
다만 개인적으로는, Hierarchical Clustering을 진행할 때에도 initial centroid를 어떻게 선택하는가에 대한 문제는 여전히 존재하는 게 아닐까 하는 생각이 들었다. Sampling을 통해 표본의 수를 줄이면 centroid 선택이 더 쉬워지는 것인지, 아직 의문점이 남아 있다.
3. Select More than K & Filtering
말 그대로 K개보다 더 많은 initial centroid를 선택한 후, 가장 괜찮아 보이는 K를 선별하는 방법이다. 이때 서로 멀리 떨어져 있는 지점들을 선택하게 된다. (서로 붙어 있는 centroid는 선택하지 않는다)
4. Postprocessing Clusters
이 방법은 우선 K보다 많은 수의 cluster를 선택한 후 clustering을 진행하고, 사후 평가를 통해 cluster의 수를 줄여나가는 방법을 말한다. 이때 cluster를 줄여나가는 방법에는 다음의 3가지가 있다.
- Split : Reasonable하지 못한 cluster를 둘로 나누는 방법
- Merge : 두 cluster를 서로 병합하는 방법
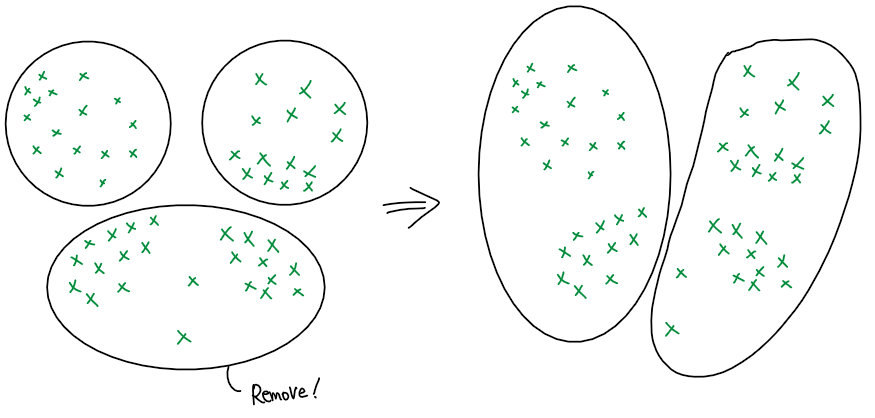
- Disperse : Reasonable하지 못한 cluster를 삭제하고, 해당 cluster에 있던 data object들을 기존의 다른 cluster로 재편입하는 방법
이때 Split은 cluster의 수를 늘리는 방법에 해당하므로, split이 진행된 후에는 merge가 반드시 필요하게 된다.
- Disperse (그림만 보면 딱히 효과가 없어보이지만, 일단 그러려니 해 주세요..ㅠㅠ)
5. Bisecting K-means
- 내용이 길기 때문에, 다음에 정리하려고 합니다
