자료구조란?
데이터를 일정한 규칙에 따라 체계적으로 저장하고 관리하는 방식
데이터를 효과적으로 다루기 위해 만들어진 다양한 규칙과 구조가 자료구조
왜 자료구조를 사용할까?
- 효율적인 데이터 관리
- 많은 양의 데이터를 효율적으로 저장하고 찾을 수 있음
- 데이터의 추가, 삭제, 검색을 더 빠르게 할 수 있음
- 메모리 효율성
- 데이터를 구조화함으로써 메모리를 효율적으로 사용할 수 있음
- 프로그램의 성능을 향상시킬 수 있음
자료구조의 종류와 특징
- 기본 자료구조
- 배열(Array): 데이터를 순서대로 저장하는 방식
- 예: [10, 20, 30, 40]
- 연결 리스트(Linked List): 데이터가 노드(Node)로 연결된 구조
- 예: [10] -> [20] -> [30] -> [40]
- 스택(Stack): 나중에 넣은 것이 먼저 나오는 후입선출(LIFO) 방식
- 예: 접시를 쌓고 맨 위에부터 차례대로 꺼내는 방식
- 큐(Queue): 먼저 넣은 것이 먼저 나오는 선입선출(FIFO) 방식
- 예: 놀이공원 줄 서기처럼, 줄의 맨 앞에 있는 사람부터 이용하는 방식
- 응용 자료구조
- 트리(Tree): 계층적 관계로 저장하며, 부모-자식 관계를 표현함
- 예: 파일 탐색기 구조, 가계도
- 그래프(Graph): 데이터 간의 연결 관계를 표현
- 예: 지하철 노선도, 소셜 네트워크
- 해시 테이블(Hash Table): 키-값 쌍으로 데이터를 저장
- 예: 사전에서 단어 뜻 찾기
자료구조 선택하는 법
- 고정된 크기의 데이터를 순서대로 저장하고 빠르게 접근해야 한다면 배열
- 데이터 추가와 삭제가 많다면 연결 리스트
- 데이터를 시간 순서대로 처리해야 한다면 큐
- 데이터가 계층적으로 정리되어 있다면 트리
- 복잡한 관계를 표현해야 한다면 그래프
- 키를 통한 빠른 데이터 검색과 삽입이 필요하고 데이터의 순서가 중요하지 않다면 해시 테이블
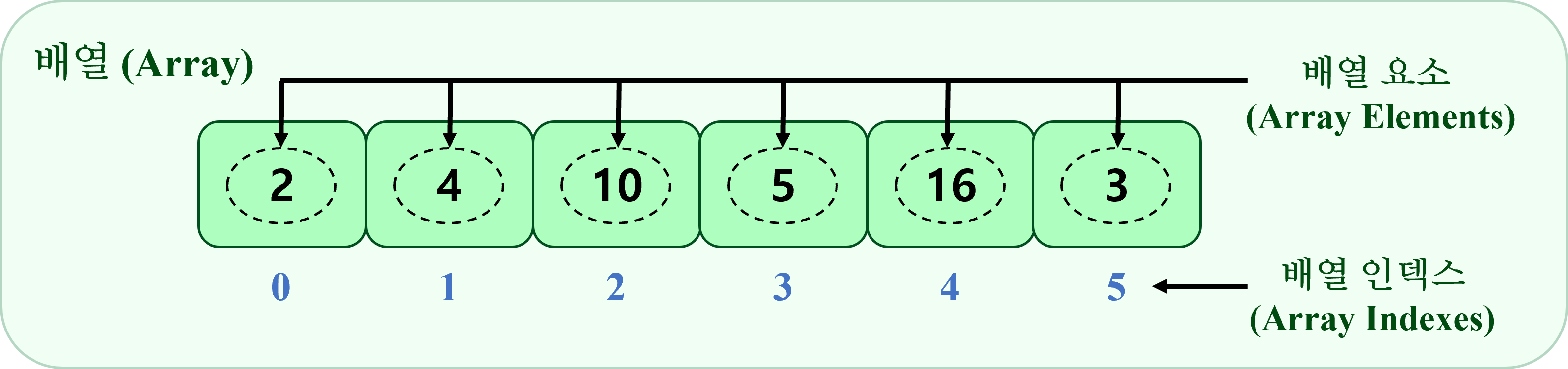
1차원 배열
배열은 동일한 타입의 데이터를 연속된 공간에 저장하는 자료구조
-> 같은 종류의 데이터들을 일렬로 나열한 것
배열의 특징
-
인덱스(Index)를 통한 각 요소 접근
- 배열의 각 요소는 0부터 시작하는 인덱스를 가짐
- 인덱스를 통해 원하는 위치의 데이터에 즉시 접근할 수 있음
- 접근 속도가 매우 빠름(시간복잡도 O(1))
-
고정된 크기
- 배열은 생성 시점에 크기를 지정해야 함
- 한번 생성된 배열의 크기는 변경할 수 없음
- 크기를 변경하려면 새로운 배열을 만들어야함
-
연속된 메모리 공간
- 배열의 데이터는 메모리에 연속적으로 저장됨
- 연속 저장 방식은 메모리 캐시 효율을 높여 전반적인 성능에 도움이 됨
// 배열 선언과 초기화
int[] numbers = new int[5]; // 크기가 5인 정수 배열 생성
int[] scores = {90, 80, 85, 95, 88}; // 초기값과 함께 배열 생성
// 배열 요소 접근
numbers[0] = 10; // 첫 번째 요소에 10 저장
int thirdScore = scores[2]; // 세 번째 요소 값 읽기
// for문을 이용한 배열 순회 (인덱스로 값 참조)
for(int i = 0; i < scores.length; i++) {
System.out.println(scores[i]);
}
// for-each문을 이용한 배열 순회 (직접 값 참조)
for(int score : scores) {
System.out.println(score);
}배열의 탐색 방법
순차 탐색
- 배열의 처음부터 끝까지 순서대로 하나씩 탐색하는 가장 기본적인 탐색 방법
- 정렬되지 않은 배열에서도 사용할 수 있는 범용적인 탐색 방법
동작 원리:
1. 배열의 첫 번째 요소부터 순차적으로 검사
2. 각 요소를 target과 비교하여 일치하는지 확인
3. 발견 즉시 해당 위치 반환 또는 끝까지 못 찾으면 -1 반환
시간 복잡도: O(N)
public class SequentialSearch {
public static int sequentialSearch(int[] arr, int target) {
// 1. 배열의 첫 번째 요소부터 시작
// 1-1. 배열을 순차적으로 탐색하기 위한 반복문 시작
for (int i = 0; i < arr.length; i++) {
// 1-2. 현재 인덱스의 요소에 접근
// 2. 찾고자 하는 값(target)과 현재 요소 비교
// 2-1. target과 현재 요소가 일치하면, 현재 인덱스 반환
if (arr[i] == target) {
return i;
}
// 2-2. 일치하지 않으면, 다음 인덱스로 이동하여 1-2부터 반복
}
// 3. 배열 탐색 완료 후 결과 처리
// 3-1. 배열 끝까지 탐색했는데 찾지 못한 경우 실패(-1) 반환
return -1;
}
public static void main(String[] args) {
// 테스트를 위한 예제 배열과 찾을 값 설정
int[] arr = {4, 2, 7, 1, 9, 3};
int target = 7;
// 순차 탐색 수행 및 결과 출력
int result = sequentialSearch(arr, target);
if (result != -1) {
System.out.println("찾은 위치: " + result);
} else {
System.out.println("값을 찾지 못했습니다.");
}
}
}이진 탐색
- 이진 탐색은 정렬된 배열에서 효율적으로 원하는 값을 찾기 위한 알고리즘
- 순차 탐색과 달리, 매 단계마다 탐색 범위를 절반으로 줄여가며 검색을 수행하므로 더 빠른 결과를 얻을 수 있음
동작 원리:
1. 정렬된 배열의 중간 위치를 찾아 시작
2. 중간값과 목표값 비교:
- 중간값 > 목표값: 왼쪽 부분 배열에서 검색 계속
- 중간값 < 목표값: 오른쪽 부분 배열에서 검색 계속
- 중간값 = 목표값: 검색 성공
시간 복잡도: O(log N)
public class Solution {
private static int binarySearch(int[] arr, int target) {
// 1. 탐색 범위의 시작점과 끝점 설정
// 1-1. left는 배열의 첫 번째 인덱스로 설정
int left = 0;
// 1-2. right는 배열의 마지막 인덱스로 설정
int right = arr.length - 1;
// 2. 탐색 범위가 유효한 동안 반복
while (left <= right) {
// 2-1. 중간 위치 계산
int mid = (left + right) / 2;
// 3. 중간 값과 target 비교 후 처리
// 3-1. 중간 값이 target과 같으면 해당 인덱스 반환
if (arr[mid] == target) {
return mid;
}
// 3-2. 중간 값이 target보다 크면 오른쪽 범위를 줄임
else if (arr[mid] > target) {
right = mid - 1;
}
// 3-3. 중간 값이 target보다 작으면 왼쪽 범위를 줄임
else {
left = mid + 1;
}
}
// 4. 탐색 완료 후 결과 처리
// 4-1. 찾지 못한 경우 실패(-1) 반환
return -1;
}
public static void main(String[] args) {
// 테스트를 위한 정렬된 예제 배열과 찾을 값 설정
int[] arr = {1, 2, 3, 4, 5, 6, 7, 8, 9}; //정렬된 배열이어야 함
int target = 7;
// 이진 탐색 수행 및 결과 출력
int result = binarySearch(arr, target);
if (result != -1) {
System.out.println("찾은 위치: " + result);
} else {
System.out.println("값을 찾지 못했습니다.");
}
}
}투 포인터
- 두개의 포인터(시작점, 끝점)를 이용하여 배열을 탐색하는 방법
- 두 개의 점을 이동시키면서 원하는 값을 찾음
- 연속된 구간의 합이나 특정 조건을 만족하는 부분을 찾을 때 주로 사용
1) 두 수의 합이 특정 값이 되는 쌍 찾기
정렬된 배열 A가 주어질 때, 배열 내에서 두 개의 원소를 선택하여 그 합이 특정 값 target이 되는 두 수의 쌍을 찾는 문제
동작 원리:
1. 정렬된 배열의 양 끝에 포인터(left, right) 배치
2. 두 포인터가 가리키는 값의 합을 target과 비교
- 합 < target: left 포인터를 오른쪽으로 이동(더 큰 값 필요)
- 합 > target: right 포인터를 왼쪽으로 이동(더 작은 값 필요)
시간 복잡도: O(N)
public class Solution {
public static boolean findTwoSum(int[] arr, int target) {
// 1. 포인터 초기화
// 1-1. left 포인터는 배열의 첫 번째 인덱스로 설정
int left = 0;
// 1-2. right 포인터는 배열의 마지막 인덱스로 설정
int right = arr.length - 1;
// 2. 두 포인터가 교차하기 전까지 반복
while (left < right) {
// 2-1. 현재 두 포인터가 가리키는 값의 합 계산
int sum = arr[left] + arr[right];
// 2-2. 합과 목표값 비교
// 3. 합과 목표값 비교 후 포인터 이동
// 3-1. 합이 목표값과 같으면 true 반환 (쌍을 찾음)
if (sum == target) {
System.out.println("찾은 두 수: " + arr[left] + ", " + arr[right]);
return true;
}
// 3-2. 합이 목표값보다 작으면 left 포인터를 오른쪽으로 이동 (더 큰 값 필요)
else if (sum < target) {
left++;
}
// 3-3. 합이 목표값보다 크면 right 포인터를 왼쪽으로 이동 (더 작은 값 필요)
else {
right--;
}
}
// 4. 탐색 완료 후 결과 처리
// 4-1. 목표값을 만드는 쌍을 찾지 못한 경우 false 반환
return false;
}
public static void main(String[] args) {
// 테스트를 위한 예제 배열과 목표 합 설정
int[] arr = {4, 1, 8, 7, 3, 2}; // 정렬되지 않은 배열
int target = 10; // 찾고자 하는 합
// 투 포인터 탐색 수행 및 결과 출력
System.out.println("원본 배열: " + Arrays.toString(arr));
System.out.println("목표 합: " + target);
boolean result = findTwoSum(arr, target);
System.out.println("합이 " + target + "이 되는 두 수가 " +
(result ? "존재합니다." : "존재하지 않습니다."));
}
}2) 연속 부분 수열의 합
0 이상의 정수 배열과 목표 합이 주어졌을 때, 주어진 배열에서 연속된 요소들의 합이 특정 목표 값(Target)과 일치하는 구간의 개수를 찾는 문제
즉, 길이가 N인 수열 A[1], A[2], …, A[N]이 주어질 때, 이 수열의 i번째 원소부터 j번째 원소까지의 합인 A[i] + A[i+1] + … + A[j]가 Target이 되는 경우의 수를 구하는 문제
동작 원리:
1. start, end 포인터로 연속된 부분 수열 인덱스의 시작과 미만을 표현
2. 현재 구간의 합을 target과 비교
- 합 < target: end 포인터 이동하여 구간 확장
- 합 > target: start 포인터 이동하여 구간 축소
시간 복잡도: O(N)
import java.util.Arrays;
public class Solution {
public static int findExactSum(int[] arr, int target) {
// 1. 포인터와 현재 합계, 결과값 초기화
// 1-1. start 포인터는 배열의 첫 번째 인덱스로 설정
int start = 0;
// 1-2. end 포인터는 배열의 두 번째 인덱스로 설정
int end = 1;
// 1-3. 현재까지의 합을 첫 번째 원소로 초기화
// - 초기 구간은 첫 번째 원소만을 포함
// - start 포인터가 가리키는 원소부터 end-1까지의 합
int currentSum = arr[0];
// 1-4. 찾은 구간의 개수를 0으로 초기화
// - target과 정확히 일치하는 구간을 찾을 때마다 증가
int count = 0;
// 2. 구간 탐색
// 배열의 모든 구간을 확인할 때까지 반복
while (start < arr.length) {
// 2-1. 현재 구간의 합이 정확히 target과 같은 경우
if (currentSum == target) {
// target과 일치하는 구간을 찾았으므로 count 증가
count++;
// end가 배열 끝에 도달하지 않은 경우
if (end < arr.length) {
// 구간을 확장하기 위해 end 위치의 원소를 더하고 end 증가
currentSum += arr[end++];
}
// end가 배열 끝에 도달한 경우
else {
// 더 이상 구간을 확장할 수 없으므로 start를 이동
currentSum -= arr[start++];
}
}
// 2-2. end가 배열 끝에 도달하지 않았고, 현재 합이 target보다 작은 경우
else if (end < arr.length && currentSum < target) {
// 구간의 합을 늘리기 위해 end 위치의 원소를 더하고 end 증가
currentSum += arr[end++];
}
// 2-3. end가 배열 끝에 도달했거나, 현재 합이 target보다 큰 경우
else {
// 구간의 합을 줄이기 위해 start 위치의 원소를 빼고 start 증가
currentSum -= arr[start++];
}
}
// 3. 탐색 완료 후 결과 처리
// 3-1. 찾은 모든 구간의 개수 반환
return count;
}
public static void main(String[] args) {
// 테스트를 위한 예제 배열과 목표 합 설정
int[] arr = {1, 2, 3, 1, 2}; // 예시 배열
int target = 3; // 목표값
// 입력 데이터 출력
System.out.println("원본 배열: " + Arrays.toString(arr));
System.out.println("목표 합: " + target);
// 결과 계산 및 출력
int result = findExactSum(arr, target);
System.out.println("합이 정확히 " + target + "인 연속된 구간의 개수: " + result);
// 모든 가능한 구간 출력 (설명을 위한 추가 코드)
System.out.println("\n만족하는 구간들:");
for (int i = 0; i < arr.length; i++) {
int sum = 0;
for (int j = i; j < arr.length; j++) {
sum += arr[j];
if (sum == target) {
System.out.println(Arrays.toString(Arrays.copyOfRange(arr, i, j + 1))
+ " (합: " + sum + ")");
}
}
}
}
}완전 탐색으로도 위에 제시된 문제들의 해결이 가능하지만, 배열의 크기와 시간 복잡도를 고려하여 더 효율적인 방법을 선택하는 것이 중요
작은 데이터라면 완전 탐색으로 충분하고, 데이터가 많거나 효율성이 중요한 경우에는 이진 탐색과 투 포인터를 활용하는 것이 필요
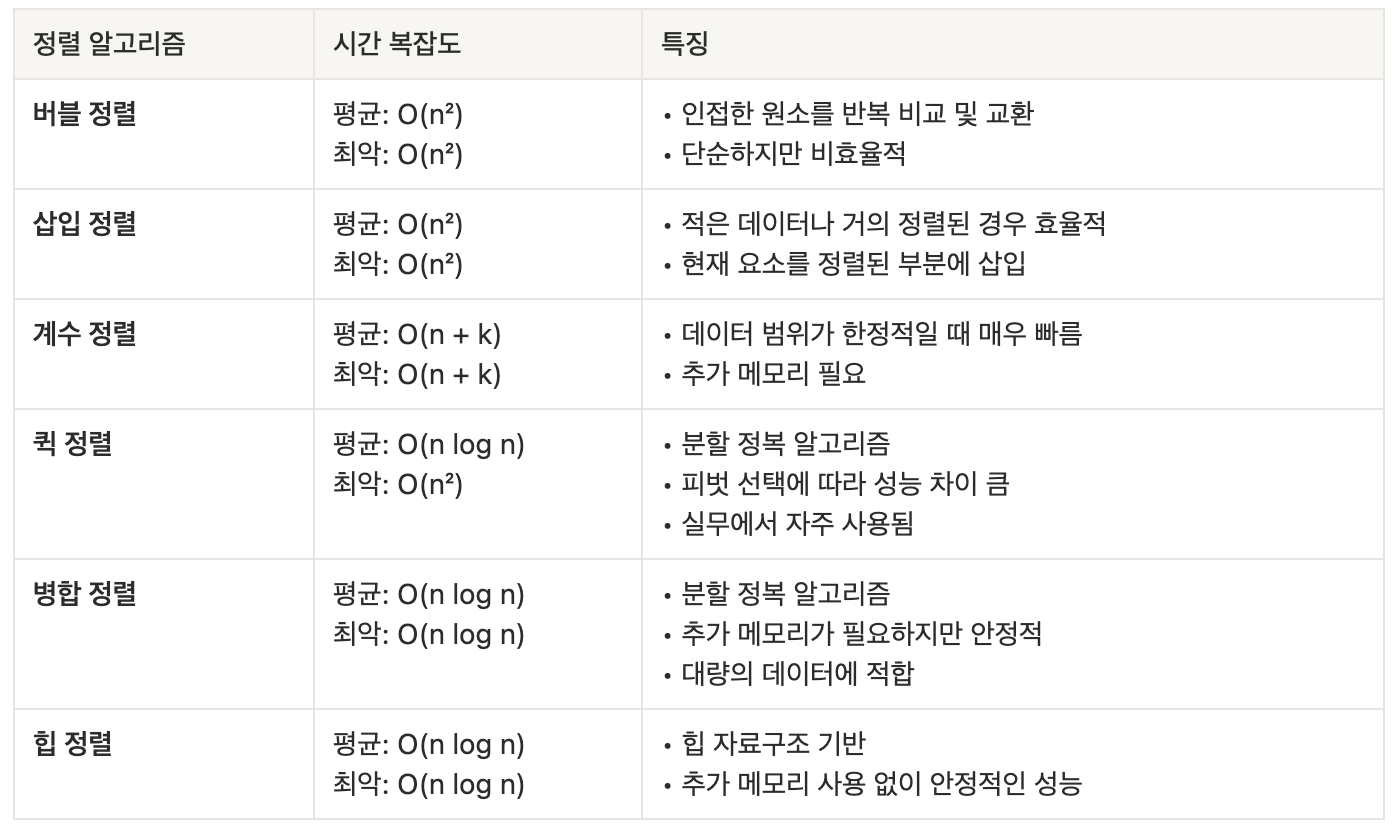
정렬 알고리즘
버블 정렬(Bubble sort)
배열을 반복적으로 순회하면서, 인접한 두 요소를 비교하여 정렬하는 단순한 정렬 알고리즘
간단히 말해, 배열의 앞에서부터 차례대로 두 개씩 비교하고, 순서가 잘못된 경우 위치를 바꿔주는 과정을 반복하여 정렬
동작 원리:
1. 인접한 두 원소를 비교하여 순서가 잘못되었다면 교환
2. 각 패스마다 가장 큰 원소가 맨 뒤로 이동하여 정렬됨
3. 정렬된 부분을 제외하고 반복
시간 복잡도: O(N^2)
public class BubbleSort {
public static void bubbleSort(int[] arr) {
int n = arr.length;
// 1. 외부 반복문: 정렬 과정(패스)을 몇 번 반복할지를 결정
// - 배열의 크기만큼 반복하며, 한 번 반복할 때마다 하나의 숫자가 최종 위치를 찾음
for (int i = 0; i < n - 1; i++) {
// 2. 내부 반복문: 실제 비교와 교환이 일어나는 과정
// - 이웃한 두 숫자를 비교
// - 범위가 점점 줄어듦 (n-i-1): 이미 정렬된 요소는 제외
for (int j = 0; j < n - i - 1; j++) {
// 3. 인접한 두 요소 비교 및 교환
// - 왼쪽 숫자가 오른쪽 숫자보다 크면 두 숫자의 위치를 바꿈
if (arr[j] > arr[j + 1]) {
// 이웃한 두 수 자리 교환
int temp = arr[j];
arr[j] = arr[j + 1];
arr[j + 1] = temp;
}
}
}
}
// 배열 출력을 위한 유틸리티 메서드
public static void printArray(int[] arr) {
for (int num : arr) {
System.out.print(num + " ");
}
System.out.println();
}
public static void main(String[] args) {
// 예시 배열 [5, 3, 8, 2]로 테스트
int[] arr = {5, 3, 8, 2};
System.out.println("정렬 전 배열:");
printArray(arr);
// 버블 정렬 수행
bubbleSort(arr);
System.out.println("정렬 후 배열:");
printArray(arr);
}
}버블 정렬의 장단점
장점
- 이해하기 쉽고 구현하기 간단
- 작은 데이터를 정렬할 때 사용하기 좋음
단점
- 다른 정렬 알고리즘에 비해 시간복잡도가 큼(시간복잡도가 O(N^2) -> 배열의 크기가 2배가 되면 정렬 시간은 약 4배로 늘어남)
- 데이터가 많을 때는 시간이 오래 걸릴 수 있음
계수 정렬(Counting Sort)
데이터의 값을 직접 비교하지 않고, 각 데이터가 몇 번 등장하는지 세어서 정렬하는 알고리즘
간단히 말해, 정수로 이루어진 배열에서 각 숫자의 출현 횟수를 세고, 이를 이용해 정렬된 배열을 만듬
세부 구현 과정
1. 카운팅 배열 생성
- 원본 배열에서 최댓값을 찾습니다. 이를 max라 할 때, 인덱스를 0부터 max까지 사용할 수 있도록
길이가 (max + 1)인 카운팅 배열을 생성합니다. - 카운팅 배열을 모두 0으로 초기화합니다.
-
숫자 세기
- 원본 배열을 순회하며 각 요소에 해당하는 카운팅 배열의 인덱스를 통해 값 증가시킵니다.
-
결과 배열 생성
- 원본 배열과 같은 크기의 결과 배열을 생성합니다.
- 카운팅 배열을 0부터 max까지 순회하며, counts[i]에 기록된 횟수만큼 결과 배열에 i를 순서대로 채워 넣습니다.
- 이 과정에서 자동으로 정렬이 완료됩니다.
시간복잡도: O(N+K) (N은 데이터 개수, K는 데이터 중 최댓값)
데이터의 범위가 너무 크지 않은 경우, 매우 빠른 정렬 속도를 보여줌
public class CountingSort {
public static void countingSort(int[] arr) {
// 1. 최댓값 찾기 - O(N)
int max = arr[0];
for (int i = 1; i < arr.length; i++) {
if (arr[i] > max) {
max = arr[i];
}
}
// 2. 카운팅 배열 생성 및 초기화
int[] counts = new int[max + 1];
// 3. 숫자 세기 - O(N)
for (int num : arr) {
counts[num]++;
}
// 4. 결과 배열 생성
int index = 0;
for (int i = 0; i <= max; i++) {
while (counts[i] > 0) {
arr[index] = i;
index++;
counts[i]--;
}
}
}
// 배열 출력을 위한 유틸리티 메서드
public static void printArray(int[] arr) {
for (int num : arr) {
System.out.print(num + " ");
}
System.out.println();
}
public static void main(String[] args) {
// 예시 배열 [4, 1, 3, 1, 2]로 테스트
int[] arr = {4, 1, 3, 1, 2};
System.out.println("정렬 전 배열:");
printArray(arr);
// 계수 정렬 수행
countingSort(arr);
System.out.println("정렬 후 배열:");
printArray(arr);
}
}계수정렬의 장단점
장점
- 양의 정수 데이터의 정렬 속도가 매우 빠름
- 비교 연산이 필요 없어서 구현이 간단함
단점
- 0이상의 정수로 표현 가능한 데이터만 정렬할 수 있음
- 음수일 경우 양수로의 범위 조정이 필요함
- 데이터의 범위만큼 추가 메모리가 필요
- 데이터의 최댓값이 매우 크면 비효율적
안정 계수정렬(Stable Counting Sort)
안정 정렬은 동일한 값을 가진 요소들의 원래 순서를 유지하는 정렬 방식
계수 정렬을 안정 정렬로서 구현하기 우해 누적 합 배열을 사용함
안정 정렬이 필요한 이유
1. 다중 기준 정렬에서의 활용
2. 데이터의 자연스러운 순서 유지
세부 구현 과정
1. 카운팅 배열 생성
- 원본 배열의 최댓값 크기만큼의 카운팅 배열을 생성합니다.
- 원본 배열을 순회하면서 각 숫자가 몇 번 등장했는지 카운팅 배열에 기록합니다.
- 누적 합 배열 생성
- 카운팅 배열과 같은 크기의 누적 합 배열을 생성합니다.
- 카운팅 배열을 순회하면서 각 위치까지의 누적 합을 계산합니다.
- 누적 합 배열의 각 값에서 1을 뺀 위치가 해당 숫자가 결과 배열에서 위치할 인덱스가 됩니다.
- 결과 배열 생성
- 결과 배열을 원본 배열과 같은 크기로 생성합니다.
- 원본 배열을 뒤에서부터 순회합니다.
- 현재 숫자를 num이라 할 때, (cumulative[num] - 1)을 인덱스로 하여 결과 배열에 num을 저장합니다.
- cumulative[num]의 값을 1 감소시킵니다.
- 뒤에서부터 채우기 때문에 같은 값을 가진 원소들의 상대적 순서가 유지됩니다.
시간복잡도: O(N+K) (N은 데이터 개수, K는 데이터 중 최댓값)
public class StableCountingSort {
public static int[] stableCountingSort(int[] arr) {
// 1. 카운팅 배열 생성
// 원본 배열의 최댓값 찾기
int max = arr[0];
for (int i = 1; i < arr.length; i++) {
if (arr[i] > max) {
max = arr[i];
}
}
// 원본 배열의 최댓값 크기만큼의 카운팅 배열을 생성
int[] counts = new int[max + 1];
// 원본 배열을 순회하면서 각 숫자가 몇 번 등장했는지 카운팅 배열에 기록
for (int num : arr) {
counts[num]++;
}
// 2. 누적 합 배열 생성
// 카운팅 배열과 같은 크기의 누적 합 배열을 생성
int[] cumulative = new int[max + 1];
// 카운팅 배열을 순회하면서 각 위치까지의 누적 합을 계산
cumulative[0] = counts[0];
for (int i = 1; i <= max; i++) {
cumulative[i] = cumulative[i - 1] + counts[i];
}
// 3. 결과 배열 생성
// 결과 배열을 원본 배열과 같은 크기로 생성
int[] result = new int[arr.length];
// 원본 배열을 뒤에서부터 순회
for (int i = arr.length - 1; i >= 0; i--) {
int num = arr[i];
// 현재 숫자를 num이라 할 때, (cumulative[num] - 1)을 인덱스로 하여 결과 배열에 num을 저장
result[cumulative[num] - 1] = num;
// cumulative[num]의 값을 1 감소
cumulative[num]--;
}
return result;
}
// 배열 출력을 위한 유틸리티 메서드
public static void printArray(int[] arr) {
for (int num : arr) {
System.out.print(num + " ");
}
System.out.println();
}
public static void main(String[] args) {
// 예시 배열 [4, 1, 3, 1, 2]로 테스트
int[] arr = {4, 1, 3, 1, 2};
System.out.println("정렬 전 배열:");
printArray(arr);
// 안정 계수 정렬 수행하고 결과 받기
int[] sortedArr = stableCountingSort(arr);
System.out.println("정렬 후 배열:");
printArray(sortedArr);
}
}
2차원 배열
2차원 배열은 행(row)과 열(column) 두 차원을 가진 배열
1차원 배열을 요소로 가지는 배열이라고 할 수 있음
2차원 배열의 특징
- 행과 열을 통한 요소 접근
- 2차원 배열의 각 요소는 [행][열] 2개의 인덱스를 통해 접근
- 행과 열 모두 0부터 시작하는 인덱스를 가짐
- 두 개의 인덱스를 통해 원하는 위치의 데이터에 즉시 접근할 수 있음
- 고정된 행과 열 크기
- 2차원 배열은 생성 시점에 행과 열의 크기를 모두 지정해야 함
- 한번 생성된 2차원 배열의 크기는 변경할 수 없음
- 크기를 변경하려면 새로운 2차원 배열을 만들어야 함
- 연속된 메모리 공간
- 2차원 배열도 1차원 배열과 같이 메모리에 연속적으로 저장됨
- 행 우선(row-major) 또는 열 우선(column-major) 방식으로 저장될 수 있음
- 자바에서는 행 우선 방식을 사용
// 2차원 배열 선언과 초기화
int[][] matrix = new int[3][4]; // 3행 4열의 2차원 배열 생성
// 초기 값을 바로 넣어 3행 3열 배열 생성
int[][] scores = {
{90, 85, 95},
{75, 80, 85},
{88, 92, 96}
};
// 2차원 배열 요소 접근하기
matrix[0][1] = 10; // 1행 2열 위치에 10을 저장
int score = scores[1][2]; // scores[1][2]는 2행 3열 값, 즉 85
// 중첩 for문을 이용한 2차원 배열 순회
for (int i = 0; i < scores.length; i++) {
for (int j = 0; j < scores[i].length; j++) {
System.out.print(scores[i][j] + " ");
}
System.out.println(); // 각 행 출력 후 줄바꿈
}
// for-each문을 이용한 2차원 배열 순회
for (int[] row : scores) { // scores 배열에서 한 행씩 꺼내기
for (int value : row) { // 해당 행에서 각 값 꺼내기
System.out.print(value + " ");
}
System.out.println();
}행렬 순회 방법
- 행 우선 순회
- 2차원 배열을 행(가로)기준에서 왼쪽에서 오른쪽으로 순회한 뒤, 다음 행으로 이동하여 반복하는 방식
- 시간복잡도: O(NxM)
- 열 우선 순회
- 2차원 배열을 열(세로)기준에서 위에서 아래로 순회한 뒤, 다음 열로 이동하여 반복하는 방식
- 시간복잡도: O(NxM)
- 지그재그 순회
- 2차원 배열을 행 단위로 순회하되, 홀수 행은 왼쪽에서 오른쪽으로, 짝수 행은 오른쪽에서 왼쪽으로 순회하는 방식
- 시간복잡도: O(NxM)
- 델타 탐색
- 2차원 배열에서 현재 위치를 기준으로 상하좌우나 대각선 등 특정 방향의 인접한 요소를 탐색하는 방법
- 나선형(달팽이)
- 2차원 배열을 바깥쪽에서 안쪽으로 시계방향으로 돌면서 순회하는 방식
- 시간복잡도: O(NxM)
행렬 변환
전치 행렬: 행렬의 행과 열을 서로 바꾼 행렬을 의미
원본 행렬의 (i,j) 위치의 원소가 전치 행렬에서는 (j,i) 위치로 이동
대각선을 기준으로 대칭되는 형태로 변환
- 시간 복잡도: O(NxM)
행렬의 회전: 90도, 180도, 270도 회전
행렬 회전은 배열의 요소를 특정 규칙에 따라 재배치하는 작업. 주로 이미지 처리, 그래픽 렌더링, 퍼즐 게임 등 다양한 응용 분야에서 사용됨
- 시간 복잡도: O(NxM)
