컬렉션 프레임워크
컬렉션 프레임워크는 데이터를 저장하고 처리하기 위한 자료구조 클래스들의 집합
- Java에서 제공하는 데이터 구조를 표준화한 설계 구조
- 다수의 데이터를 효율적이고 체계적으로 관리할 수 있는 방법을 제공
왜 사용할까?
1. 프로그래밍 효율성
- 이미 구현된 자료구조를 사용하여 개발 시간을 단축할 수 있음
- 최적화된 알고리즘을 통해 성능을 보장받을 수 있음
2. 재사용성
- 표준화된 방식으로 데이터를 관리할 수 있음
- 여러 프로젝트에서 일관된 방식으로 사용할 수 있음
주요 인터페이스와 클래스
-
List 계열: 데이터를 순차적으로 저장
- ArrayList: 배열 기반으로 데이터를 저장하며, 조회 속도가 빠름
- LinkedList: 노드 기반으로 데이터를 저장하며, 삽입과 삭제가 빠름
-
Set 계열: 중복을 허용하지 않는 데이터 집합
- HashSet: 데이터를 해시 값으로 관리하여 검색 속도가 빠름
- TreeSet: 데이터를 정렬된 상태로 유지하며, 이진 검색 트리 기반으로 동작
-
Map 계열: 키와 값을 쌍으로 저장하며, 키는 중복을 허용하지 않음
- HashMap: 해시 기반으로 키-값 데이터를 저장하며, 빠른 검색 속도를 제공
- TreeMap: 키를 기준으로 정렬된 키-값 쌍 저장
List 인터페이스
List 컬렉션은 순서를 유지하며 중복을 허용하는 요소들의 집합을 나타내는 인터페이스로, 구현체에 따라 ArrayList, LinkedList 등으로 동작 방식이 달라짐
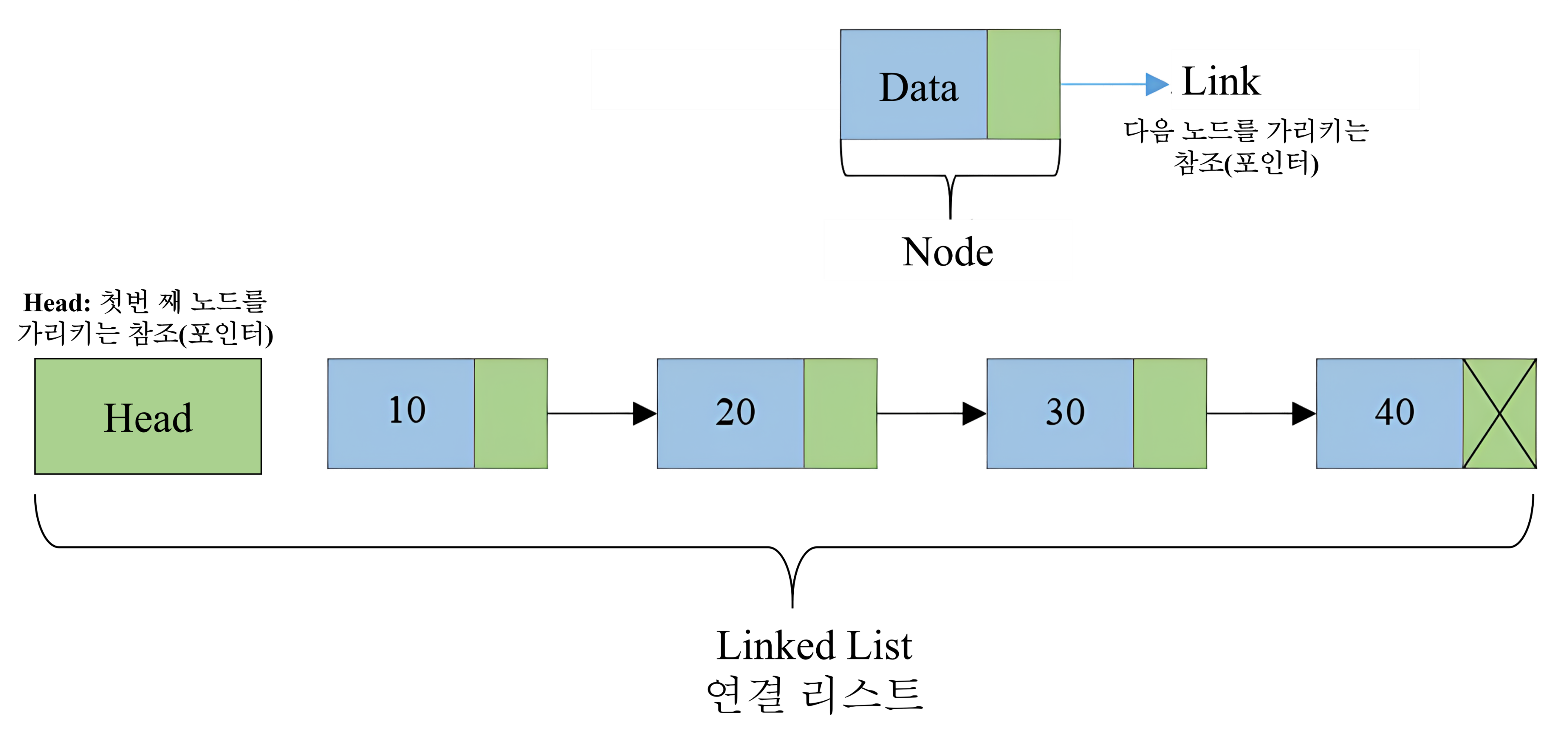
List 컬렉션의 특징
- 순서 유지
- 요소가 삽입된 순서가 유지되며, 인덱스를 통해 각 요소를 관리
- 요소는 0부터 시작하는 인덱스를 가지며, 원하는 위치의 요소에 직접 접근 가능
- 유연한 크기
- 배열과 달리 크기가 고정되지 않고, 동적으로 변함
- 요소를 추가하거나 제거할 때 자동으로 크기가 조정됨
- 다양한 구현체
- ArrayList: 배열 기반으로 빠른 접근 속도를 제공하지만, 중간 삽입/삭제는 느림
- 접근이 빠름 O(1)
- 중간 삽입/삭제 O(n)
- 메모리 연속적
- LinkedList: 이중 연결 리스트 기반으로 삽입/삭제가 빠르지만, 랜덤 접근은 느림
- 접근이 느림 O(n)
- 중간 삽입/삭제 O(n)
- 메모리 분산
ArrayList를 사용하면 좋은 경우
- 데이터 검색/조회가 빈번한 경우
- 데이터의 삽입/삭제가 주로 마지막 위치에서 일어나는 경우
- 데이터가 자주 변경되지 않고 주로 읽기 작업이 많은 경우
LinkedList를 사용하면 좋은 경우
- 데이터의 삽입/삭제가 리스트의 시작이나 끝에서 빈번히 발생하는 경우
- 데이터의 크기가 예측이 어렵고 변동이 심한 경우
ArrayList 선언 및 사용 예시
import java.util.ArrayList;
import java.util.List;
public class Solution {
public static void main(String[] args) {
// ArrayList 선언
ArrayList<String> fruits = new ArrayList<>();
// 초기값 추가
fruits.add("Apple"); // "Apple" 추가
fruits.add("Banana"); // "Banana" 추가
fruits.add("Cherry"); // "Cherry" 추가
// ArrayList 초기값과 함께 생성
ArrayList<String> colors = new ArrayList<>(List.of("Red", "Green", "Blue"));
System.out.println("\nColors ArrayList: " + colors);
// ArrayList 요소 접근
System.out.println("First Fruit: " + fruits.get(0)); // 첫 번째 요소 가져오기
// 특정 인덱스에 요소 삽입
fruits.add(1, "Orange"); // 인덱스 1에 "Orange" 삽입
System.out.println("After inserting 'Orange': " + fruits);
// 요소 변경
fruits.set(2, "Blueberry"); // 인덱스 2의 요소를 "Blueberry"로 변경
System.out.println("After updating index 2: " + fruits);
// 요소 제거
fruits.remove(3); // 인덱스 3의 요소 제거
System.out.println("After removing index 3: " + fruits);
fruits.remove("Orange"); // "Orange" 제거
System.out.println("After removing 'Orange': " + fruits);
// ArrayList 크기 확인
System.out.println("ArrayList Size: " + fruits.size());
// ArrayList가 비어 있는지 확인
System.out.println("Is ArrayList Empty? " + fruits.isEmpty());
// for문을 이용한 ArrayList 순회 (인덱스로 값 참조)
System.out.println("\nUsing for loop:");
for (int i = 0; i < fruits.size(); i++) {
System.out.println("Element at index " + i + ": " + fruits.get(i));
}
// for-each문을 이용한 ArrayList 순회 (직접 값 참조)
System.out.println("\nUsing for-each loop:");
for (String fruit : fruits) {
System.out.println("Fruit: " + fruit);
}
}
}배열과 ArrayList의 차이점
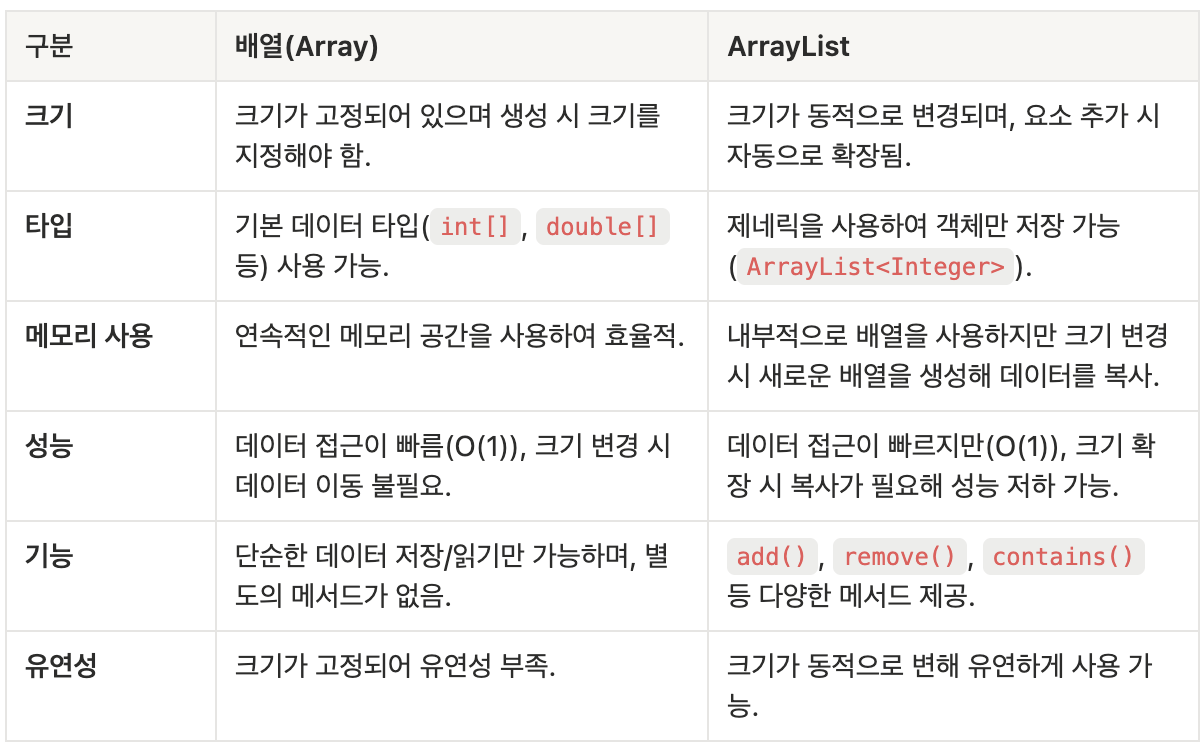
배열
- 크기가 고정된 데이터 집합을 처리할 때 적합
- 데이터 구조가 단순하고 성능(접근 속도)이 중요한 경우 유리
- 메모리 사용이 효율적이어야 하거나 기본 타입 데이터를 다룰 때
ArrayList
- 동적으로 데이터 크기가 변할 가능성이 있을 때
- 요소 추가/삭제가 빈번하고, 코드를 간단하고 가독성 있게 작성하고 싶을 때
- 데이터 조작에 다양한 메서드가 필요할 때
Collections 유틸리티 클래스 활용
Collections의 주요 기능
1. 정렬(Sorting)
컬렉션의 요소를 자연 정렬 순서 또는 사용자 정의 기준으로 정렬할 수 있음
- 주요 메서드
Collections.sort(List<T>): 자연정렬Collections.sort(List<T>, Comparator<T>): 사용자 정의 정렬
- 최솟값, 최댓값 찾기(Min/Max)
컬렉션에서 최솟값과 최댓값을 쉽게 찾을 수 있음
- 주요 메서드
Collections.min(Collection<T>)Collections.max(Collection<T>)
- 빈도 계산(Frequency)
요소가 얼마나 자주 등장했는지 확인하는 문제에 유용
- 메서드
Collections.frequency(Collection<T>, T)
- 이진 탐색(Binary Search)
정렬된 리스트에서 빠르게 값을 찾는 문제에 적합
입력 리스트는 반드시 정렬 상태여야 함
- 메서드
Collections.binarySearch(List<T>, T key)
- 요소 치환(Replace)
컬렉션에서 특정 값을 다른 값으로 변경
- 주요 메서드
Collections.replaceAll(List<T>, T oldVal, T newVal)
- 역순 변환(Reversing)
컬렉션의 순서를 뒤집음
- 주요 메서드
Collections.reverse(List<T>)
- 요소 회전(Rotation)
컬렉션의 요소를 지정된 거리만큼 이동
- 주요 메서드
Collections.rotate(List<T>, int distance)
Map 인터페이스
Map은 키(Key)와 값(Value)을 하나의 쌍으로 묶어서 저장하는 자료구조
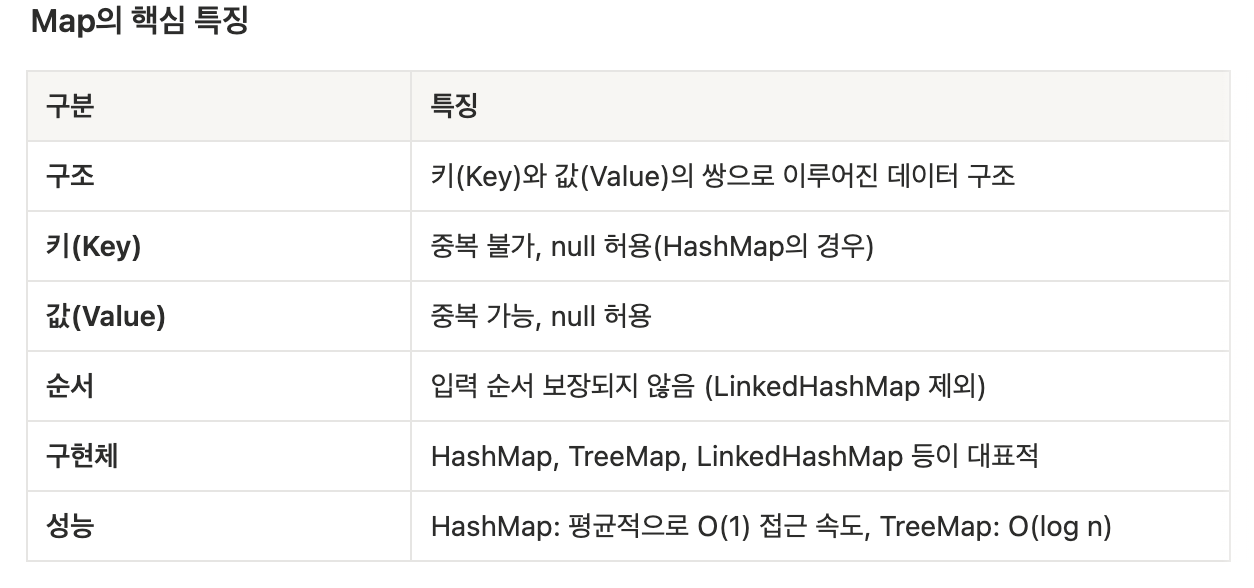
Map의 사용 목적과 활용 상황
-
사용하는 이유
- 빠른 검색/조회: 키를 통해 O(1) 시간에 데이터 접근 가능
- 연관 데이터 관리: 관련된 데이터를 쌍으로 관리 가능
- 중복 제거: 키의 중복을 허용하지 않아 유니크한 데이터 관리 용이
-
주요 활용 상황
- 캐시/임시 저장소: 특정 키로 빠르게 데이터를 가져와야 하는 경우
- 빈도수 계산: 데이터 출현 횟수 집계(문자 빈도수, 단어 빈도수 등)
- ID와 객체 매핑: 회원 ID -> 회원 정보, 상품 코드 -> 상품 정보 등 매핑
- 데이터 그룹화/분류: 특정 기준으로 데이터를 묶어 관리
HashMap 주요 메서드 및 활용
HashMap은 Map 인터페이스를 구현한 대표적인 클래스, 가장 자주 사용됨
// 1. 선언
HashMap<String, Integer> map = new HashMap<>();
// 2. 데이터 추가 및 수정
map.put("A", 1); // 키가 "A"인 값에 1 저장
map.putIfAbsent("A", 10); // "A"키가 없을 때만 10 저장
int value = map.getOrDefault("B", 0);// "B"키 조회, 없으면 기본값 0
// 3. 존재 여부 확인
if (map.containsKey("A")) { ... } // "A"키 존재 여부 확인
if (map.containsValue(1)) { ... } // 값 1 존재 여부 확인
// 4. 삭제
map.remove("A"); // "A"키 삭제
map.clear(); // 전체 삭제
// 5. 값 변경하기 (다양한 방법)
HashMap<String, Integer> scores = new HashMap<>();
scores.put("Kim", 80);
// 5-1. 일반적 방식
if (scores.containsKey("Kim")) {
scores.put("Kim", scores.get("Kim") + 10);
}
// 5-2. compute 활용 (람다 사용)
scores.compute("Kim", (key, oldVal) -> oldVal + 10);
// 5-3. 키가 있을 때만 변경 (computeIfPresent)
scores.computeIfPresent("Kim", (key, oldVal) -> oldVal + 10);
// 6. 크기 확인
int size = map.size();
boolean isEmpty = map.isEmpty();
Set 인터페이스
Set은 중복되지 않는 요소들을 저장하는 자료구조
값이 2번 이상 등장하는 것을 허용하지 않으며 각 요소는 유일
순서는 보장하지 않지만 LinkedHaseSet을 사용하면 삽입 순서를 유지할 수 있음
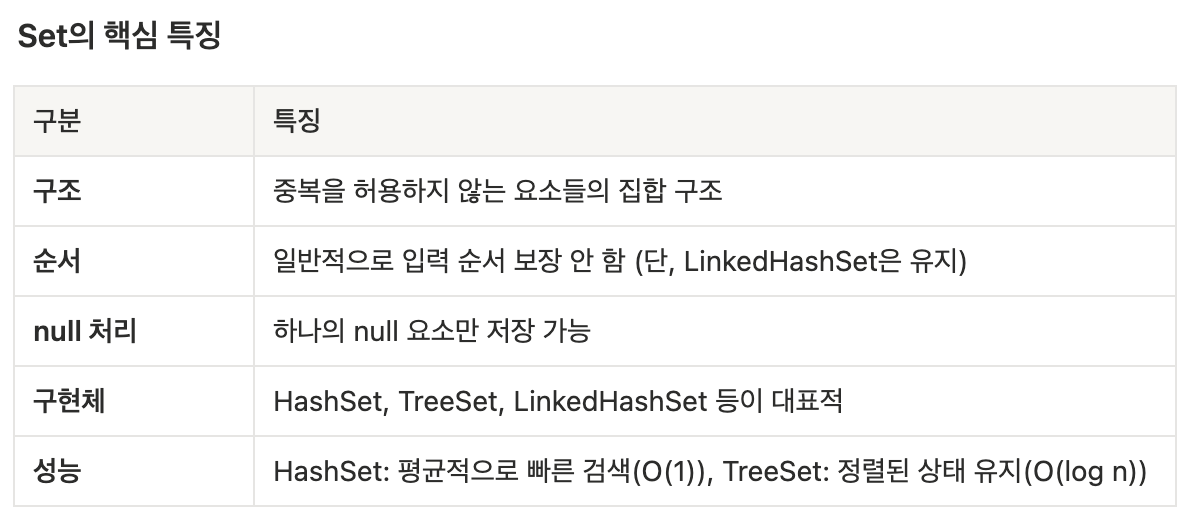
Set의 사용 목적과 활용 상황
- 핵심 사용 목적
- 중복 제거: 대용량 데이터에서 같은 요소가 반복될 때, 효율적으로 중복을 제거할 수 있음
- 유일성 보장: 비즈니스 로직상 고유해야 하는 값 관리
- 집합 연산 처리: 합집합, 교집합, 차집합과 같은 집합 연산을 쉽게 수행
- 메모리 절약: 불필요한 중복데이터를 제거하여 메모리 사용량 감소
- 실무 활용 예시
- 데이터 처리 측면: 로그 분석 - 다양한 IP나 사용자 ID 중에서 유일한 값을 추출
- 비즈니스 로직 측면: 회원관리 - 중복 불가능한 식별자 관리
HashSet 주요 메서드 및 활용
HashSet은 가장 널리 사용되는 Set 구현체 중 하나로 해시 기반으로 요소를 관리
일반적으로 순서를 보장하지 않으며 빠른 검색과 삽입 성능을 자랑함
// 1. 선언
HashSet<String> set = new HashSet<>();
// 2. 데이터 추가 및 삭제
set.add("A"); // 요소 "A" 추가 (중복 요소는 추가되지 않음)
set.remove("A"); // "A" 삭제
set.clear(); // 모든 요소 삭제
// 3. 데이터 확인
boolean exists = set.contains("A"); // "A"가 존재하는지 확인
int size = set.size(); // Set의 크기 확인
boolean empty = set.isEmpty(); // 비었는지 확인
// 4. 집합 연산
Set<String> set1 = new HashSet<>();
Set<String> set2 = new HashSet<>();
// 합집합: set1에 set2의 요소 모두 추가
set1.addAll(set2);
// 교집합: set1과 set2에 모두 있는 요소만 남김
set1.retainAll(set2);
// 차집합: set1에서 set2의 요소 제거 (set1 - set2)
set1.removeAll(set2);