What is Distribute computing ?
Why distribute computing ??
We should mine huge data.. so we have to use multi-computer resource.
In the past, we use super computer, but it costs a lot.
So, we use distributed computing on commodity hardware instead super computer.
And, there has some problems on commodity hardware…
Issues
1. How to distribute computation ??
In commodity hardware system, Not all computers have the data they need.
So, the data must be transferred from a computer with data to a computer without data.
But, Copying data over a network takes time

So, Not handing over data.
💡 Idea
1. Handing over computation
2. Store files multiple times for reliability
And, Spark/Hadoop address these problems
- Storage Infrastructure – File system
- Google : GFS.
- Hadoop : HDFS
- Programming model
- MapReduce
- Spark
2. Storage Infrastructure
Q. If nodes fail, how to store data persistently?
A. Distributed File System
What is Distributed File System ??
provides global file namespace
“feel like to use single computer when connect multi-computer.”
- Typical usage pattern: ▪ Huge files (100s of GB to TB)
▪ Data is rarely updated in place
▪ Reads and appends are common
- Chunk servers
▪ File is split into contiguous chunks
▪ Typically each chunk is 16-64MB
▪ Each chunk replicated (usually 2x or 3x)
▪ Try to keep replicas in different racks - Master node
▪ a.k.a. Name Node in Hadoop’s HDFS
▪ Stores metadata about where files are stored
▪ Might be replicated - Client library for file access
- Talks to master to find chunk servers
- Connects directly to chunk servers to access data
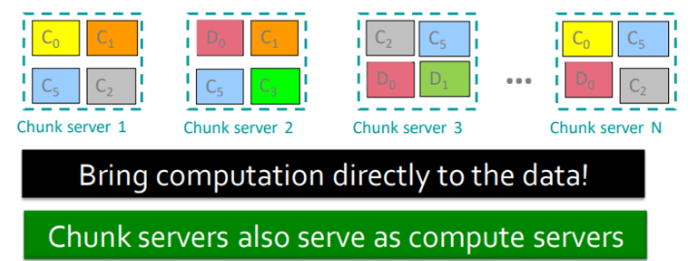
Data kept in “chunks” spread across machines
Each chunk replicated on different machines
→ Seamless recovery from disk or machine failure
Distributed File System = Reliable distributed file system
Google makes early Distributed Computing system.
That is ..
Mapreduce
= “style of programming”
Purpose :
“Processing large amounts of data (petabytes or more) on a cluster of low-end computers”
## What is cluster ??
- We need many computers and networks for distribute computing.
- This is cluster(many computers and networks).
- It contains computer, LAN, software for implementing cluster.
- Combining several relatively inexpensive, low-performance computers
to achieve supercomputer-like performanceMethod :
Parallelizing the data to be processed by implementing Map() and Reduce(). This parallelized data is sent to each node in the cluster so that it can be processed simultaneously.
Result :
Developers only need to implement Map() and Reduce() and the framework will handle the complex distributed processing at the back end.
Developers focus only on data analysis
- Easy parallel programming
- Invisible management of hardware and software failures
- Easy management of very-large-scale data
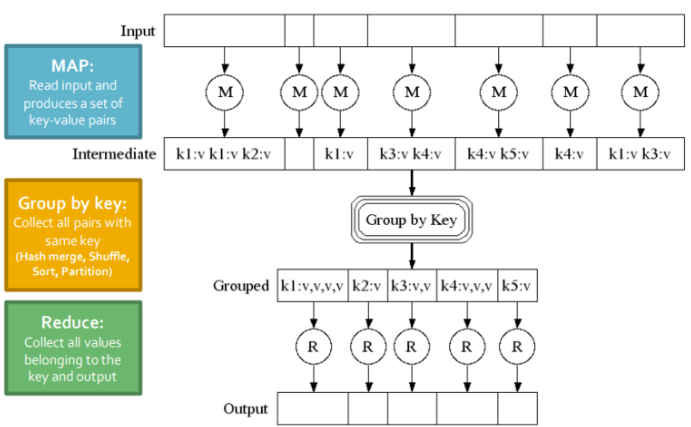
🪜 Step
- Map
- User write map function for each element
- The output of the Map function is a set of 0, 1, or more
key-value pairs- Group by key
- System sorts all the key-value pairs by key, and
outputs key-(list of values) pairs- Reduce
- User-written Reduce function is applied to each
key-(list of values)