오늘은 올라마(Ollama)에 임베딩 모델을 다뤘다. 나에게는 흥미로운 현상을 발견했는데, 이게 좀 머리 아픈 문제였다.
먼저, 상황을 간단히 설명하자면:
- embedding1과 embedding2는 본질적으로 같은 문장이다. 단, 길이만 살짝 다르다.
- 극단적 예를 들면 이런 식이다:
text1 = "사과는 맛있다."
text2 = "사과는 맛있다. 그리고"
여기서 중요한 점:
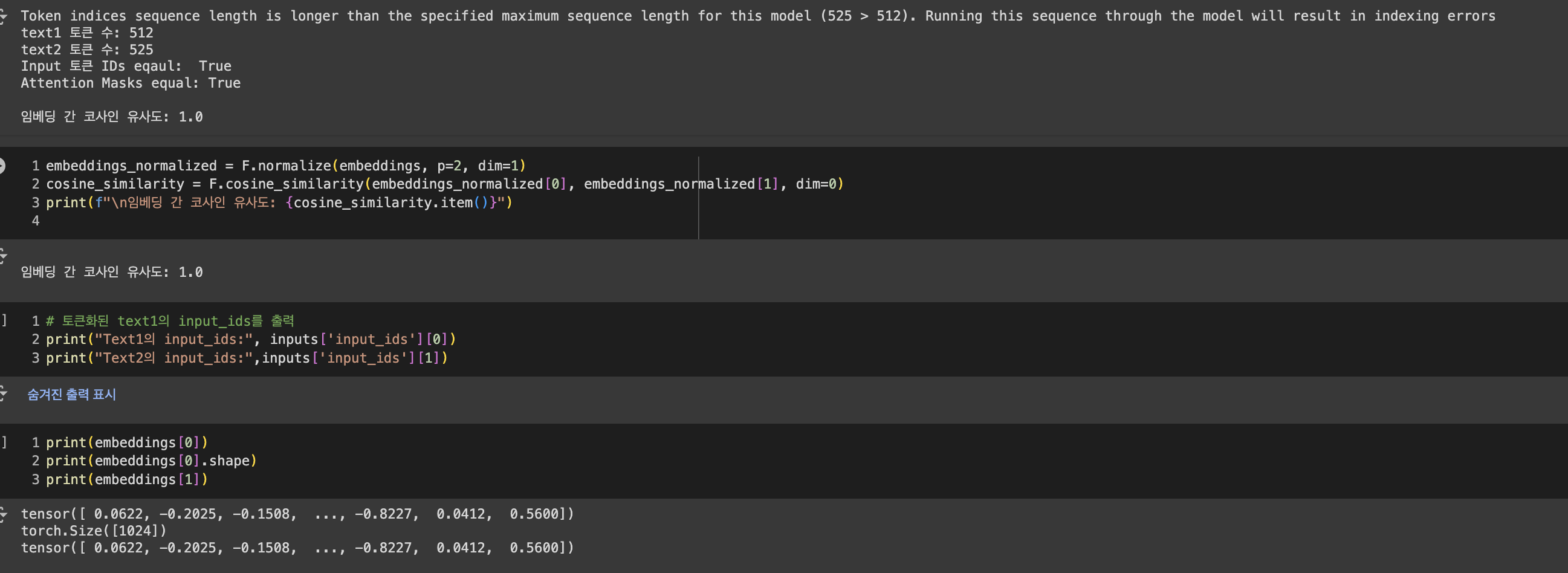
- 사용한 임베딩 모델의
max length는 512 토큰이다. - 일반적으로 512 토큰을 넘는 입력은 513번째 토큰부터 잘리는 게 당연하다고 알고 있었다.
- 실제로 임베딩 매개변수 중
Truncation도True로 설정되어 있었다. - ollama에 있는 거 말고 허깅페이스에 있는 원본 모델을 가지고 테스트해서 코사인 유사도 찍어보니 1이다.
내 예상:
올라마 api로도 text1과 text2의 코사인 유사도가 1이 나올 거라고 생각했다.
왜? text2가 max length를 넘어가면 어차피 512 토큰 이후는 잘릴 테니까, 결국 text1과 text2는 실질적으로 같은 문장이 되는 거 아닌가?
하지만 현실은:
올라마에서 가져온 모델을 Postman으로 API 호출해서 확인해보니, text1과 text2의 임베딩 값이 서로 달랐다.
이게 대체 왜 그런 걸까? 🤔
이 현상에 대해 더 깊이 파고들어야 할 것 같다. 임베딩 모델의 내부에 토큰화 과정에 뭔가 내가 모르는 개념이 있는 것 같다. 공부할게 많다. 주말에 이 문제를 좀 더 자세히 들여다봐야겠다. 다음포스트요.

숨쉬는 대학생