
NumPy - ndarray 정리
✅ ndarray vs list 비교
| 항목 | ndarray | list |
|---|---|---|
| 데이터 타입 | 모든 원소가 동일한 타입 | 다양한 타입 혼합 가능 |
| 메모리 효율 | 크기가 고정되어 메모리 사용이 더 효율적 | 유연하지만 비효율적일 수 있음 |
| 차원 지원 | 1차원 벡터, 2차원 행렬, 다차원 텐서 등 가능 | 일반적으로 1차원 |
| 연산 처리 | 반복문 없이 전체 배열 연산 가능 (벡터화 연산) | 반복문 필수 |
✅ 배열 생성 방법
import numpy as np
arr = np.array([1, 2, 3, 4])📌 특정한 값을 가진 배열
np.zeros(5) # 0으로 채워진 (5,) 배열
np.ones((2, 3)) # 1로 채워진 2x3 배열
np.full((3, 3), 7) # 7로 채워진 3x3 배열✅ arange() 함수
: 특정 간격의 숫자 배열을 생성
-> 파이썬의 range와 유사하지만, 배열 형태로 반환
np.arange(start, stop, step)
np.arange(5) # [0 1 2 3 4]
np.arange(1, 10) # [1 2 3 4 5 6 7 8 9]
np.arange(0, 10, 2) # [0 2 4 6 8]
np.arange(0, 1, 0.2) # [0. 0.2 0.4 0.6 0.8]✅ linspace() 함수
: 지정된 구간을 균등하게 나눈 숫자 배열생성
-> arange에서는 시작과 끝값이 포함안됐지만 linspace는 포함
np.linspace(start,stop,num=50)
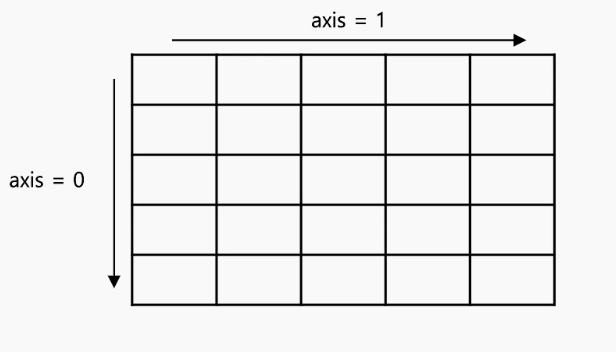
np.linspace(0,1,5) # [0. 0.25 0.5 0.75 1.]축 (axis) 개념
- 행 방향 (↓) : axis=0
- 열 방향 (→) : axis=1
📌 참고 이미지
✅ 차원 관련 함수
arr.reshape(newshape): arr의 차원을 newshape로 변경flatten: 다차원 배열을 1차원으로 평탄화하는데 사용squeeze: 크기가 1인 차원을 제거 (ex : (1,3,1)인 배열이 있다면 (3,)으로 변환)
arr2 = np.array([[1,2,3],[4,5,6]])
print("차원:",arr2.ndim) #차원: 2
print("형태:",arr2.shape) #형태: (2,3)arr3 = np.array([[[1,2],[3,4]],[[5,6],[7,8]]])
print("차원:",arr3.ndim) #차원: 3
print("형태:",arr3.shape) #형태: (2,2,2)✅ 유니버설 함수 (ufunc)
: 배열 요소별 연산을 수행하는 함수
- 산술연산 : np.add, np.substract, np.multiply, np.divide(+,=,*,/ 연산자를 써서 실질적으로 쓰진 않음)
- 거듭제곱 : np.power
- 삼각 함수 : np.sin, np.cos, np.tan
- 지수와 로그 : np.exp, np.log, np.log10
- 기타 : np.sqrt(제곱근), np.abs(절대값)
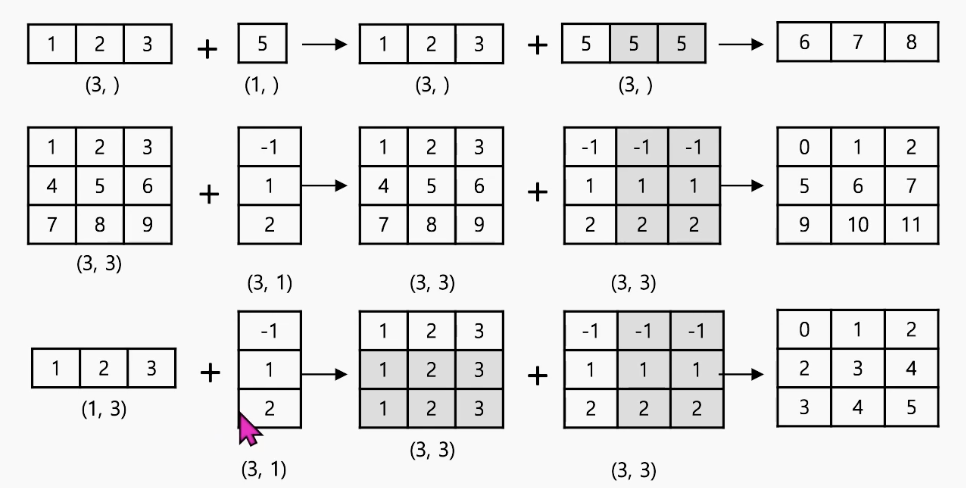
✅브로드캐스팅
: 서로 다른 크기의 배열 간 연산을 가능하게 함
작은 배열이 자동으로 확장되어 큰 배열과 동일한 형태로 변환된 후 연산 수행
✅ 통계 함수
- np.mean / arr.mean
- np.std / arr.std
- np.var / arr.var
- np.max / arr.max
- np.median / arr.median
- np.sum / arr.sum
💡 2차원 이상에서는 axis 인자 꼭 지정해야 정확한 결과 나옴

Hello. I'm jimin:)