
데이터 입출력
✅ read_csv , read_excel 함수
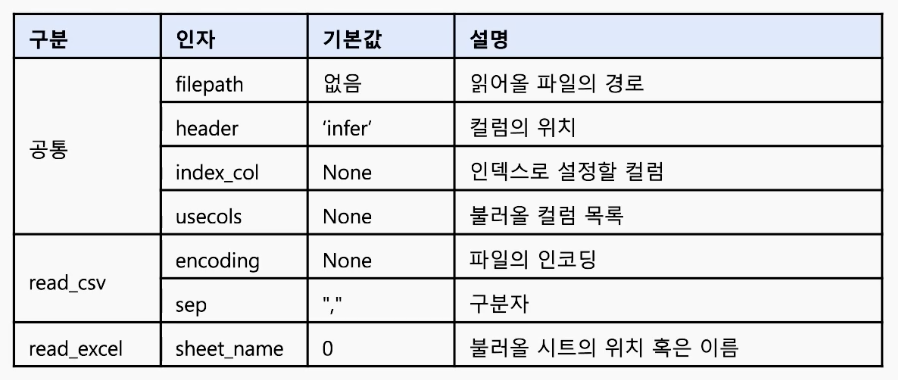
header 인자
: 컬럼의 위치가 맨 위가 아니라면 header 인자를 이용해서 컬럼 위치를 정의
- 기본값은 0이므로 따로 설정하지 않으면 맨 윗 줄의 행이 header로 설정
- 컬럼의 위치가 맨 위가 아니라면 header인자를 그에 맞게 설정해야한다.
- header가 없다면 None을 입력
index_col 인자
: 어떤 열을 DataFrame의 인덱스로 사용할지 지정하는 인자
- 기본 값 : index_col을 따로 지정하지 않으면, Pandas는 0부터 시작하는 정수 인덱스를 사용
- 정수 리스트 입력 : 해당 리스트에 속한 위치에 속하는 열만 불러옴
- 문자열 리스트 입력 : 읽을 열의 이름을 지정
- (lambda) 함수 입력 : 특정한 조건을 같는 열만 불러옴
encoding 인자
: encoding 인자는 주로 한글이 깨질 때 설정
- 데이터 파일에 한글이 있는 경우, 한글이 깨지는 경우가 있음 -> 인코딩방식이 다르기 때문
- 컴퓨터가 문자 자체를 인식하지 못하므로 파일에 포함된 모든 문자를 대응되는 코드로 변환되어 저장 -> 이 변환 방식을 인코딩 이라고함
- 대표적인 한글 인코딩 : euc-kr, cp949
sep 인자
: 파일의 구분자 설정
- csv(coomma-separated values) : 쉼표로 구분한 텍스트 데이터 파일
- tsv(tab-separated values) : 쉼표가 아닌 다른 값으로 구분자가 지정된 파일
sheet_name 인자
- sheet_name 인자의의 기본값은 0이므로 특별한 설정을 하지 않으면 맨 앞에 있는 시트의 데이터를 불러옴
- sheet_name은 시트명을 문자열로 그대로 입력하거나, 시트의 위치(맨 앞:0)를 입력해서 불러올 수 있음
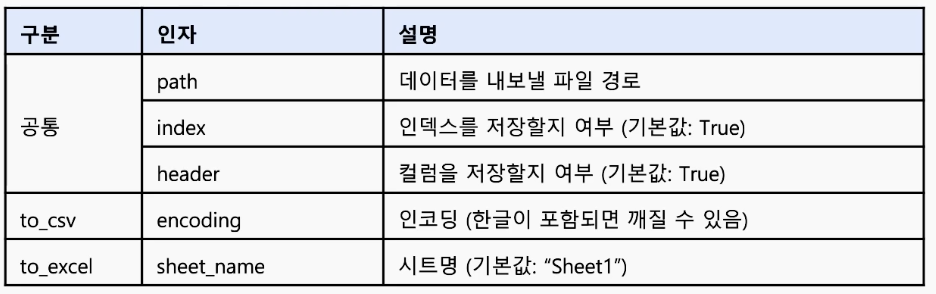
to_csv와 to_excel 함수
concat 함수
: 두 개의 이상의 DataFrame 병합할때 사용
- objs : 병합할 시리즈 혹은 데이터프렝미으로 구성된 배열
- axis : 데이터프레임을 합치는 방향으로, axis = 0이면 위 그림과 같이 행 방향으로 병합되며, axis = 1 이면 열 방향으로 병합된다. 기본값은 0
- ignore_index : 병합 후에도 기존 데이터의 인덱스를 사용할 것인지, 혹은 새로운 인덱스를 만들지 나타낸다.
True를 입력해서 만들어지는 새로운 인덱스는 0부터 시작하는 위치 인덱스.
행 방향으로 병합하는 경우에는 True로, 열 방향으로 병합하는 경우에는 False로 주로 설정
winequality_red = pd.read_csv("/winequality-red.csv", sep=';', usecols=["fixed acidity", "volatile acidity"])
winequality_white = pd.read_csv("/winequality-white.csv", sep=';', usecols=["fixed acidity", "volatile acidity"])
wine_combined = pd.concat([winequality_red, winequality_white], axis=0)
wine_combined.head()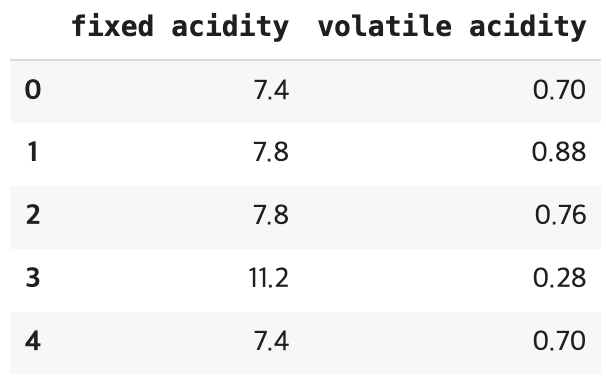
os.listdir() 함수
여러 파일 불러와서 합치기
1. 불러올 파일 경로로 구성된 리스트 생성하기
2. 빈 데이터프레임 만들기
3. 1에서 만든 리스트의 각 요소를 순회하면서 데이터를 불러오고 빈 데이터프레임과 병합
데이터 필터링
loc, iloc 인덱서
:특정 데이터를 인덱싱하거나 슬라이싱할 때 사용하는 메서드
- loc인덱서 : 행과 열의 이름을 사용하여 데이터를 선택하며, 조건 기반의 필터링을 할 때도 사용
- iloc인덱서 : 행과 열의 숫자 인덱스를 이용하여 데이터를 선택
- loc메서드는 슬라이싱에서 마지막 인덱스를 포함하나, iloc 인덱서는 포함X
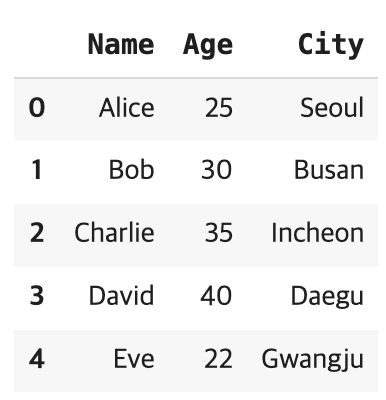
display(df.iloc[[0,2],[0,1]])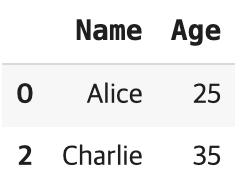
행 및 열 선택과 제거
- df['열이름'] # 시리즈를 반환
- df[['열이름']] # 데이터프레임을 반환
- df[['열이름1','열이름2',...] # 데이터 프레인을 반환

Hello. I'm jimin:)