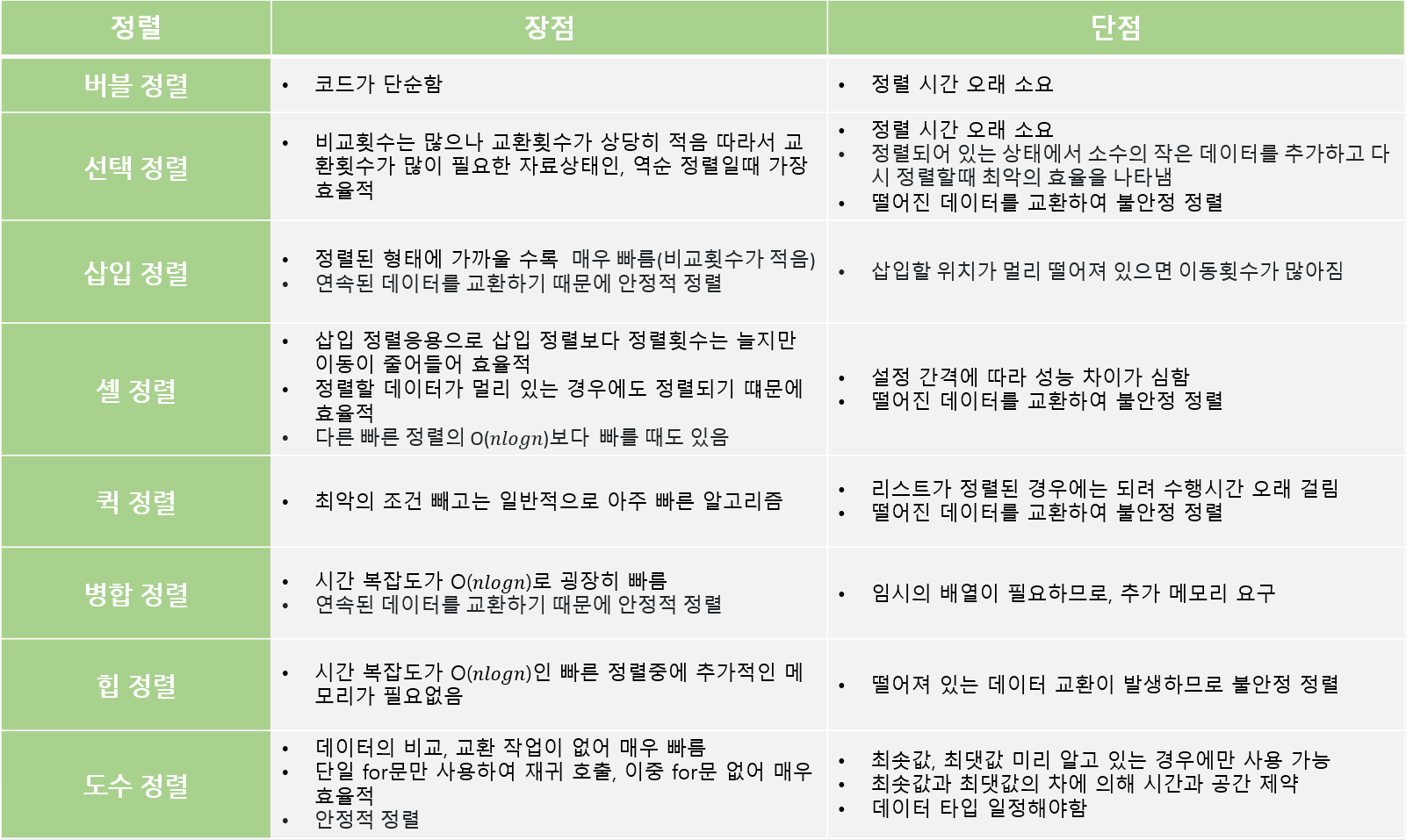
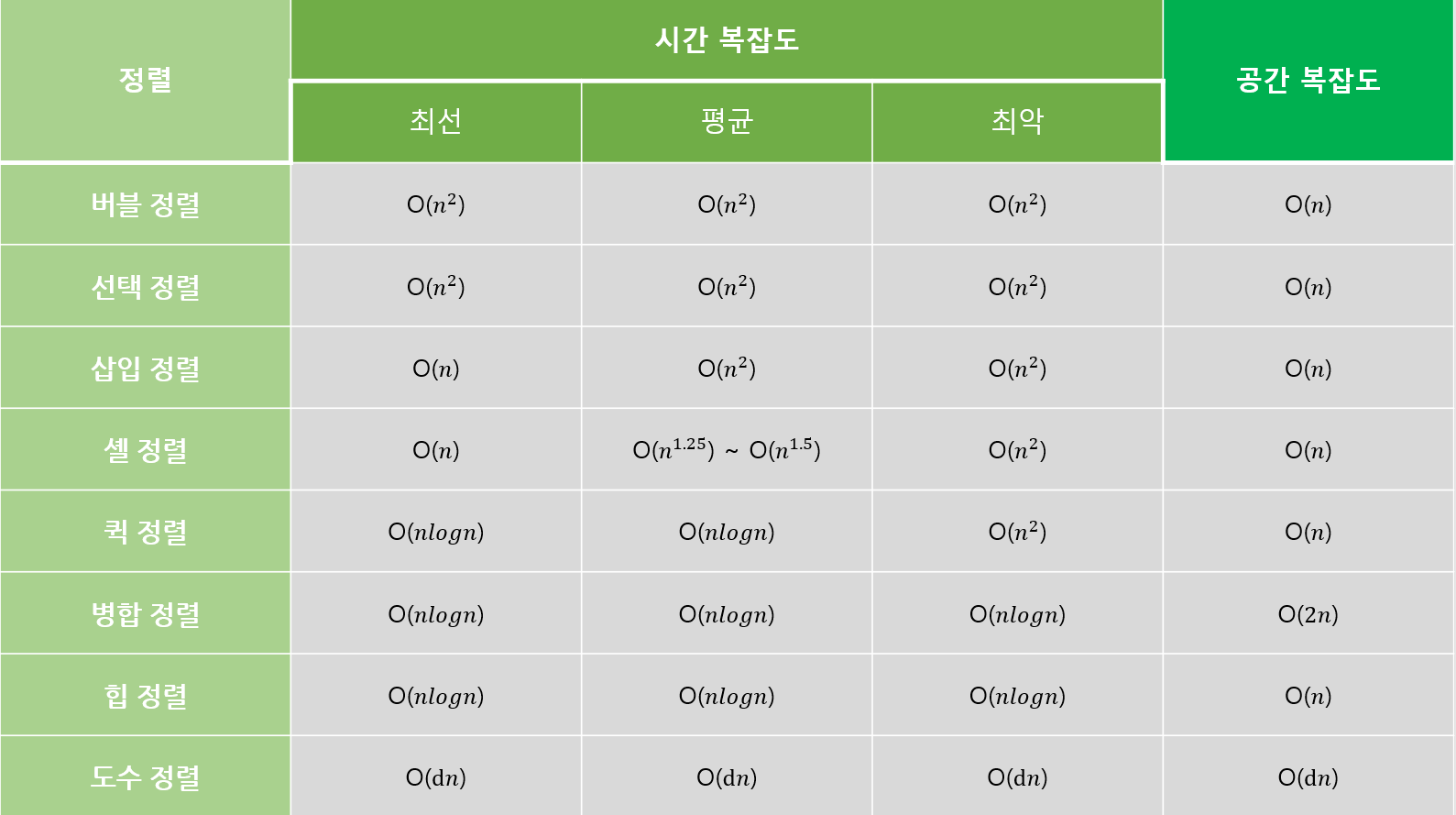
도수 정렬 특징
- 선택, 삽입, 퀵, 병합, 힙 정렬과 다르게 키 값의 비교가 불필요함
- 크기를 기준으로 개수만 세주어 위치를 바꿀 필요없음
- 모든 데이터에 한 번씩만 접근하여 되게 효율적임
- 범위 조건이 있는 경우에 한해서 굉장히 빠름
도수 정렬 단계
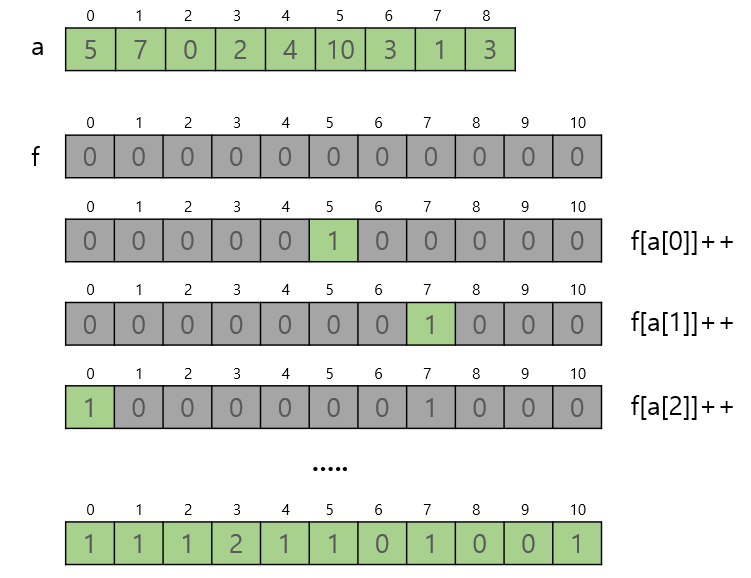
1. 도수분포표 만들기
-
설명
배열 a에는 입력값, 배열 f는 도수분포표를 만들기위해 필요, f는 카운팅을 해야함으로모든 요솟값들을 0으로 초기화 해준다. a를 스캔하며 해당 값을 찾으면 f의 인덱스에 위치한 값에 1씩 증가시킴 -
코드
/* 개수 0으로 초기화 */
for (i = 0; i <= max; i++) f[i] = 0;
/* 도수 분포표 */
for (i = 0; i < n; i++) f[a[i]]++; - 그림
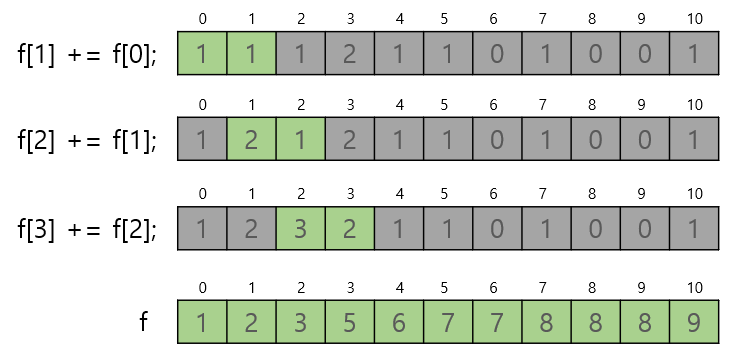
2. 누적도수분포표 만들기
-
설명
배열 a의 값의 범위가 0 이상 max 이하일때(그림에서는 max를 10이라 가정), 배열 f를 누적된 값이 몇개 있는지 나타내게 만들어준다. 그러면 배열 a의 값들이 몇 번째에 위치하는지 알수 있다. -
코드
/* 누적 도수 분포표 */
for (i = 1; i <= max; i++) f[i] += f[i - 1]; - 그림
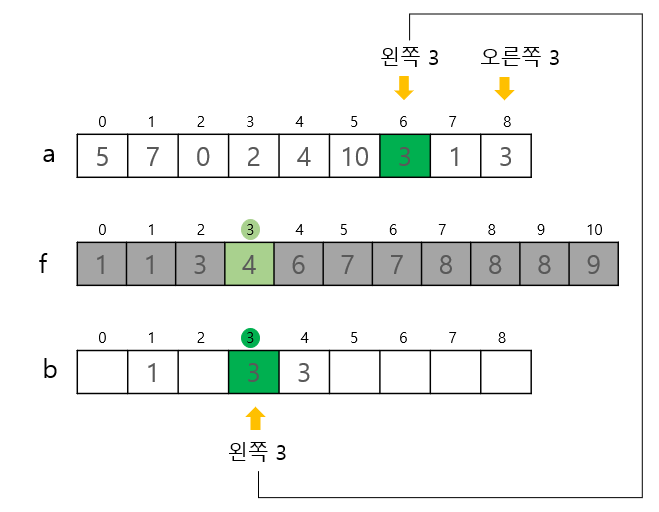
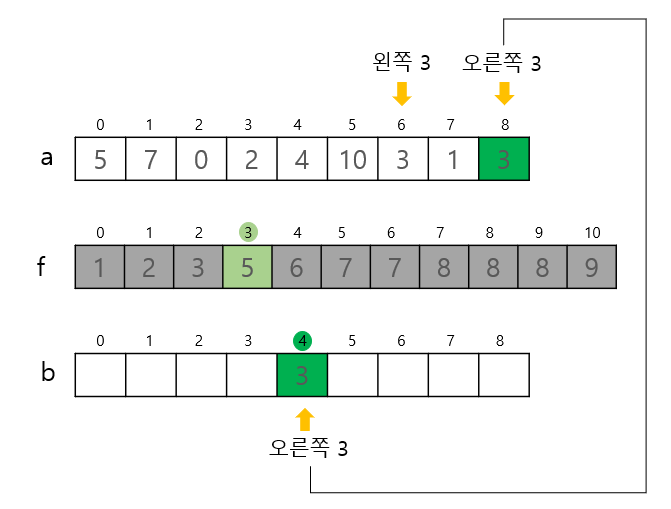
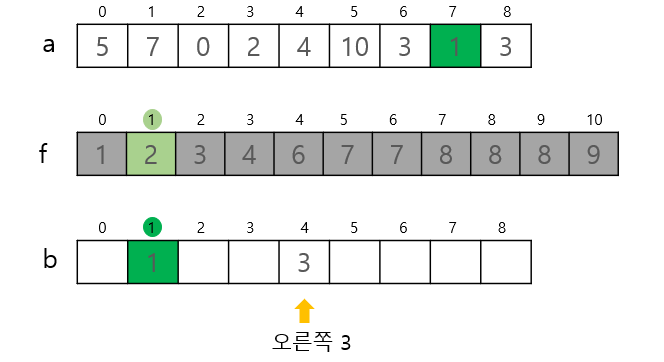
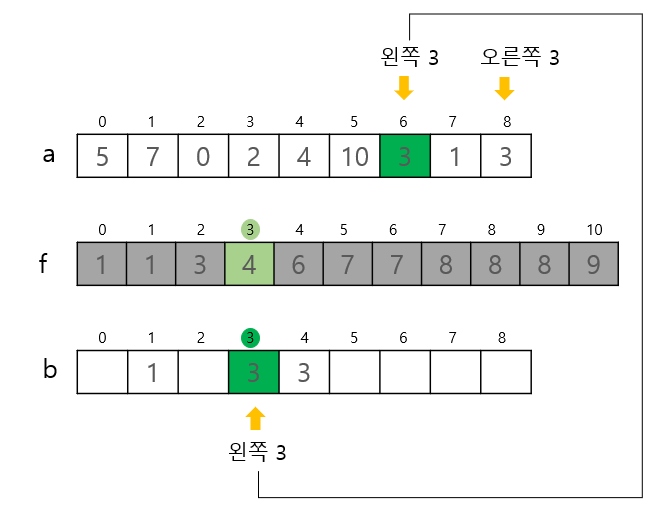
3. 목적 배열 만들기
-
설명
이미 배열 a의 값들이 몇 번째에 위치하는지 알수 있으므로 정렬을 거의 마쳤다고 봐도 된다.
배열 a의 각 요솟값과 누적도수분포표 f를 대조하며 정렬 작업을 해야한다. a와 같은 크기의 작업용 목적 배열 b가 필요하다. 또한 아래 그림의 예제와 a배열의 3과 같이 중복되는 값이 있을수 있기 때문에 끝에서 부터 첫 요소까지 스캔하여 순서 반대로 바뀌는 것을 방지한다.(누적 도수 분포포를 처음부터 스캔했기 때문에) -
코드
a[i]가 f[a[i]]번째 숫자임을 뜻함, 따라서 b배열의 인덱스 하나 줄여야 f[a[i]]번째 값이다.(f배열의 값들도 1씩 감소하여 삭제됨)
n - 1 부터 스캔하여 순서 반대로 바뀌는 것을 방지(누적 도수 분포포를 처음부터 스캔했기 때문에)
/* 목적 배열 만들기 */
for (i = n - 1; i >= 0; i--) b[--f[a[i]]] = a[i];- 그림
4. 배열 복사하기
-
설명
목적 배열 b를 a에 복사하며 정렬 마침 -
코드
/* 배열 복사 */
for (i = 0; i < n; i++) a[i] = b[i];전체 코드
#pragma warning (disable:4996)
#include <stdio.h>
#include <stdlib.h>
/* 도수 정렬 함수(배열의 요소값 0 이상 max 이하)*/
void fsort(int a[], int n, int max) {
int i;
int* f = (int*)calloc(max + 1, sizeof(int)); // 누적 도수
int* b = (int*)calloc(n, sizeof(int)); // 목적 배열 만들기
/* 개수 0으로 초기화 */
for (i = 0; i <= max; i++) f[i] = 0;
/* 도수 분포표 */
for (i = 0; i < n; i++) f[a[i]]++;
/* 누적 도수 분포표 */
for (i = 1; i <= max; i++) f[i] += f[i - 1];
/* 목적 배열 만들기 */
/* a[i]가 f[a[i]]번째 숫자임을 뜻함, 따라서 b배열의 인덱스 하나 줄여야 f[a[i]]번째 값임 */
/* 끝에서 부터 스캔하여 순서 반대로 바뀌는 것을 방지(누적 도수 분포포를 처음부터 스캔했기 때문에)*/
for (i = n - 1; i >= 0; i--) b[--f[a[i]]] = a[i];
/* 배열 복사 */
for (i = 0; i < n; i++) a[i] = b[i];
free(f);
free(b);
}
int main() {
int nx;
int* x = NULL;
int max = 100;
scanf("%d", &nx);
if ((x = (int*)calloc(nx, sizeof(int))) == NULL)
return -1;
for (int i = 0; i < nx; i++)
scanf("%d", &x[i]);
fsort(x, nx, max); // 도수 정렬 함수 호출
for (int i = 0; i < nx; i++)
printf("%d ", x[i]);
free(x);
return 0;
}도수 정렬 정리
- 장점
- 데이터의 비교, 교환 작업이 없어 매우빠름
- 단일 for문만을 사용하여, 재귀 호출, 이중 for문 없어 매우 효율적
- 범위 조건이 있는 경우 시간복잡도 O(n)/공간복잡도 O(n), n = 배열값의 최대값 - 최솟값
- 안정적인 알고리즘
- 단점
- 최솟값, 최댓값 미리 알고 있는 경우에만 사용 가능
- 최소값과 최댓값, 최댓값과 최솟값 차에 의해 시간과 공간 제약
- 데이터 타입이 일정해야한다.

To put up a flag.