자료구조 알고리즘(C)
1.이진 검색(Binary Search)
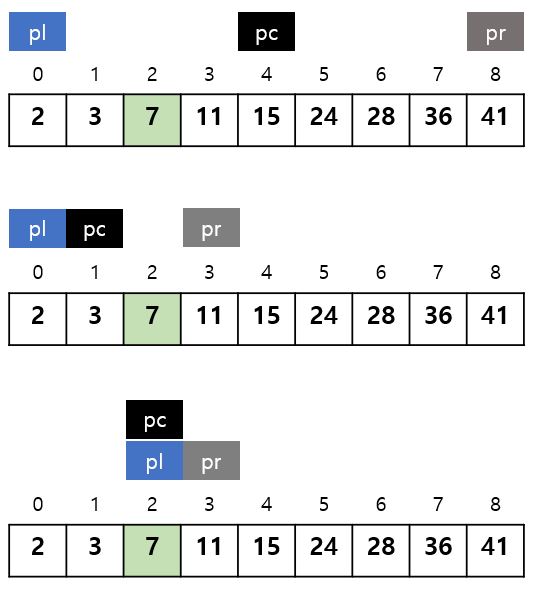
이진 검색의 알고리즘을 적용하는 전제 조건은 데이터가 키 값으로 이미 정렬(Sort)되어 있다는 것입니다. 아래의 이진 검색 알고리즘은 아래와 오름차순이나 내림차순으로 정렬이 되어있단 가정하에 key값을 찾습니다. 알고리즘 종료 조건에는 다음과 같은 경우가 있습니다.
2.bsearch 함수 구현
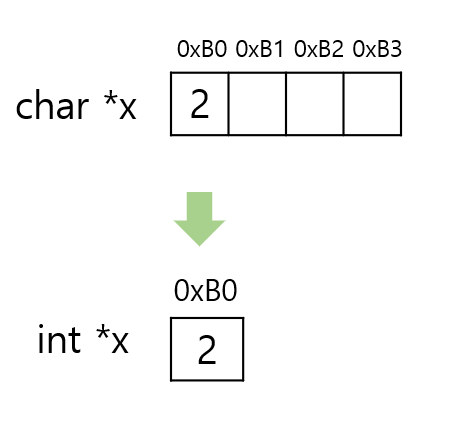
bsearch 함수와 같은 형식으로 호출할 수 있는 함수를 구현해봅시다.아래의 binsearch 함수는 bsearch와 동일한 함수입니다.자료형은 정수, 문자, 문자열, 구조체등 모두 사용할 수 있습니다. 그치만 대소 관계를 판단하는 방법은 요소의 자료형마다 다릅니다.
3.스택(Stack)에 대해서
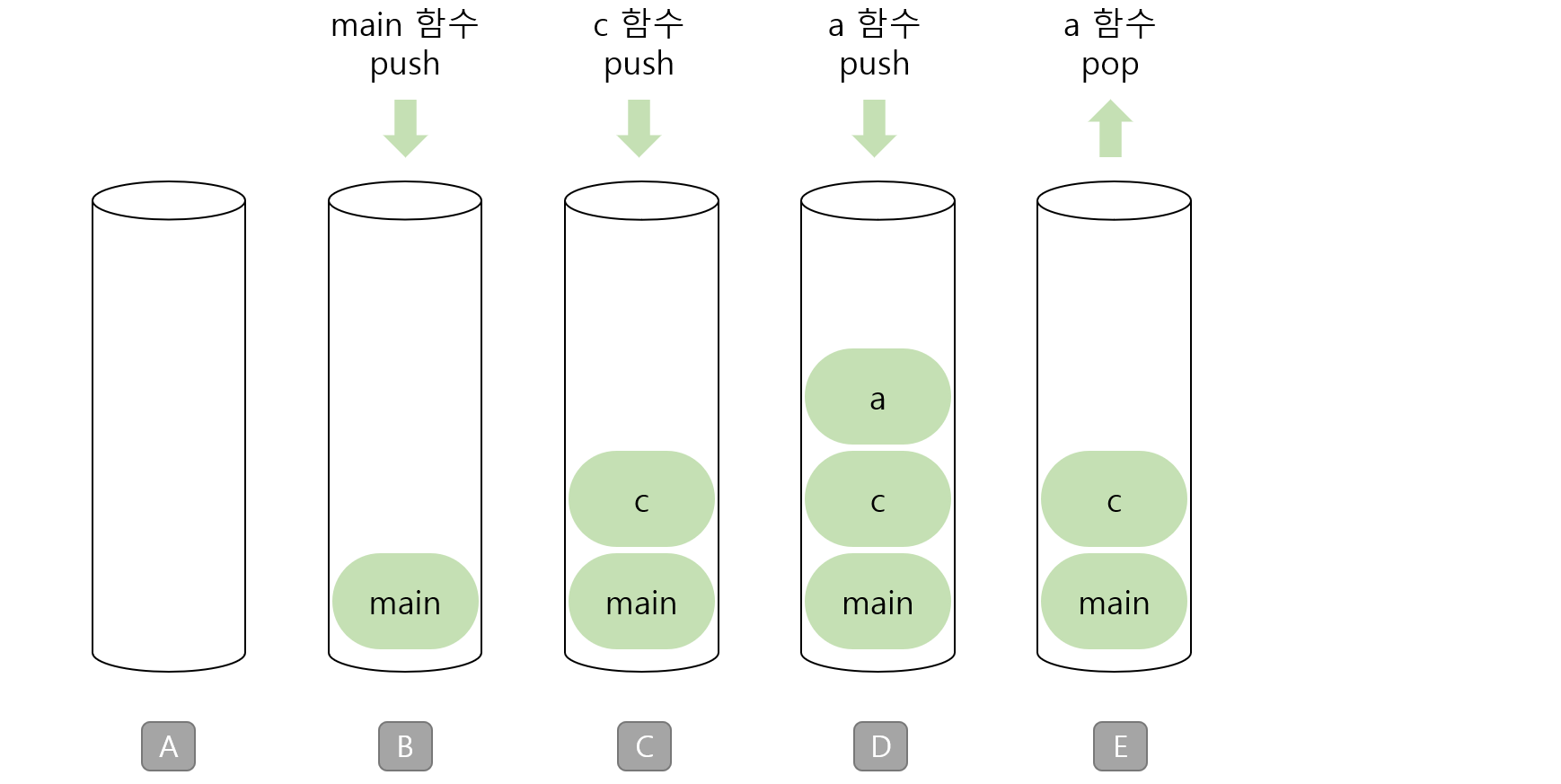
스택이란? 스택은 데이터를 일시적으로 저장하기 위해 사용하는 자료구조입니다. 데이터의 입력과 출력 순서는 후입선출(LIFO:Latt In First Out)입니다. C언어 프로그램에서 함수를 호출하고 실행할 때 프로그램 내부에서는 스택을 사용합니다. push : 데이
4.큐(queue)에 대해서
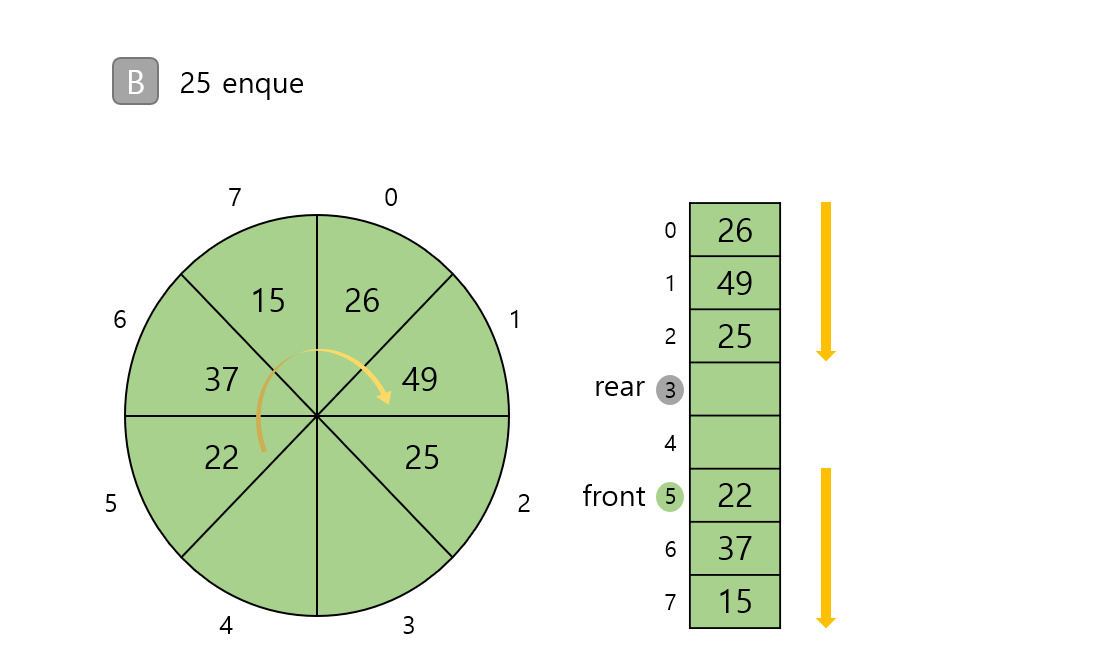
큐란? 큐(queue)는 스택과 마찬가지로 테이터를 일시적으로 쌓아 두기 위한 자료구조입니다. 데이터의 입력과 출력 순서 : 선입선출(FIFO) 구조 큐 활용 예시 : 프린터의 인쇄 대기열, 은행 업무 enque : 데이터를 넣는 작업 deque : 데이터를 꺼내는
5.덱(Deque)에 대해서
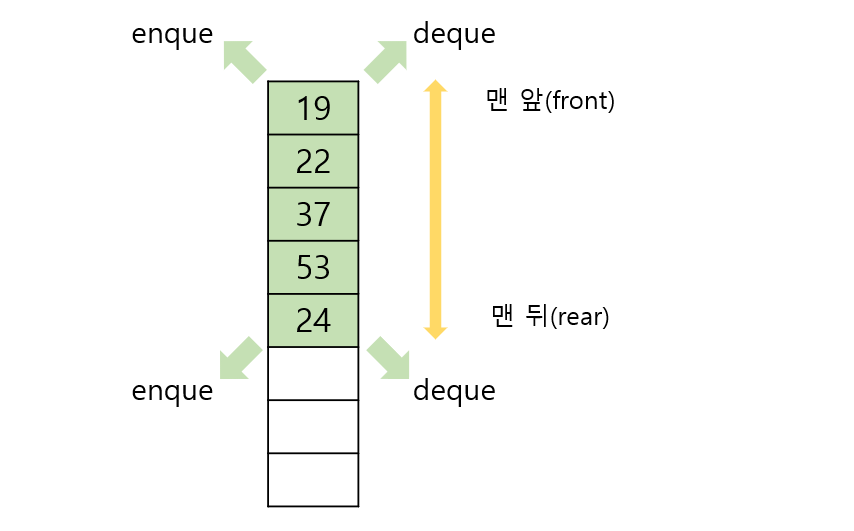
덱이란?양방향 대기열(Double ended queue)은 아래 그림처럼 시작과 끝 지점에서 양쪽으로 데이터를 인큐하거나 디큐하는 자료구조입니다. 덱을 구현하는 프로그램덱을 구현하는 프로그램을 구현해봅시다.덱은 큐와 유사하며 양방향으로 enque와 deque가 할수 있
6.재귀(Recursion)의 기본
재귀란(recursion)?어떤 사건이 자신을 포함하고 다시 자기 자신을 사용하여 정의될 떄 재귀적(recursive)이라고 합니다.재귀와 반복문의 비교반복문으로 순차곱셈 값을 구하는 방법과 재귀 알고리즘의 대표적인 순차곱셈 값을 구하는 비교해봅시다.반복문 이용반복문의
7.재귀 알고리즘 분석(Recursive Algorithm)
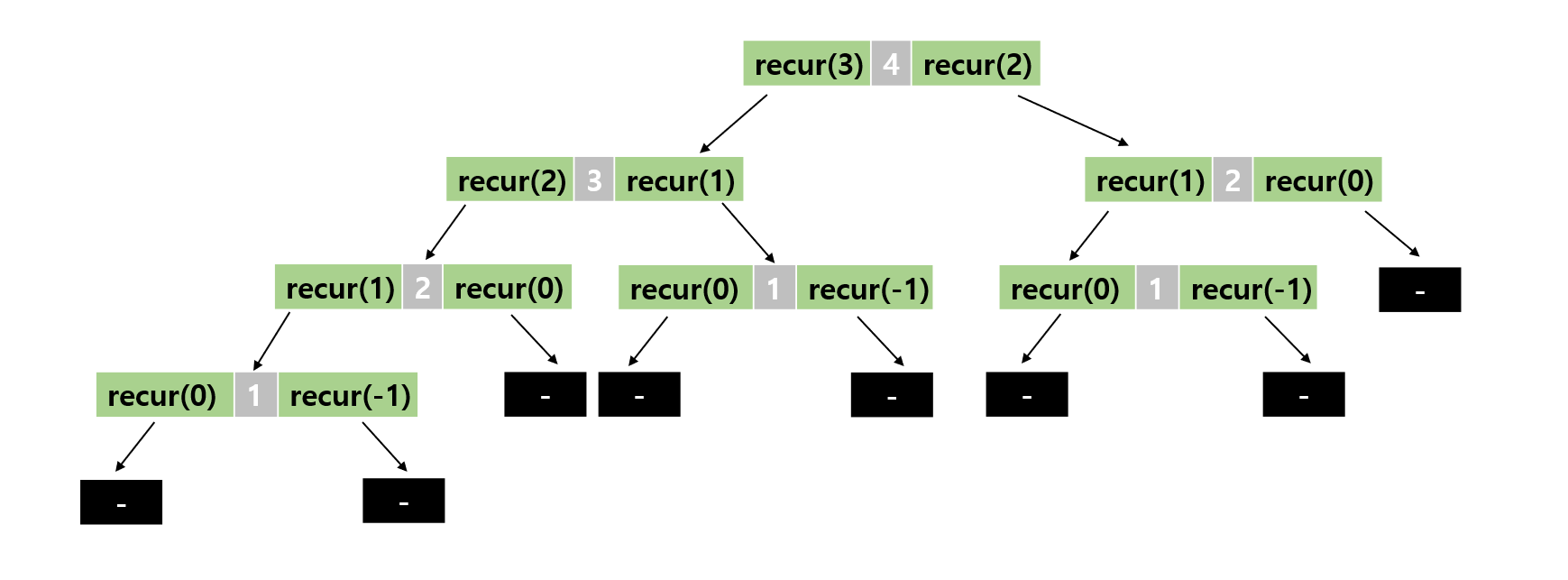
재귀 알고리즘 분석 재귀 알고리즘 분석에는 두가지 분석 방법이 있습니다. 하향식(top down) 상향식(bottom up) 아래의 예제를 하여금 분석해봅시다 이 예제의 재귀 호출은 함수 안에서 2번 실행됩니다. 그러면 실제 동작은 매우 복잡해집니다. 이런 복잡한
8.하노이의 탑(Hanoi Tower)
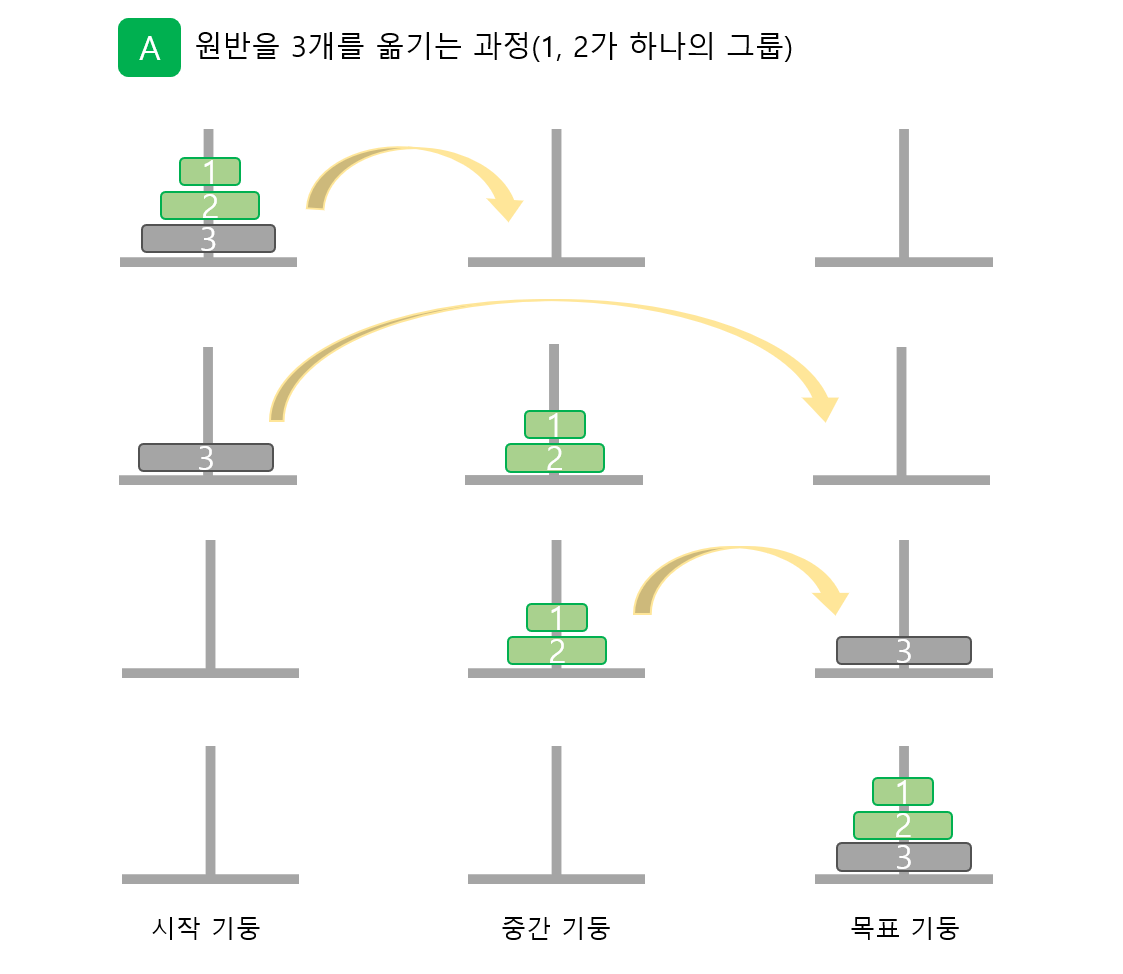
하노이의 탑하노이의 탑(Towers of Hanoi)은 작은 원반이 위에, 큰 원반이 아래에 위치할 수 있도록 원반을 3개의 기둥 사이에서 옮기는 문제입니다. 모든 원반은 크기가 다르고 처음에는 모든 원반이 규칙에 맞게 첫 번쨰 기둥에 쌓여 있습니다. 이 상태에서 모든
9.8퀸 문제(8 Queen Problem)
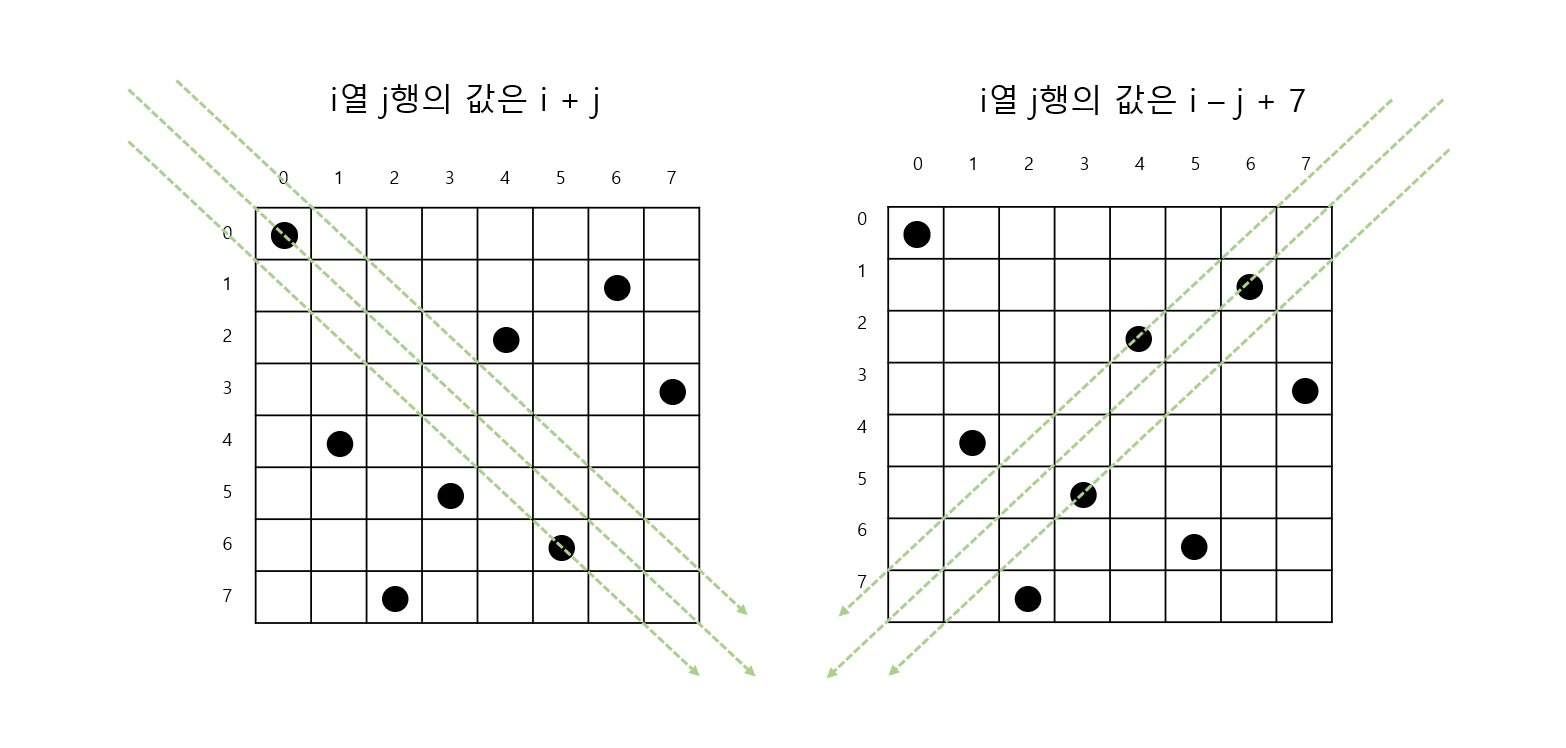
8퀸 문제란? 서로 공격하여 잡을 수 없도록 8개의 퀸을 8 * 8 체스판에 놓으세요. 퀸은 가로, 세로, 대각선방향으로 체스판 끝까지 움직일 수 있습니다. 8개의 퀸을 놓는 조합은 모두 체스판은 총 64개 이므로 646362...321으로 매우 많은 조합이 나옵니
10.버블 정렬(Bubble Sort)

버블 정렬위의 그림과 아래의 알고리즘는 버블 정렬을 오름차순으로 정렬한 것입니다.마주한 두 배열의 요소를 비교하여 앞의 요솟값이 뒤의 요솟값보다 크면 교환해줍니다. 이런한 비교와 교환작업을 pass라고 합니다. 마주한 두개의 요소씩 비교함으로 첫번째는 pass 횟수가
11.선택 정렬(Selection Sort)

단순 선택 정렬 단순 선택 정렬은 요소를 검사하면서 가장 작은 요소부터 정렬하는 알고리즘이다. 아래 그림과 같이 아직 정렬하지 않은 부분에서 값이 가장 작은 요소를 선택하고 아직 정렬되지 않은 부분의 첫 번째 요소와 교환한다. 코드 단순 선택 정렬 교횐 과정 아직
12.삽입 정렬(Insertion Sort)
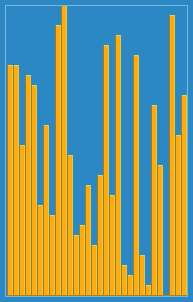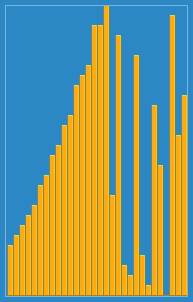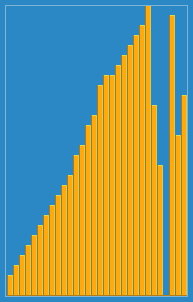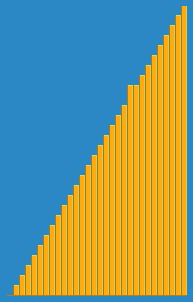
단순 삽입 정렬아직 정렬되지 않은 부분의 첫 번째 요소를 정렬된 부분의 알맞은 위치에 삽입삽입 과정정렬된 열의 왼쪽 끝에 도달tmp보다 작거나 같은 key를 갖는 항목 aj를 발견 및 교환단순 삽입 알고리즘교환 과정j가 > 0보다 큼aj - 1 즉, 그 전 값이 tmp
13.셸 정렬(Shell Sort)
단순 선택/삽입 정렬 단순 삽입 정렬의 장점은 살리고 단점은 보완하여 좀 더 빠르게 정렬하는 알고리즘 삽입 정렬의 장점 단순 선택 정렬과 비교해서 떨어져 있는 요소들이 서로 뒤바뀌지 않아 안정적임 정렬을 마쳤거나 정렬을 마친 상태에 가까우면 정렬 속도가 매우 빠름
14.퀵 정렬(Quick Sort)
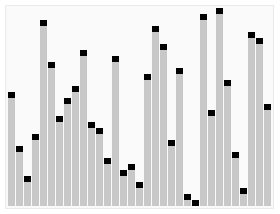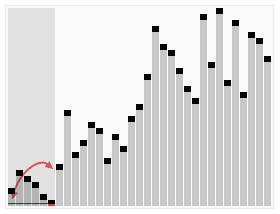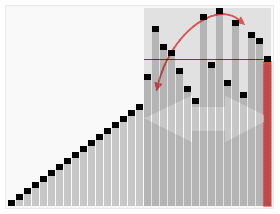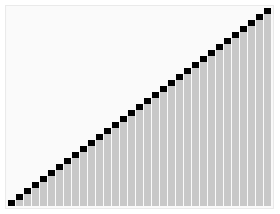
먼저 그림을 통해 직관적으로 이해해보자. 각 그룹에 대해 피봇을 설정하고, 그 피봇을 기준으로 기준값 이상/이하를 나눠 두 그룹으로 분할하는 정렬이다. 위의 그림의 일반적인 예시처럼 분할 과정(깊이)이 logN만큼 소요되고 요소의 개수가 N개이므로 평균 시간 복잡도는
15.병합 정렬(Merge Sort)
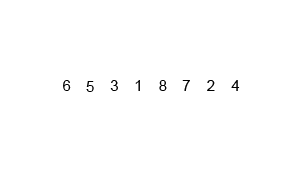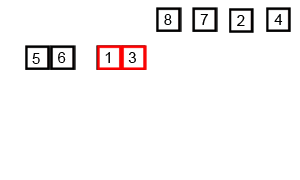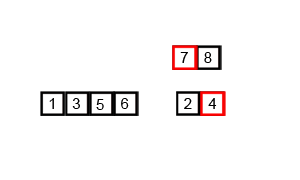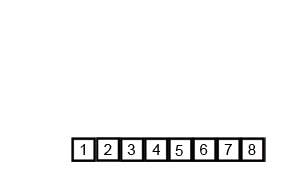
병합 정렬 과정 분할 : 배열을 같은 크기(n/2) 2개(왼쪽 부분, 오른쪽 부분)로 나눈다. 정복 : 재귀함수 순환호출을 통한 분할&병합 병합 : 왼쪽 부분, 오른쪽 부분 배열을 정렬하며 합침 병합 정렬 장점 시간 복잡도 O(nlogn)으로 굉장히 빠름 서로 떨어져
16.힙 정렬(Heap Sort)
.gif)
완전이진트리(complete binary tree) 완전 : 루트(root) 노드부터 시작해 왼쪽, 오른쪽 순으로 자식 노드부터 추가하는 모양 이진 : 부모가 가질수 있는 자식의 개수는 최대 2개 트리 : 요소의 상하 관계를 부모(parent)와 자식(child),
17.도수 정렬(Counting sort)
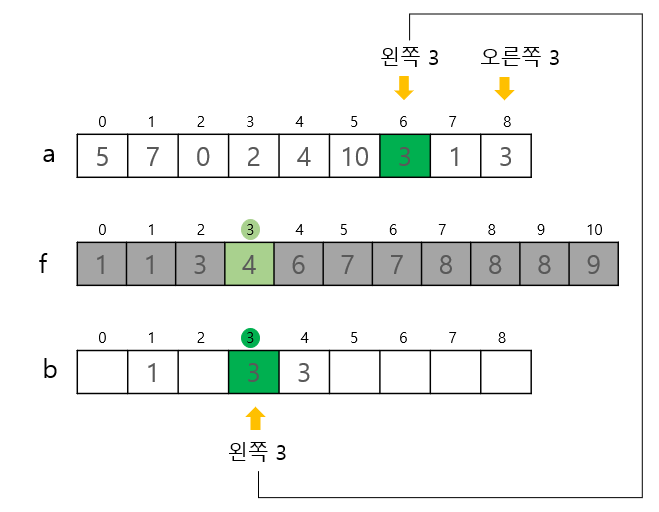
도수 정렬 특징 선택, 삽입, 퀵, 병합, 힙 정렬과 다르게 키 값의 비교가 불필요함 크기를 기준으로 개수만 세주어 위치를 바꿀 필요없음 모든 데이터에 한 번씩만 접근하여 되게 효율적임 범위 조건이 있는 경우에 한해서 굉장히 빠름 >도수 정렬 단계 1. 도수분포표
18.비트 벡터(Beat Vector)
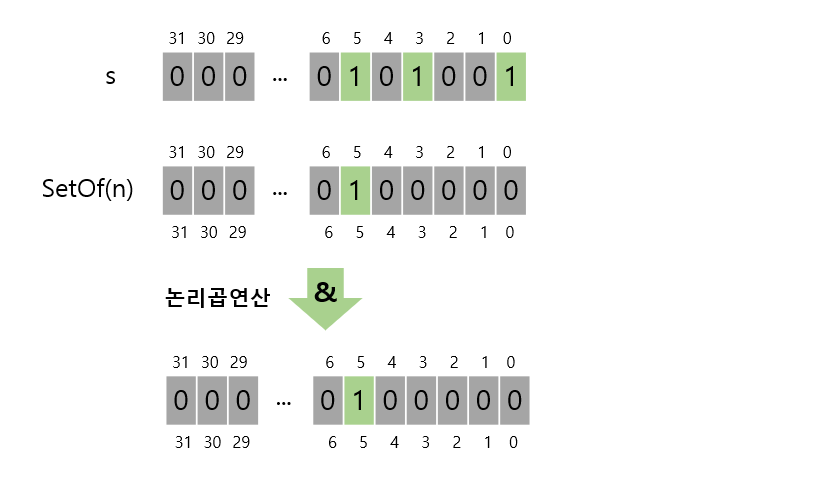
비트 벡터로 집합 만들기 unsigned long형이 32비트라고 가정하면, 이때 정수를 구성하는 비트의 나열을 비트 벡터라고 하자. 아래쪽 비트부터 시작하여, 집합의 원소의 유무의 따라 1, 0으로 표시한다. 그러면 32비트의 부호가 없는 정수로 그림과 같은 {1,
19.브루트 포스법(Brute Force Method)

조합 가능한 모든 문자열을 하나씩 대입해 보는 방식으로 암호를 해독하는 방법브루트 포스 공격(brute force attack)에서 유래되었고 무차별 대입 공격등으로도 부른다. 흔히 수학 문제를 원시적으로 푸는 방법인 '수 대입 노가다' 방법이며, 주로 암호학에서 연구
20.Kmp 문자열 탐색
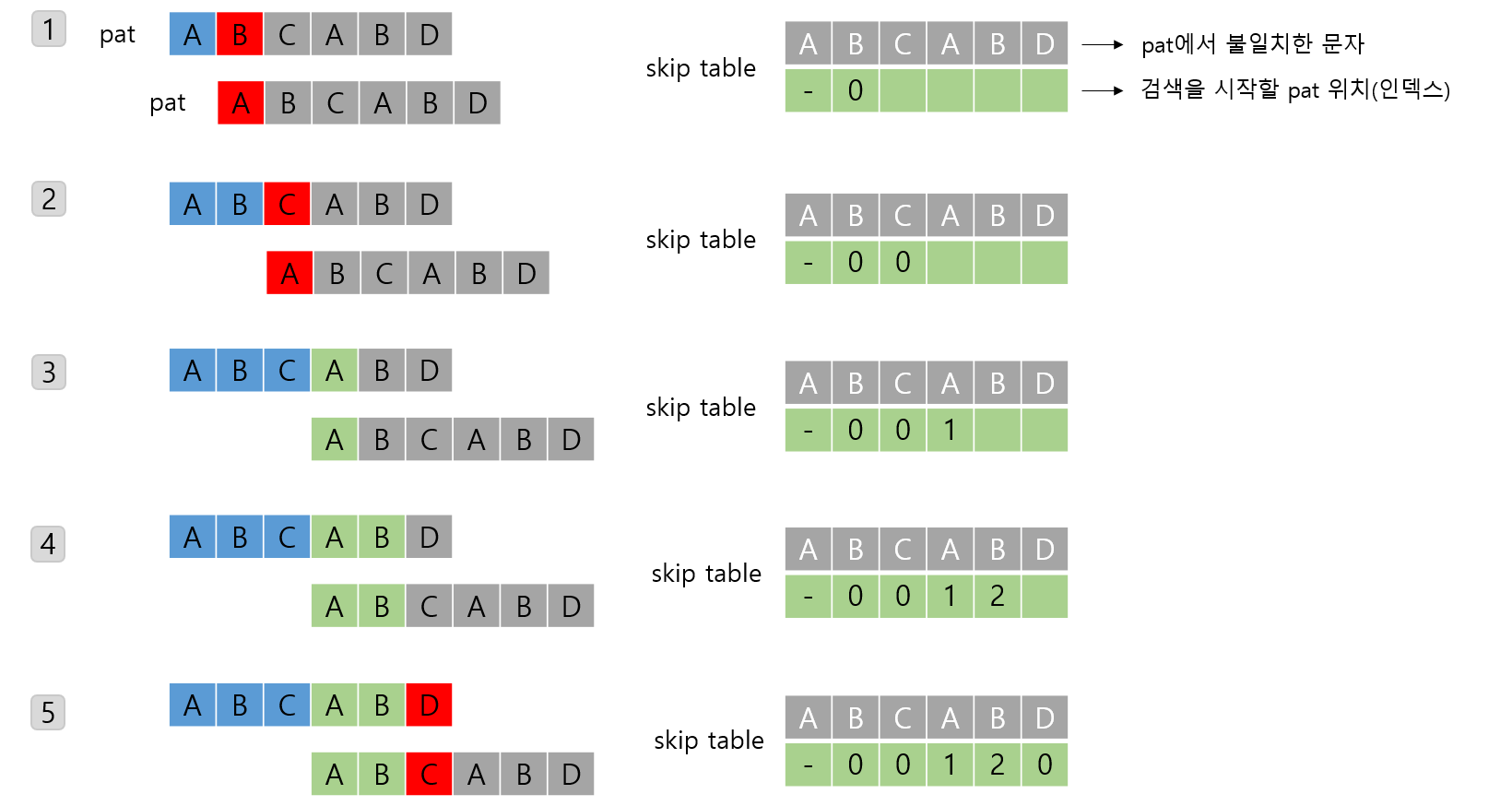
문자열 탐색 비교 kmp(Knuth-Morris-Pratt) 알고리즘은 문자열 탐색시 불필요한 탐색과정을 없애주는 알고리즘이다. 예를 들어 아래와 같이 ZABCABCABD에서 ABCABD를 찾을 경우이다. 왼쪽의 단순 문자열 탐색은 하나씩 차례되로 비교한다. 반면에