단순 삽입 정렬의 장점은 살리고 단점은 보완하여 좀 더 빠르게 정렬하는 알고리즘
- 삽입 정렬의 장점
- 단순 선택 정렬과 비교해서 떨어져 있는 요소들이 서로 뒤바뀌지 않아 안정적임
- 정렬을 마쳤거나 정렬을 마친 상태에 가까우면 정렬 속도가 매우 빠름(이동 회수 줄임)
- 삽입 정렬의 단점
- 삽입할 위치가 멀리 떨어져 있으면 이동횟수가 많아짐
- 삽입 정렬은 입력되는 초기 리스트가 "거의 정렬"되어 있을 경우 효율적
- 삽입 정렬은 한 번에 한 요소의 위치만 결정되기 때문에 비효율적
- 셸 정렬의 보완책
- 삽입할 위치가 멀리 떨어져 있으면 이동횟수가 많아짐 > 삽입정렬보다 정렬횟수는 늘지만 이동이 줄어듦
- 삽입 정렬은 한 번에 한 요소의 위치만 결정되기 때문에 비효율적 > 설정 간격으로 정렬
- 셸 정렬(shell sort) 과정
- 먼저 정렬한 요소를 그룹으로 나눠 각 그룹별로 단순 삽입 정렬 수행
- 그 그룹을 합치면서 정렬 반복하여 요소의 이동회수 줄임
[8, 1, 4, 2, 7, 6, 3, 5] 배열이 있다면 4개의 그룹으로 나눈다.
{8, 7}, {1, 6}, {4, 3}, {2, 5} 그룹으로 나누고 그룹별로 정렬을 한다. 아후 정렬후 그 그룹을 합치고 정렬하기를 반복!(아래의 그림 참고)
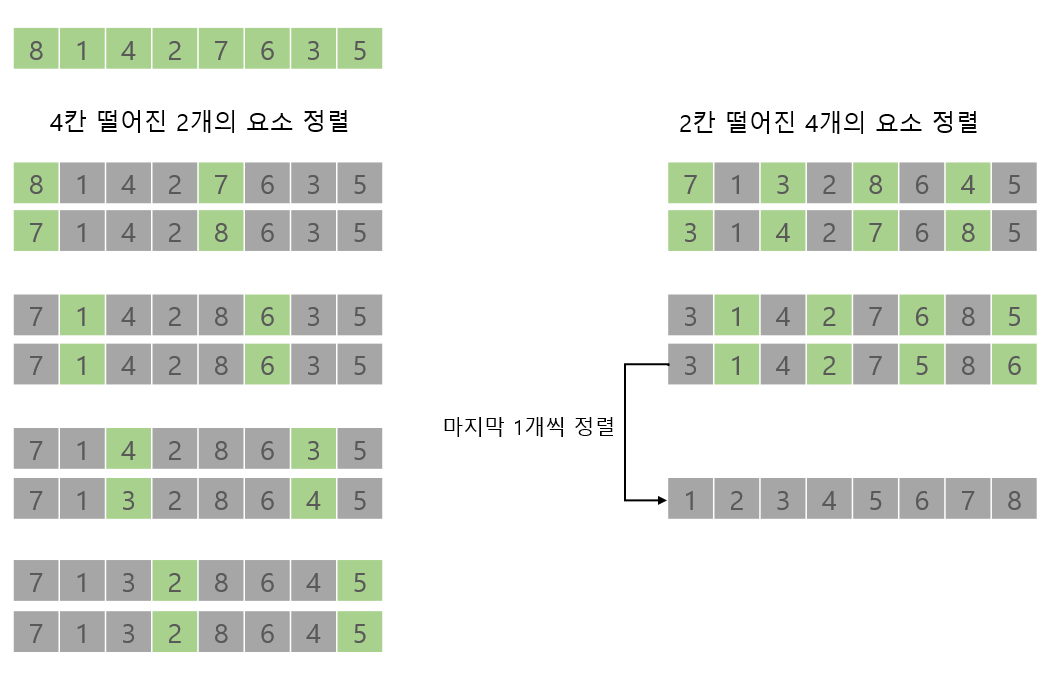
삽입 정렬보다 정렬 횟수는 늘지만 이동이 줄어들어 효율적이게 됨
- 알고리즘 코드(그룹 개수 2씩 줄이며 진행)
void shell(int a[], int n) {
int i, j, h;
for (h = n / 2; h > 0; h /= 2) { // 2씩 나누면서 그룹 생성(그룹내 데이터는 2배씩 커짐)
for (i = h; i < n; i++) { // 그룹 내에서 전값과 비교
int tmp = a[i]; // 삽입할 값 저장
for (j = i - h; j >= 0 && a[j] > tmp; j -= h) // 그룹내의 삽입 할 값의 앞만 검사
a[j + h] = a[j]; // 그룹내에서 뒤로 한 칸씩 옮김
a[j + h] = tmp; // 삽입할 값 대입
}
}
}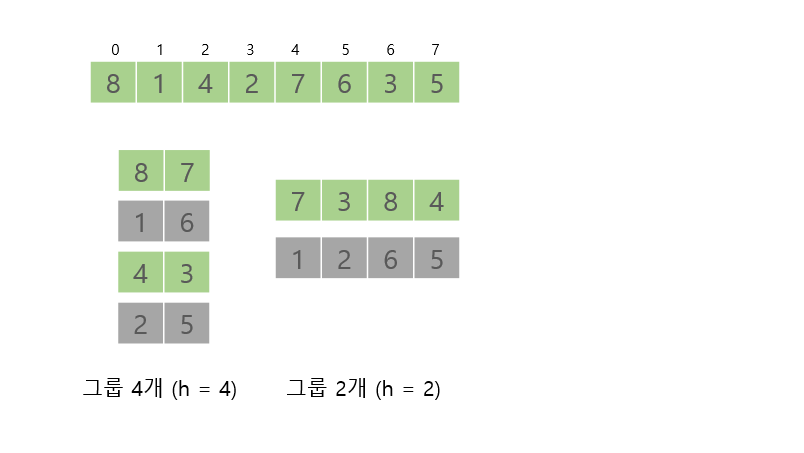
그림에서 보면 초록색 그룹과 회색그룹은 서로 섞이지 않는다. 그 다음 그룹 2개가 그룹 1개가 될때도 맨 처음 배열에서 정렬하는 것과 같이 된다. 따라서 h의 값이 서로 배수가 되지 않도록 해야한다. 이렇게 하면 효율적인 정렬을 기대할수있다.
-
그룹을 나누는 수열
h = ..., 121, 40, 13, 4, 1
1부터 시작해 3n + 1 수열 만족
h의 초기값은 너무 크면 효과가 없기 때문에 배열의 요소 개수 n을 9로 나눈 값을 넘지 않도록 한다. -
알고리즘 코드
void shell(int a[], int n) {
int i, j, h;
int cnt = 0;
for (h = 1; h < n / 9; h = h * 3 + 1) // h를 1부터 시작하고 3n + 1씩 커짐
;
for (; h > 0; h /= 3) {
for (i = h; i < n; i++) { // 그룹 내에서 전값과 비교
int tmp = a[i]; // 삽입할 값 저장
for (j = i - h; j >= 0 && a[j] > tmp; j -= h) // 그룹내의 삽입 할 값의 앞만 검사
a[j + h] = a[j]; // 그룹내에서 뒤로 한 칸씩 옮김
a[j + h] = tmp; // 삽입할 값 대입
}
}
}위의 알고리즘에서 h /= 3을 통해 3씩 나눠주면 다음과 같은 원리다. 위의 코드 for (h = 1; h < n / 9; h = h * 3 + 1)의 3n + 1 수열에서 3을 나눠주면 n이 되기 때문이다. 예를들어, 13 / 3 = 4, 4 / 3 = 1 이므로 3n + 1 수열을 만족한다.
개선전의 셸 정렬같이 [8, 1, 4, 2, 7, 6, 3, 5]배열에서 그룹으로 나뉜후 다시 한개의 그룹으로 합칠때 처음의 배열을 정렬하는 것과 같았지만, 개선 후에는 h 초기값이 1로 시작하여 바로 한 개씩 정렬에 들어가게 되고 총체적으로 같은 배수가 아닌 인덱스 끼리 섞이며 정렬되기때문에 효율적이게 된다.
-
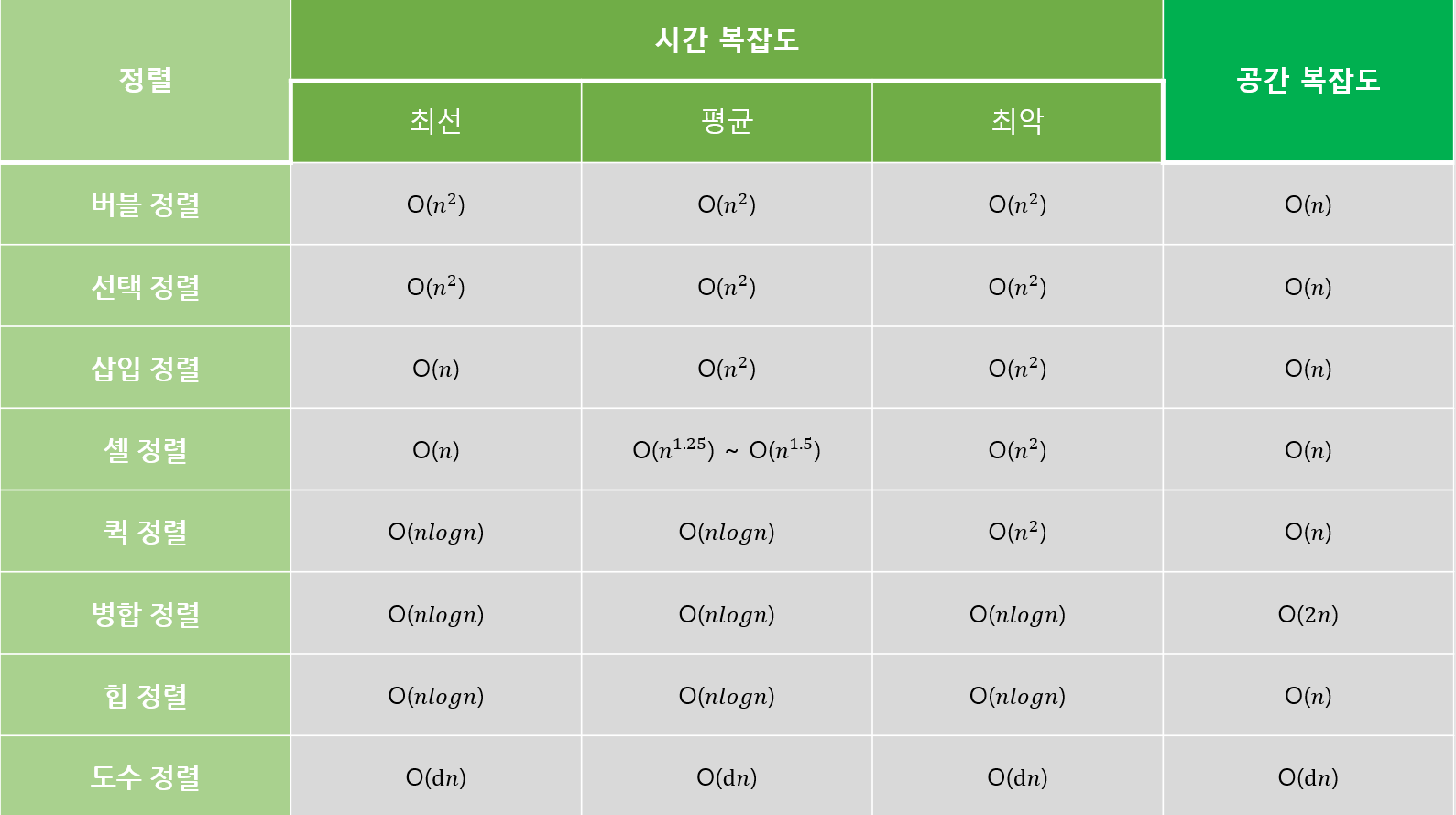
시간복잡도
최선의 경우: O(n^1.25)
평균: O(n^1.5)
최악의 경우: O(n^2) -
셸 정렬 장점
다른 빠른 정렬의 O(𝑛𝑙𝑜𝑔𝑛)보다 빠를때도 있다. -
셸 정렬 단점
떨어진 리스트를 교환하므로 불안정적