DB 모델링은 체계적인 순서를 가진다.
DB 모델링 순서는 개념적 모델링 -> 논리적 모델링 -> 물리적 모델링을 거친다.
위 과정을 통해 실제 업무에 필요한 DB가 만들어진다. 하나씩 살펴보자.
DB 모델링의 첫번째 과정은 개념적 모델링이다.
개념적 DB 모델링의 정의는 아래와 같다.
업무분석을 바탕으로 우선 개체를 추출하고 개체 내에 속성을 구성하며 개체 간의 관계를 정의해서 ER-Diagram을 정의하는 단계
개념적 DB 모델링은 아래와 같이 이뤄진다.

ER-Diagram의 예시는 아래와 같다.
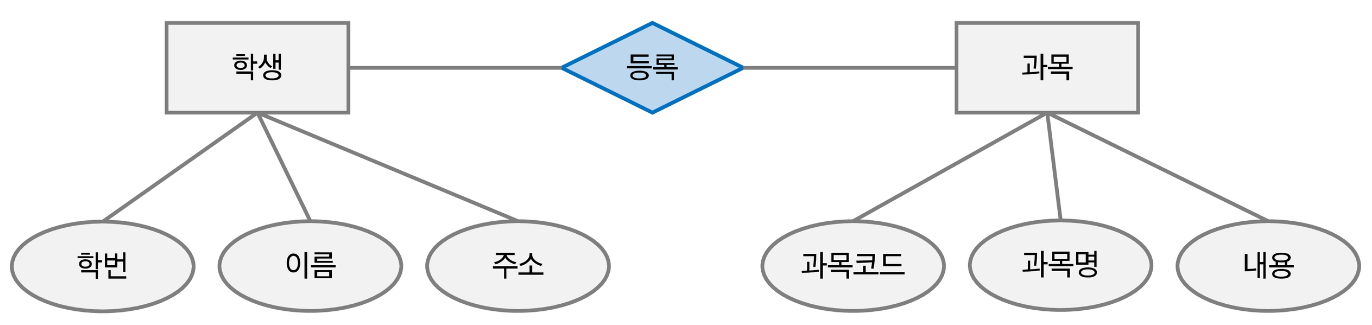
네모는 개체, 타원은 속성, 마름모는 관계를 의미한다.
개체의 정의는 아래와 같다.
사용자와 관계가 있는 주요 객체로써 업무 수행을 위해 데이터로 관리되어야 하는 사람, 사물, 장소, 사건 등
개체를 찾는 법은 아래와 같다.
- 영속적으로 존재한다.
- 새로 식별이 가능한 데이터 요소를 가진다.
- 개체는 반드시 속성을 가진다.
- 명사적으로 표현이 가능하다.
속성의 정의는 아래와 같다.
개체의 성질, 분류, 수량 등을 나타내는 세부사항
속성의 종류는 아래와 같다.
- 기초 속성 : 기본적으로 제공되는 속성
- 추출 속성 : 기초 속성에서 계산을 통해 얻어지는 속성
- 설계 속성 : 실제로 존재하진 않치만 시스템의 효율성을 위해 설계자가 임의로 부여하는 속성
식별자의 정의는 아래와 같다.
한 개체 내에서 인스턴스를 유일하게 구분할 수 있는 단일 속성 또는 속성 그룹
식별자의 종류는 아래와 같다.
- 후보키 : 개체 내에서 인스턴스를 구분할 수 있는 속성
- 기본키 : 후보키 중 각 인스턴스를 유일하게 식별하기 위해 선정된 하나의 속성
- 대체키 : 후보키 중에서 기본키로 선정되지 않은 속성
- 복합키 : 둘 이상의 속성을 묶은 속성
- 대리키 : 필요에 의해 인위적으로 추가한 속성
관계의 정의는 아래와 같다.
두 개체간의 업무적인 연관성
관계를 설정하는 순서는 아래와 같다.
- 관계가 있는 두 실체를 실선으로 연결하고 관계를 부여한다.
예시는 아래와 같다.

- 관계 차수를 표현한다.
차수성이란 한 실체의 인스턴스가 다른 실체의 몇 개의 인스턴스와 관련될 수 있는가를 말해준다.
예시는 아래와 같다.

1:1, 1:N, N:1 N:M 관계가 가능하다.
- 선택성을 표시한다.
선택성이란 있어도 되는지 없어도 되는지를 말해준다.
예시는 아래와 같다.
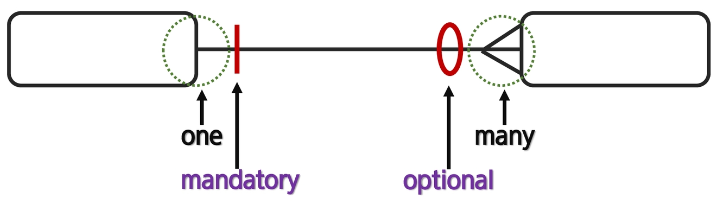
optional이면 개체가 없어도 된다.
DB 모델링의 두번째 과정은 논리적 모델링이다.
논리적 DB 모델링의 정의는 아래와 같다.
ER-Diagram을 Mapping Rule을 적용하여 관계형 DB 이론에 입각한 스키마를 설계하고 필요하다면 정규화를 하는 단계
Mapping Rule은 아래와 같다.
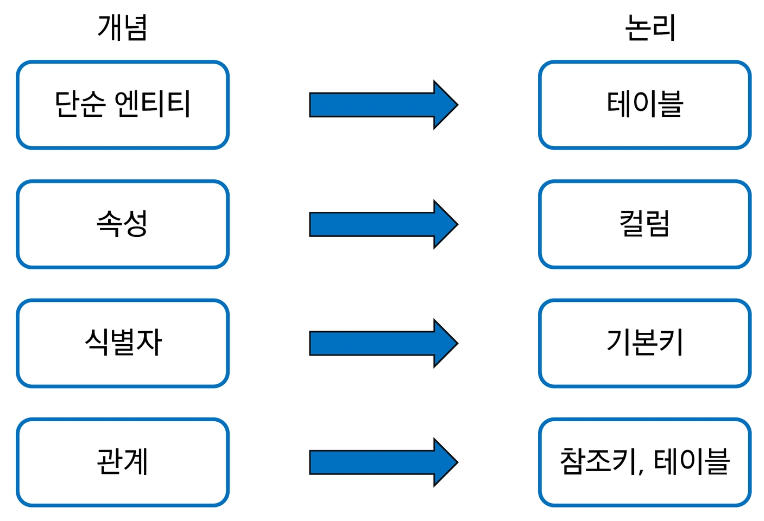
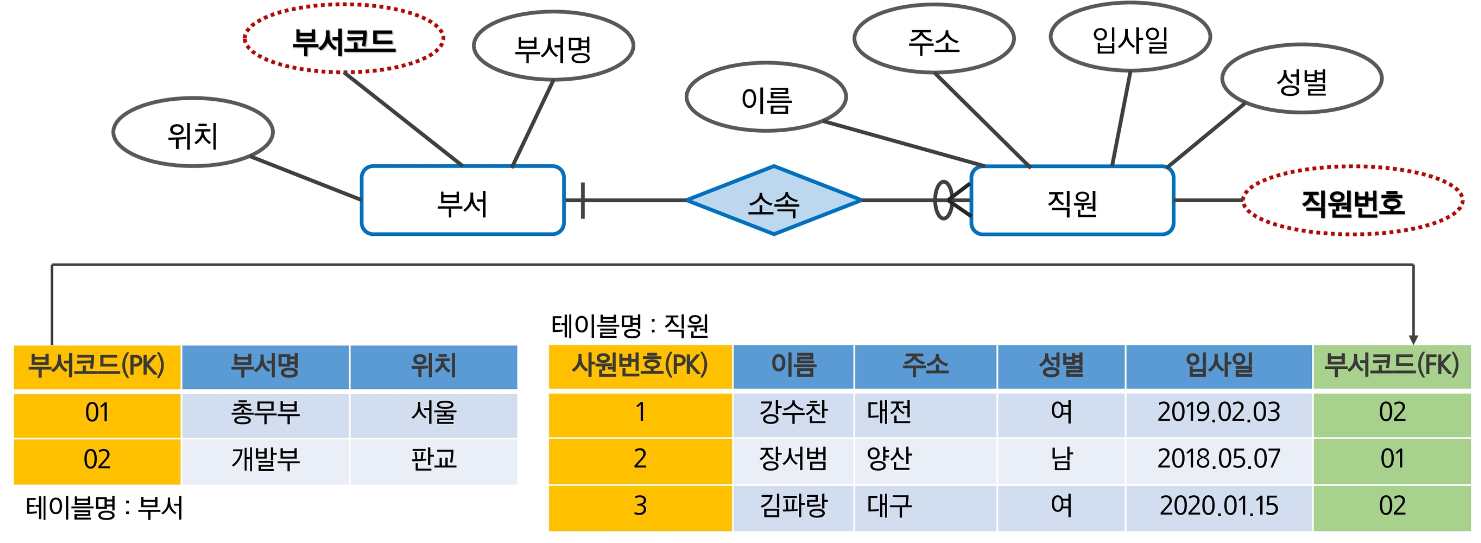
Mapping Rule을 적용한 사례는 아래와 같다.
정규화의 정의는 아래와 같다.
속성간에 존재하는 함수적 종속성을 분석해서 관계형 스키마를 더 좋은 구조로 정제하는 과정
정규화 단계는 아래와 같다. 한 단계씩 살펴보자.
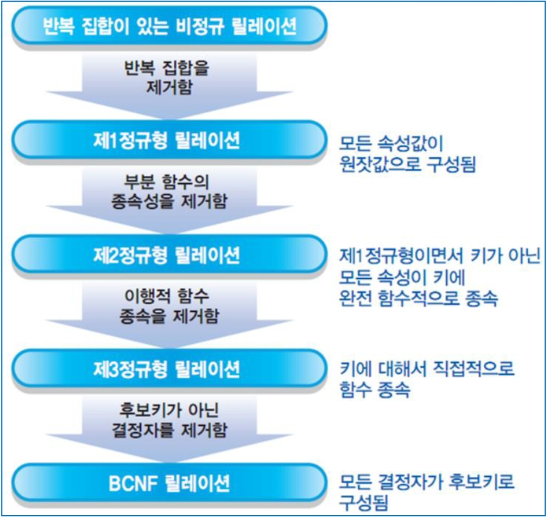
- 제 1 정규화 : 반복되는 그룹 속성을 제거한다.
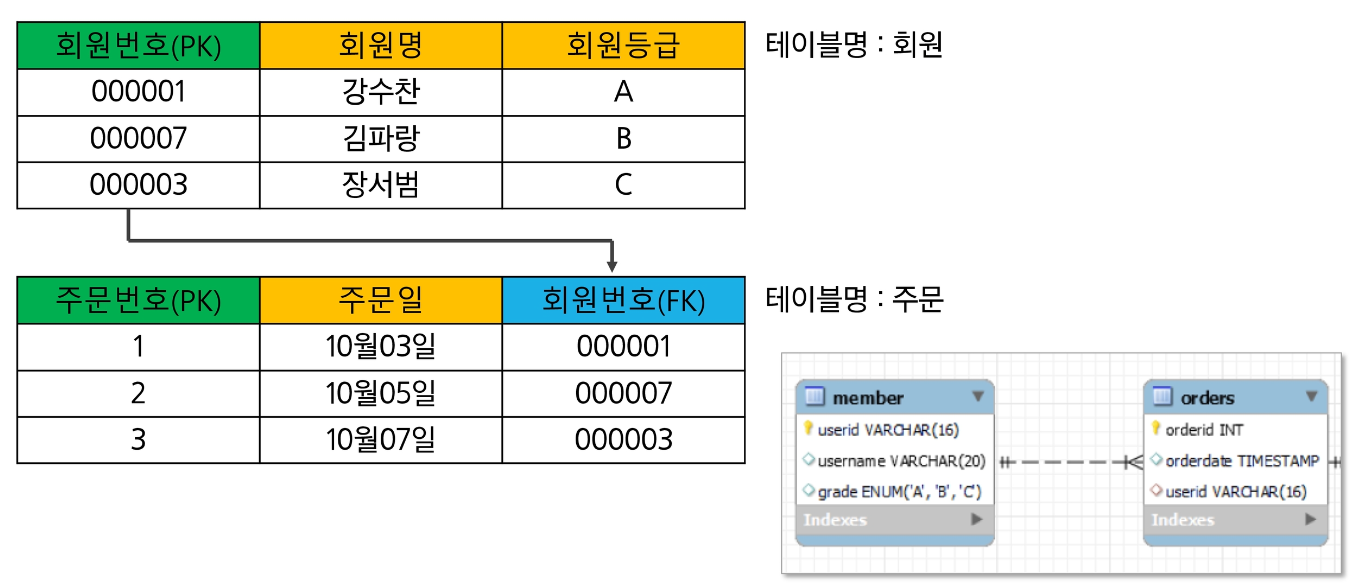
아래는 제 1 정규화 전 테이블을 보여준다.
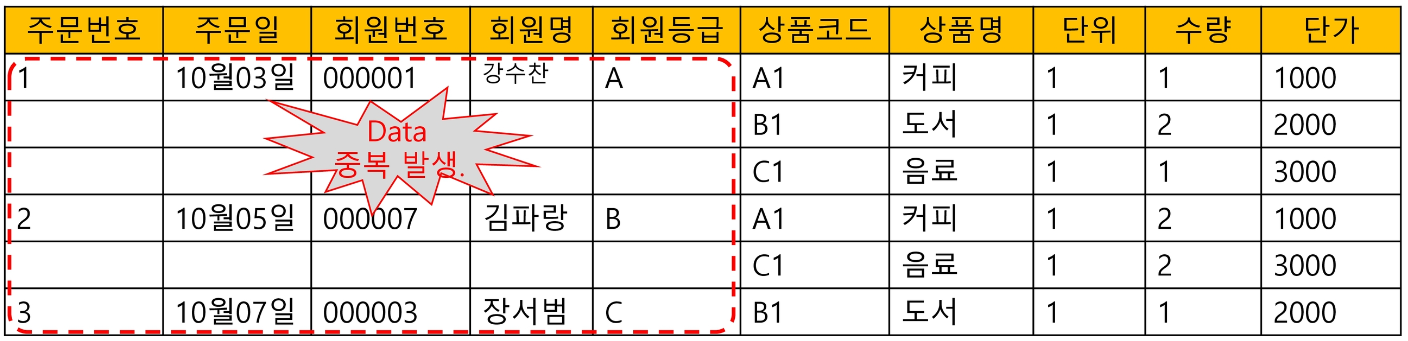
주문번호, 주문일, 회원번호, 회원명, 회원등급이 중복해서 저장됨을 알 수 있다.
따라서 중복성을 없애기 위해 해당 테이블에 제 1 정규화를 적용하면 아래와 같다.
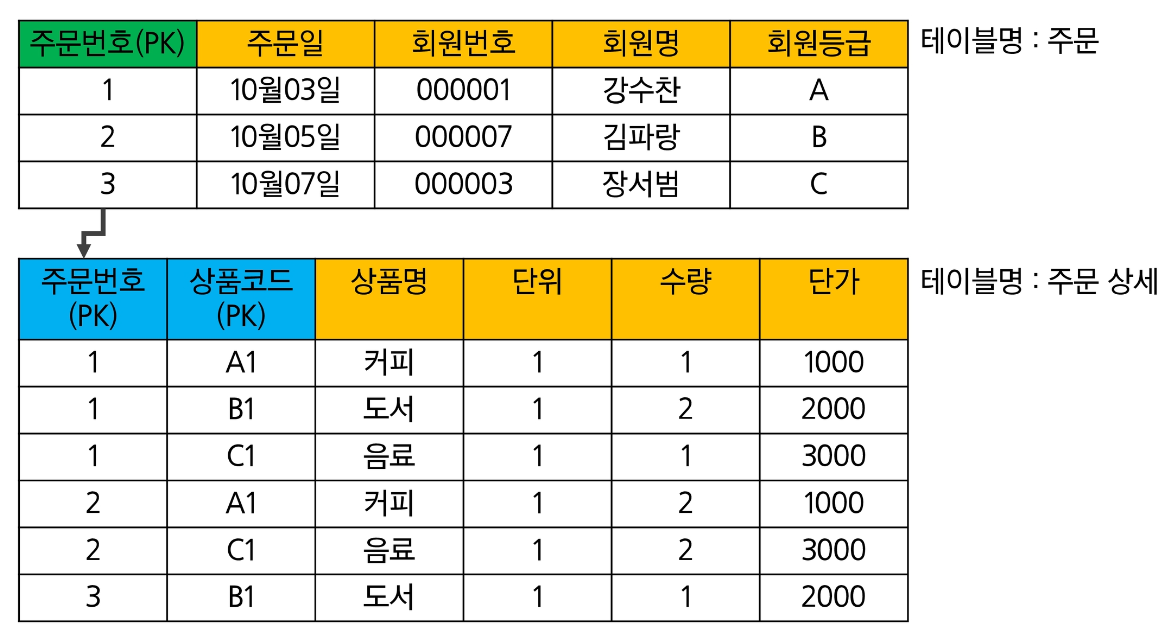
따로 테이블을 만듬으로써 데이터의 중복없이 데이터를 저장할 수 있다.
- 제 2 정규화 : 복합키 중 하나의 속성에 다른 속성이 의존하는 속성을 제거한다.
아래는 제 2 정규화 전 테이블을 보여준다.
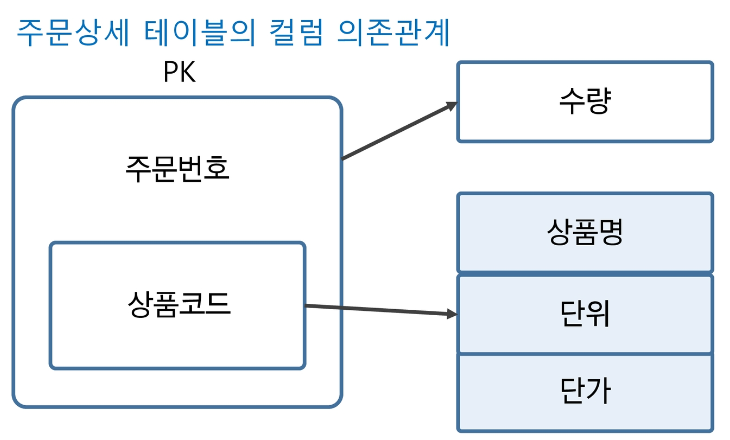
기본키가 (주문번호, 상품코드) 인데, 상품코드 속성에만 의존하는 상품명, 단위, 단가 속성이 존재한다.
따라서 종속성을 없애기 위해 해당 테이블에 제 2 정규화를 적용하면 아래와 같다.
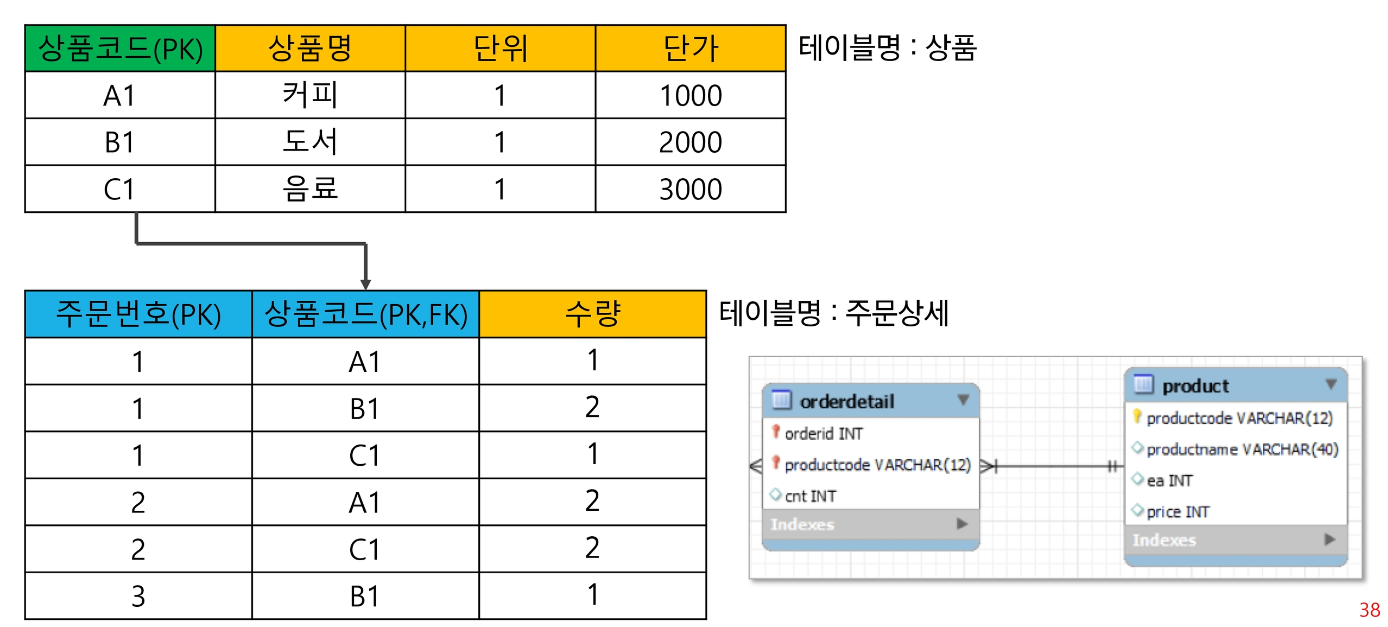
- 제 3 정규화 : 기본키가 의존하지 않고 일반 속성에 의존하는 속성을 제거한다.
아래는 제 3 정규화 전 테이블을 보여준다.
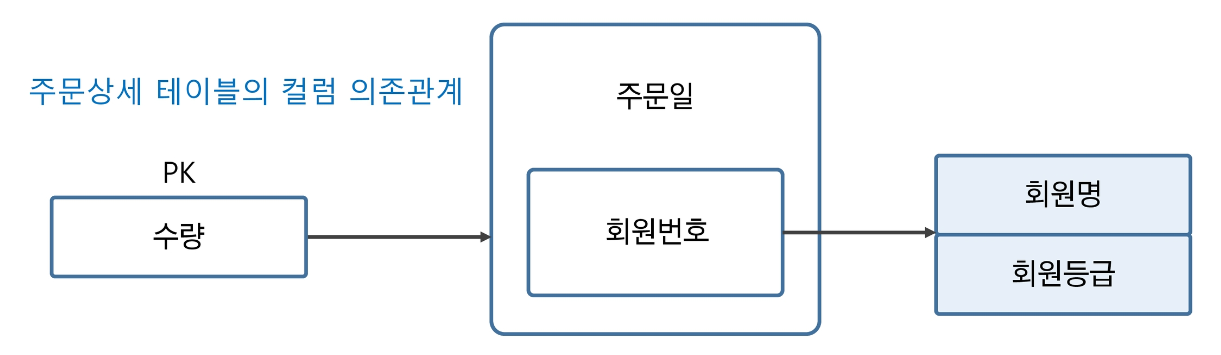
회원번호 속성은 기본키가 아님에도 회원명, 회원등급 속성은 회원번호 속성에 의존한다.
따라서 종속성을 없애기 위해 해당 테이블에 제 3 정규화를 적용하면 아래와 같다.