DBMS 개념
파일 시스템 (DBMS가 없던 때)
문제점
1) 중복저장
데이터 중복 저장으로 저장 공간이 낭비됨, 중복 데이터로 인해 변경시
일관성 유지가 어렵고, 오류 발생 가능성이 증가함.

2) 응용 프로그램의 데이터 파일 종속성
파일 구조 변경시 모든 응용 프로그램도 수정해야할 수 있음.
3) 병행 처리의 어려움
여러 사용자가 동시에 데이터에 접근하는 경우
데이터 충돌이나 무결성 문제가 발생할 수 있음.
DBMS 특징과 기능
DBMS 특징
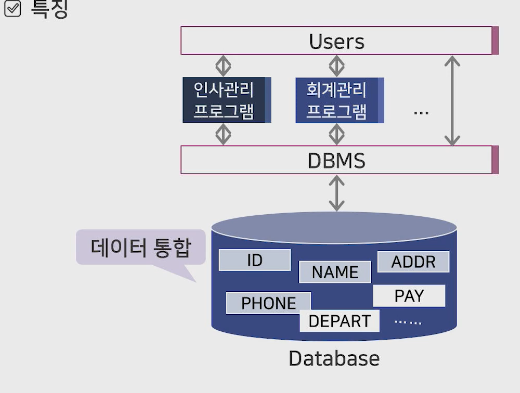
- **DBMS(Database Management System):
사용자와 DB사이에서 DB를 관리하는 소프트웨어
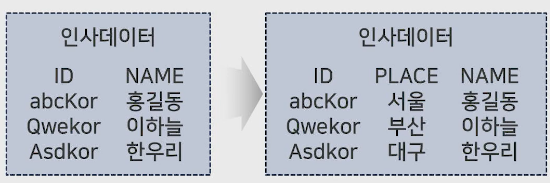
1) 데이터를 통합하여 저장하고 중복성을 최소화함
파일 시스템의 기존 문제점 해결이 가능함(일관성, 보안성, 경제성, 무결성).
2) 독립성을 가짐
데이터베이스 구조 변경 시 응용 프로그램 수정 필요 없음.
3)
4) 테이블 간의 관계
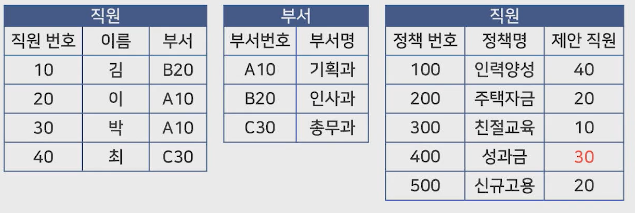
(오른쪽 테이블은 정책테이블로 정정)
직원, 부서 테이블과와 관계를 맺고, 직원, 정책 테이블과 관계를 맺을 수 있음.
관계는 보통 직원 테이블의 PK(직원 번호)를 정책 테이블에 FK로 생성해 맺음.
DBMS 기능
1) 정의 기능
데이터베이스 구조에 대한 정의, 변경, 삭제(CREATE, ALTER, DROP).
데이텉의 형(Type), 제약조건 명시
2) 조작 기능
사용자와 데이터베이스 간의 인터페이스 제공.
데이터 삽입, 삭제, 수정, 검색(INSERT, DELETE, UPDATE, SELECT)
3) 제어 기능
무결성이 유지 되도록 제어(정확한 데이터 유지).
보안유지, 권한 검사(허가된 데이터만 접근).
병행 제어(여러 사용자 접근-> 처리결과의 정확성 유지).
GRANT, REVOKE, COMMIT, ROLLBACK
DBMS 장단점
장점
- 데이터 중복 최소화
- 독립성 확보
- 동시 공유 가능
- 보안 향상
- 무결성 유지
- 표준화
- 장애 발생 시 회복 가능
- 응용 프로그램 개발 비용 절감
단점
- 자체 구축 시 비용 증가
- 백업 및 회복 절차 복잡
- 중앙 집중 관리
DBMS가 필요한 경우 예시
1) 은행 거래
데이터의 일관성과 무결성이 중요함
2) 항공기 예약 시스템
실시간 예약과 취소로 동시 공유와 무결성이 필수임
3) 온라인 쇼핑몰
대량의 데이터 처리 및 동시 접근이 필요함
4) 대규모 기업
여러 부서 간 데이터 공유와 보안이 중요함
5) 연구 데이터 관리
대용량 데이터의 효율적 저장과 분석이 필요함
DBMS가 필요성이 낮은 상황 예
1) 소규모 개인 프로젝트
간단한 데이터 관리에는 복잡한 DBMS가 불필요함
2) 정적 웹사이트
데이터 변경이 거의 없는 경우에는 불필요함
3) 간단한 텍스트 파일 관리
소량 데이터 처리에는 DBMS가 필요 없음
4) 일회성 데이터 처리
데이터 집합이 한 번만 사용되어 DBMS 필요성이 낮음
5) 제한된 사용자 관리
특정 사용자만 접근하는 단순 시스템에는 DBMS 필요성이 낮음
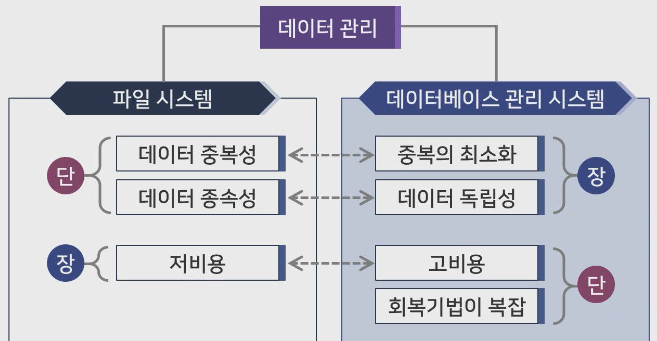
파일 시스템과 DBMS 비교
DBMS 유형과 발전 과정
계층형과 네트워크형
계층형 DBMS(Hierarchical DBMS)
1960년대 후반 IBM의 IMS(Information Management System)에서 처음 도입됨
데이터가 계층 구조로 표현되고 1:N 관계를 지원하며, 부모-자식 관계로 데이터가 구성됨. 각 부모 노드는 여러 자식 노드를 가질 수 있지만, 각 자식 노드는 오직 하나의 부모 노드만 가질 수 있음.
네트워크형 DBMS(Network DBMS)
1970년대에 CODASYL(Conference on Data Systems Languages)모델을 기반으로 발전함. 데이터가 그래프 형태로 표현되고 M:N 관계를 지원하여, 계층형 모델보다 복잡성이 증가함. 오너-멤버(Owner-Member) 관계.
관계형과 객체지향형
관계형DBMS(RDBMS)
1970년 E.F.Codd에 의해 소개됨. 데이터를 테이블(행과 열) 형식으로 저장.
SQL(Structured Query Language)을 사용하여 데이터 조회, 추가, 수정, 삭제 가능. 가장 널리 사용되는 DBMS 유형. 다양한 응용프로그램에서 활용됨. 주요 제품으로 Oracle, MYSQL, MS SQL Server, PostgreSQL 등이 있음
객체 지향 DBMS(OODBMS)
1980~1990년대에 객체 지향 프로그래밍의 인기와 함께 개발됨. 데이터를 객체로 표현하고 객체 지향 프로그래밍의 개념을 기반으로 함. 상속성, 캡슐화, 다형성 등의 객체 지향 개념을 지원함.
- 상속성: 기존 객체의 특성을 상속받아 새로운 객체를 생성할 수 있음.
- 캡슐화: 데이터와 메소드를 하나로 묶어 외부 접근을 제한함(보안).
- 다형성: 동일한 인터페이스를 통해 다양한 객체를 다룰 수 있는 유연성을 제공함.
장점으로는 객체 간 관계를 명확하게 정의 가능함. 데이터의 재사용성과 유지보수성이 높아짐.
NoSQL과 NewSQL
NoSQL DBMS(Not Only SQL)
2000년대 이후에 등장, 관계형 모델의 구조적 제한 없이 대용량의 분산 데이터를 저장할 수 있는 비관계형 데이터베이스. 유연한 데이터 모델을 제공하여, 다양한 형태의 데이터를 효율적으로 처리 가능함. 수평적 확장이 용이하여, 큰 데이터 세트를 처리하는데 적합함.
분류
- 키-값 스토어: 데이터를 키와 값 쌍으로 저장함
- 문서 기반 데이터베이스: JSON, BSON 등의 형식으로 문서를 저장함
- 칼럼 지향 데이터베이스:
데이터를 열 단위로 저장하여, 대규모 분석 작업에 최적화됨 - 그래프 데이터베이스:
데이터와 그 관계를 그래프 형태로 표현하여, 복잡한 관계를 효율적으로 처리함
NewSQL DBMS
NewSQL DBMS는 관계형 DBMS의 SQL 표군 쿼리 기능을 유지하면서도 대규모 분산 환경에서의 확장성을 제공하려는 시도. 기존 관계형 DB의 SQL 쿼리를 그대로 사용할 수 있어, 개발자들이 친숙하게 접근할 수 있음(SQL 지원). 수직확장(서버 성능 향상) 뿐만 아니라 수평 확장(서버 추가)도 가능하여, 대규모 데이터 처리에 적합함(확장성). 데이터의 일관성과 무결성을 보장하는 ACID(Atomicity, Consistency,Isolation, Durability)특성을 유지함.
주요 제품으로는 Google Spanner, CockroachDB가 있음.
앞으로의 발전이 기대가 됨.
