관계 데이터 연산(Information System)
관계형 데이터베이스에서 데이터를 관리하기 위해 사용되는 연산
관계대수
데이터베이스에서 데이터를 처리하기 위한 절차적 언어
-
사용자가 원하는 결과를 얻기 위해 데이터의 처리과정을 순서대로 기술함
-
연산자를 사용하여 데이터를 조작함
-
결과를 얻기 위해 명시적으로 연산의 순서를 지정해야 함
-
SQL과 같은 쿼리 언어의 기초가 됨
관계해석
데이터베이스에서 데이터를 처리하기 위한 비절차적인 언어
사용자가 원하는 결과를 얻기 위해 어떤 데이터를 처리할 것인지에 대한 조건만 기술함
주로 수학적 논리와 관련된 표현을 사용함
관계대수와 관계해석
-
관계대수
절차적 언어.
데이터 처리 과정을 명시적으로 기술 -
관계해석
비절차적 언어.
원하는 데이터의 조건만 기술
관계대수
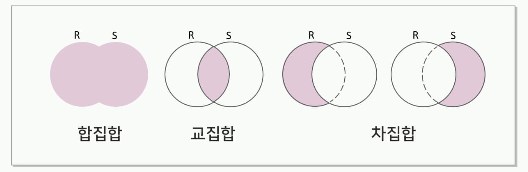
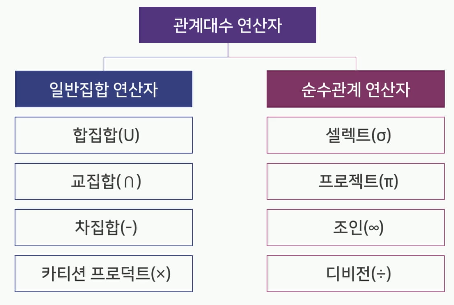
일반집합 연산자
일반 집합 연산자는 항상 두 개의 피연산자를 필요로 함.
즉 두 개의 릴레이션을 대상으로 수행됨
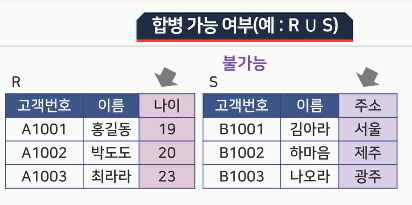
합집합, 교집합, 차집합 연산을 수행하기 위해서는 두 릴레이션이 합병 가능해야 함
-
두 릴레이션의 차수가 동일해야 함
-
두 릴레이션에서 서로 대응되는 속성의 도메인이 같아야 함
- 합병 불가능
- 합병 가능
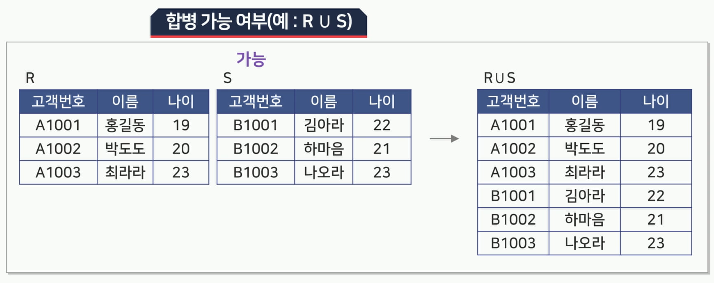
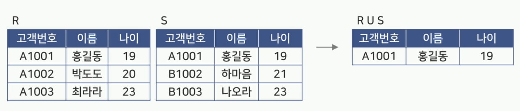
합집합(Union)
두 릴레이션 R과 S의 합집합은R U S로 나타냄
릴레이션 R에 속하거나 릴레이션 S에 속하는 튜플로 구성됨
결과 릴레이션의 특성
-
Degree
릴레이션 R과 S의 Degree와 같음 -
Cardinality
릴레이션 R과 S의 Cardinality를 더한 것과 적거나 같음

교집합(Intersection)
두 릴레이션 R과 S의 교집합을 R∩S로 나타냄
릴레이션 R과 릴레이션 S에 모두 속하는 튜플로 구성됨
결과 릴레이션의 특성
-
Degree
릴레이션 R과 S의 Degree와 같음 -
Cardinality
릴레이션 R과 S의 공통으로 나타나는 튜플의 개수

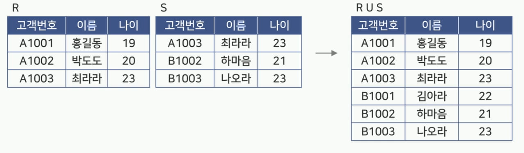
차집합(Difference)
두 릴레이션 R과 S의 차집합은 R-S로 나타냄
R-S는 릴레이션 R에는 존재하고 릴레이션 S에는
존재하지 않는 튜플로 구성됨
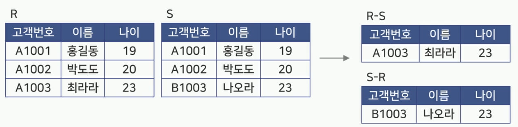
결과 릴레이션의 특성
-
Degree
릴레이션 R과 S의 Degree와 같음 -
R-S의 Cardinality
릴레이션 R의 Cardinality보다 적거나 같음 -
S-R의 Cardinality
릴레이션 S의 Cardinality보다 적거나 같음
카티션 프로덕트(Cartesian Product)
두 릴레이션 R과 S의 Cartesian Product는 R x S로 나타냄
릴레이션 R에 속한 각 튜플과 릴레이션 S에 속한
각 튜플을 모두 연결하여 만들어진 튜플로 구성됨
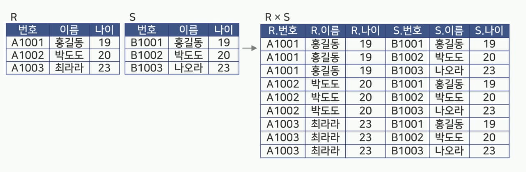
결과 릴레이션의 특성
-
Degree
릴레이션 R과 S의 Degree를 더한 것과 같음 -
Cardinality
릴레이션 R과 S의 Cardinality 를 곱한 것과 같음
순수관계 연산자
- 예제1
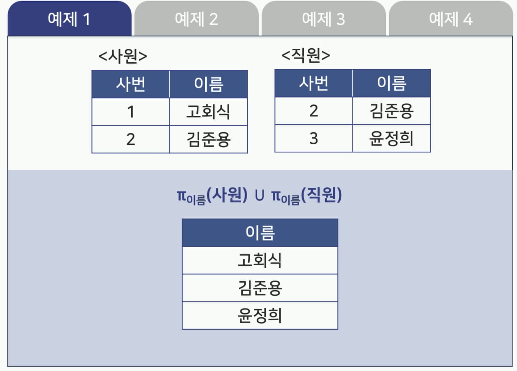
- 예제2
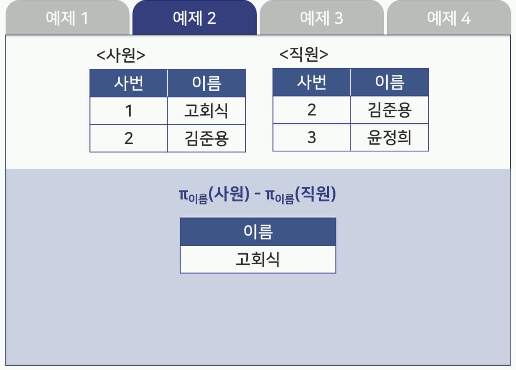
- 예제3
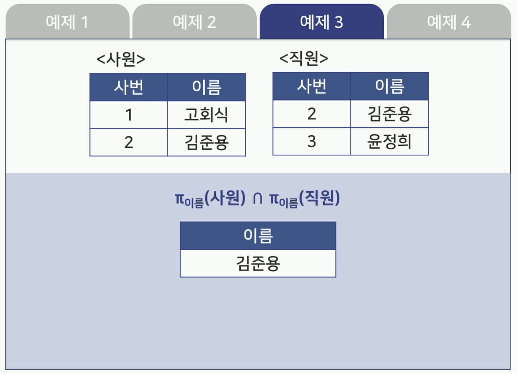
- 예제4
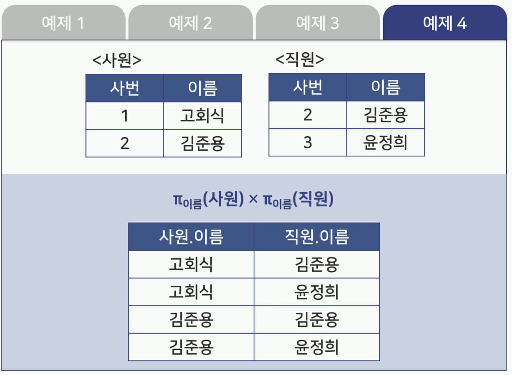
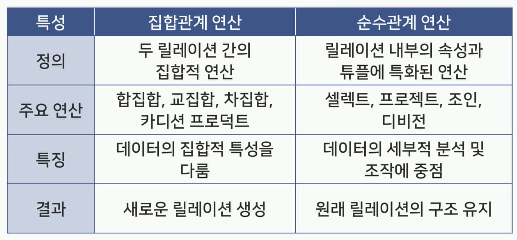
집합관계 연산과 순수관계 연산의 비교
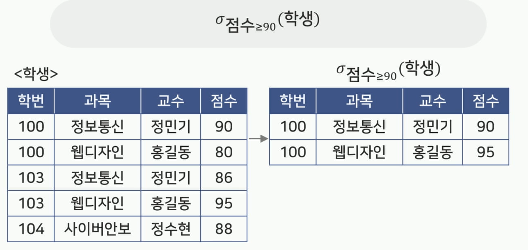
셀렉트(Select)
릴레이션에서 조건에 만족하는 튜플을 검색함

비교 연산자(>, ≥, <, ≤, =, ≠)와 논리 연산자 (^, V, _)를 이용해 작성

- 예) 학생 릴레이션에서 점수가 90 이상인 튜플을 검색하시오.
-
예) 고객 릴레이션에서 등급이 gold인 튜플을 검색하시오.

-
예) 성적 릴레이션에서 Avg가 90 이상인 튜플을 검색하시오.
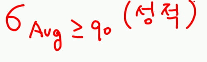
-
예) 고객 릴레이션에서 등급이 gold 이고, 적립금이 2000 이상인 튜플을 검색하시오.

프로젝트(Project, π )
릴레이션에서 주어진 속성들의 값으로만 구성된 열을 선택함

-
예) 학생 릴레이션에서(과목과 점수)를 검색하시오.
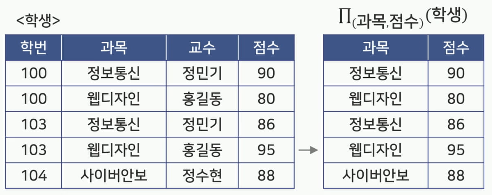
-
예) 학생 릴레이션에서 (학번)을 검색하시오.

-
예) 학생 릴레이션에서(학번, 과목, 점수)를 검색하시오.

-
예) 학생 릴레이션에서 교수가 '정민기'인(학번, 과목, 점수)를 검색하시오.

-
예) 성적 릴레이션에서 Name과 Avg 속성을 검색하시오.
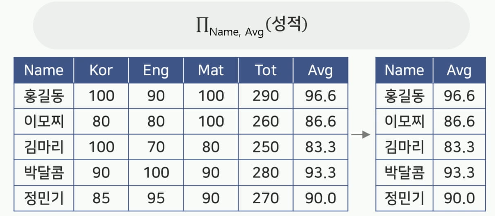
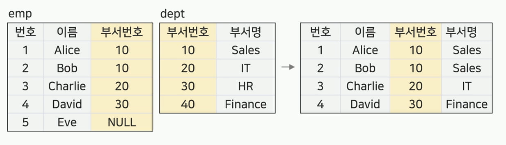
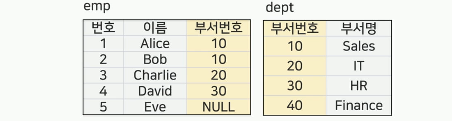
조인(Join, ∞)
공통 속성을 이용하여 2개 이상의 릴레이션을 연결하여
새로운 릴레이션을 생성
릴레이션1∞(조건) 릴레이션 2
동등조인(Equi-join)
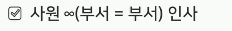
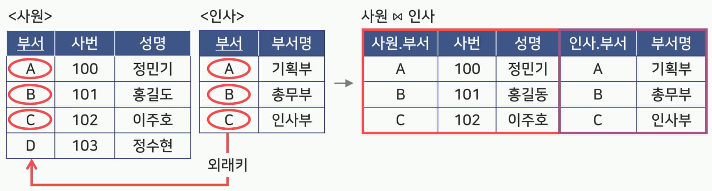
결합 결과의 행에 따른 분류
내부 조인(Inner Join)
두 테이블이 모두 조인 조건을 만족하는 행만 반환
외부 조인(Outer Join)
조인 조건을 만족하지 않는 행도 포함

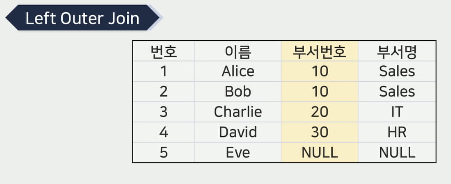
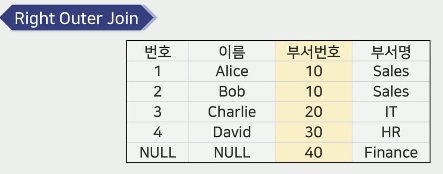
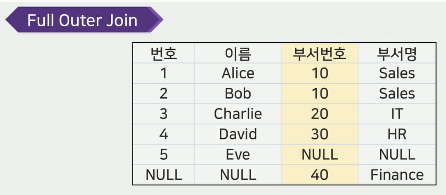
조인 조건의 유형에 따른 분류
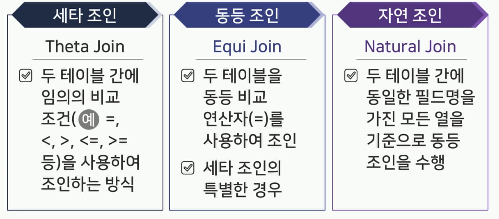
-
세타 조인(Theta Join)

-
동등 조인(Equi Join)
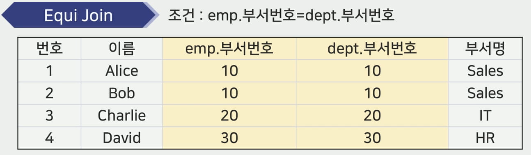
- 자연 조인(Natural Join)
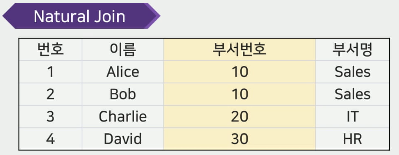
-
예시
N: 자연 조인(Natural Join)을 나타냄
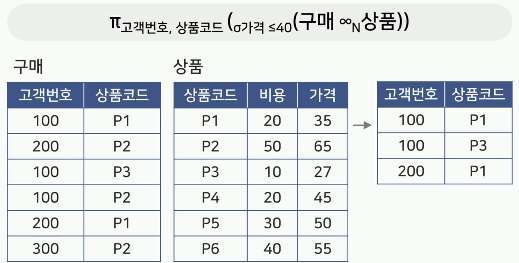
-
예시
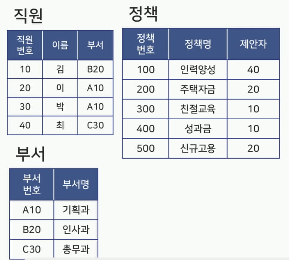

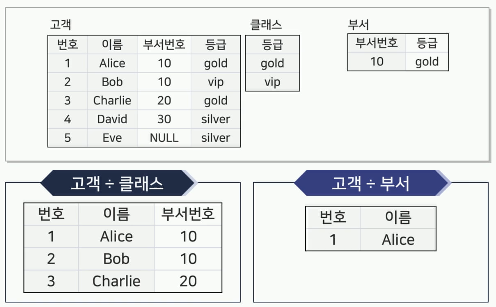
디비전(Division, ÷)
A 릴레이션 ÷ B 릴레이션
B 릴레이션의 모든 조건을 만족하는 튜플을 A 릴레이션에서 구하는 연산
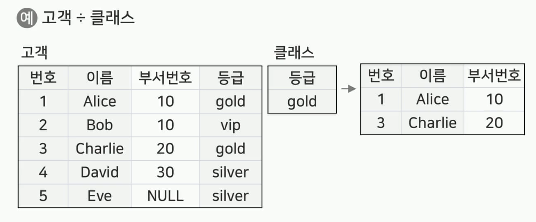
- 예시