머신러닝 모델을 생성할 때 train data, test data, validation data 분리하는 이유 이해하기
처음 머신러닝을 공부하다보면 train data와 test data를 왜 분리 해서 활용해야하는지 이해하기 어려울 때가 많다. 또는 train data와 test data의 개념은 이해했지만 도대체 validation data와 test data는 무슨 차이인지 잘 이해가 안되는 경우도 있다. 먼저 머신러닝 이란 무엇이기에 train data와 test data, validation data가 필요한지 알아보자.
머신러닝
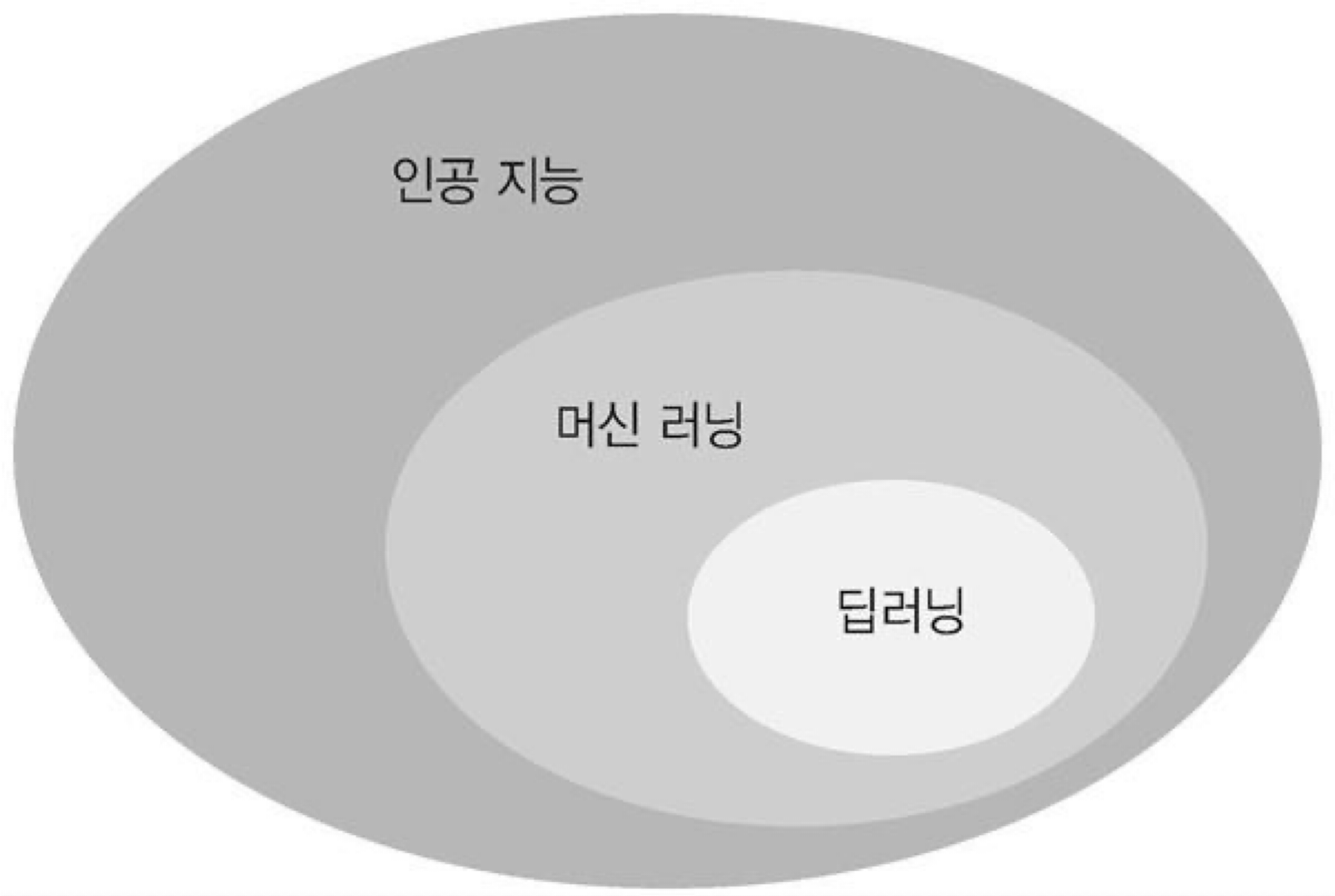
머신러닝은 인공지능의 하위 연구분야로 딥러닝과 함께 많이 활용되고 있다. 초기의 인공지능은 현재의 프로그래밍과 크게 다를 것 없었는데, 복잡한 문제를 풀기 위해 데이터를 활용한 머신러닝 알고리즘이 등장했다.
머신러닝은 "Machine Learning" 영문 표현 그대로 기계가 배우는 것을 의미한다. 이때 기계는 바로 "데이터"를 통해 배운다.

결국 머신러닝은 데이터를 통해서 규칙을 찾아내는 알고리즘으로 규칙을 찾기 위해 많은 데이터들이 필요하고 머신 러닝 모델이 이해하고 있는 규칙을 바탕으로 미래를 예측한다고 이해하면 된다.
그럼 본격적으로 데이터 셋은 왜필요한지 알아보자.
Dataset
데이터 셋은 크게 train data, test data, validation data 총 3개로 구분 된다. 먼저 train data는 머신러닝 모델이 학습을 하기 위해 필요한 데이터다. 그럼 왜 test data와 validation data가 필요한 걸까?
test data
test data는 train data를 바탕으로 만들어진 모델이 제 성능을 가지고 있는지 "test"하는데 활용 된다. 강의를 할 때 많으 드는 예인데,
기출문제를 100번 푼 사람이 실제 수능을 치러 갔을 때 점수를 잘 맞출까? 아마 기출문제에서 문제가 나오거나 비슷한 문제가 나온다면 높은 점수를 받을 가능성이 높고 아니라면 좋은 점수를 받기 어렵다.
반대로 기출문제 50개, 다양한 상황이 고려된 문제 50개를 푼 사람이 수능을 치러 간다면 어떨까? 이전에 예를 들었던 기출문제를 풀었던 사람과는 다르게 아마도 수능에서 좋은 점수를 받을 가능성이 조금 더 높아 보인다.
이 처럼 데이터에 따라서 머신러닝 모델은 새로운 데이터에 대해서 잘 적용 되는지 "test"하기 위해 test data를 활용한다고 이해하면 된다.
validation data
validation data는 구분하기도 하고 구분하지 않기도 하는데, sklearn으로 모델을 만드는 경우에는 보통 사용하지 않는 경우를 많이 봤고, tensorflow나 pytorch를 활용해서 딥러닝 모델을 만드는 경우에는 validation data를 활용하는 경우도 많이 봤다.
validation data 같은 경우에는 test data는 모델을 테스트 하기 위함이라면 validation data는 머신러닝 모델을 만들어 줄 때 파라미터를 많이 수정하는데 모델을 수정하는데 활용한다고 생각하면 된다.
Sklearn
Code Process
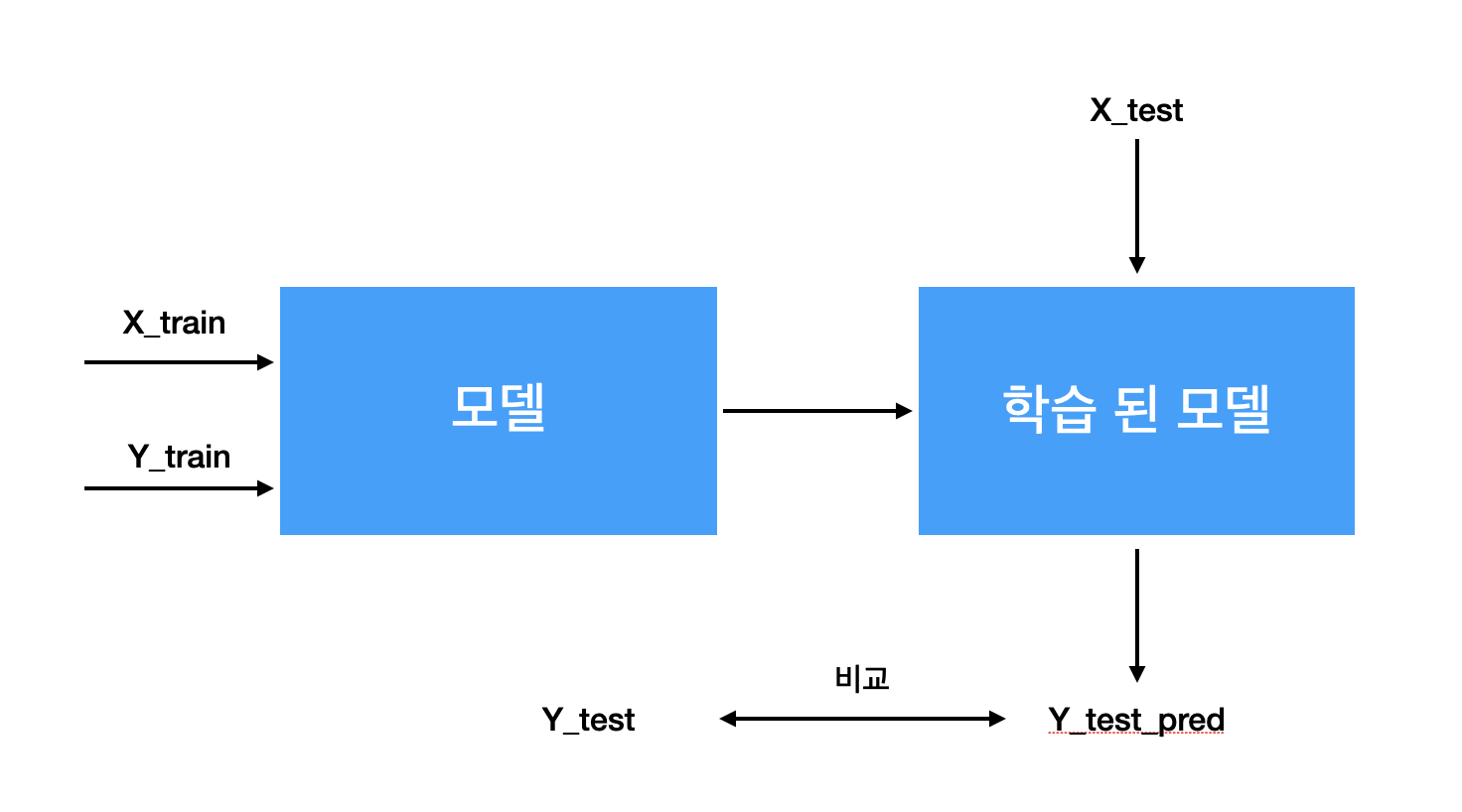
sklearn으로 머신러닝 모델을 만들 때에는 아래의 프로세스를 가진다.
1. train test data 분리
2. 머신러닝 모델에 data fit
3. test data를 활용한 model 검증
4. 모델의 정확도 or 오차 계산
1. train test data 분리
X_train, X_test, y_train, y_test = train_test_split(
... X, y, test_size=0.30)train data와 test data를 분리할 때에는 sklearn의 train_test_split 함수를 많이 활용하며 test_size에 따라 test data의 비율을 지정해 줄 수 있다.
test_size는 보통 0.2~0.3 정도로 초기값을 주는게 좋으며 데이터가 많고 적음에 따라 test_size를 어떻게 지정하는게 좋을지 한번 고민해보자.
2. 머신러닝 모델에 data fit
# LinearRegression 모델 기준
model = LinearRegression()
model.fit(X_train, y_train)위에서 train data는 model을 학습하는데 활용 된다고 했다. 그래서 모델에 데이터를 "fit" 해준다는 의미는 학습해준다는 의미로 이해하면 된다.
3. test data를 활용한 model 검증
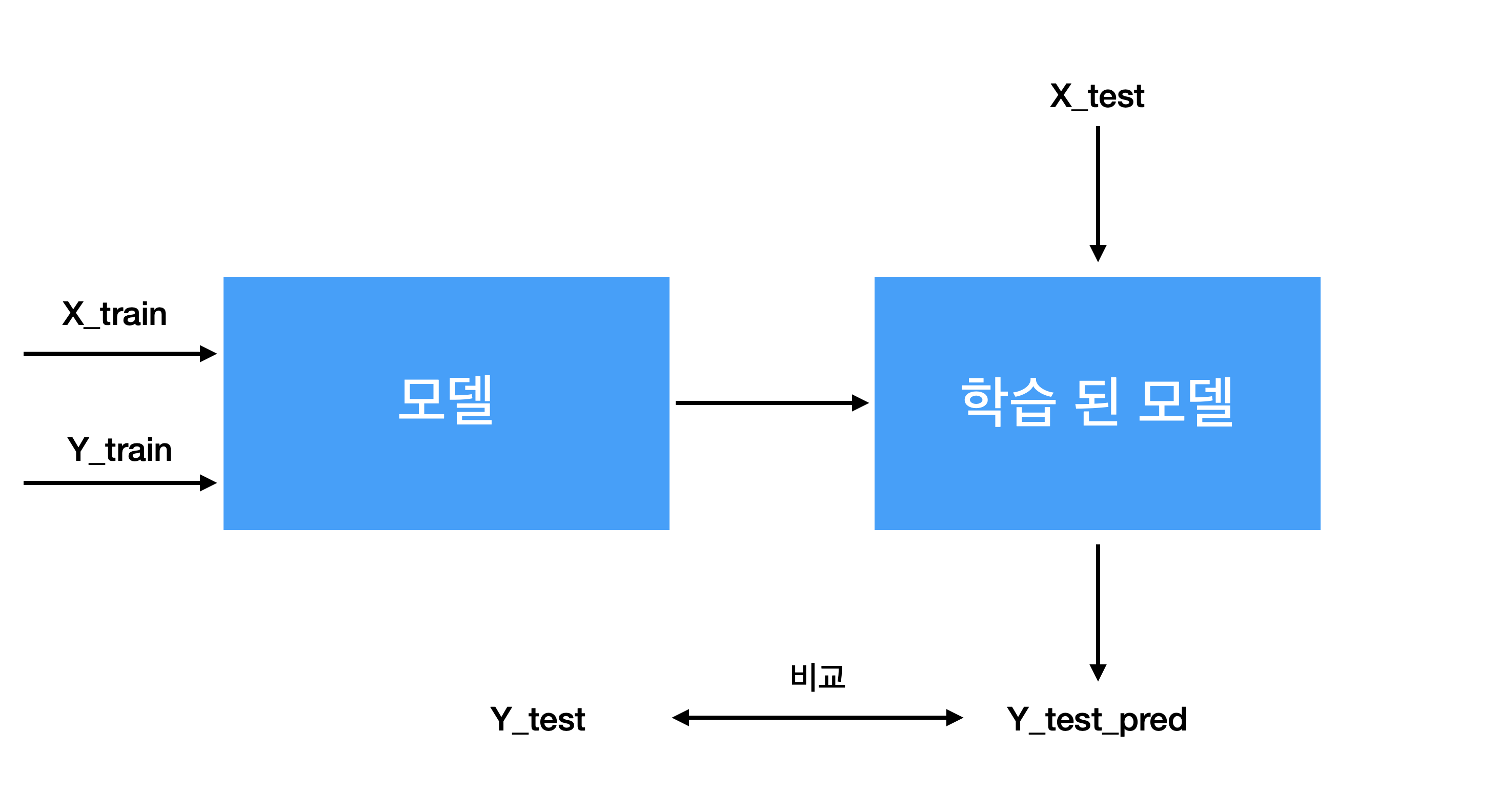
y_test_pred = model.predict(X_test)모델에 X_test를 넣어 나온 "y_test_pred"와 실제 "y_test"를 비교해보면 어느정도의 성능을 가지는지 예상해 볼 수 있다.
4. 모델의 정확도 or 오차 계산
model.score(X_test, y_test)
model.score(X_train, y_train)train data와 test data의 score(accuracy)를 비교하여 overfitting 여부를 확인한다.
요약
위의 프로세스를 간단한 그림으로 표현하면 아래와 같다.