[CG/개념] Introduction to Computer Graphics with OpenGL ES CH03: Modeling
Intro to Computer Graphics
이 시리즈에서는 고려대학교 한정현 교수님의 Computer Graphics 강의에서 공부한 내용을 정리해보고자 한다. 강의는 교수님의 저서 Introduction to Computer Graphics with OpenGL ES 를 바탕으로 진행되었다.
CH03: Modeling
Polygon Mesh
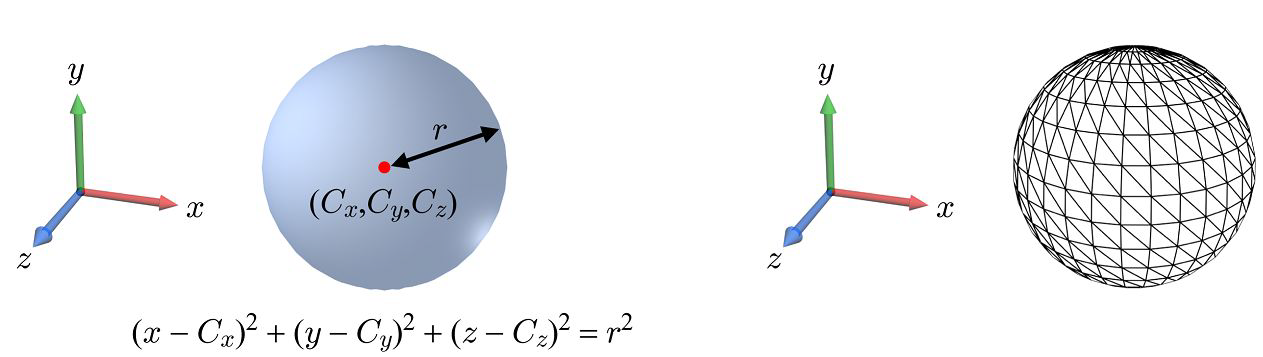
3차원 공간의 object를 표현할 때, 수학적으로 우리에게 익숙한 표현 방식은 implicit representation이다. 예를 들어, 구를 표현한다고 할 때, 중심 좌표가 이고 반지름이 인 구는
처럼 표현할 수 있고, 이것이 우리에게 가장 익숙한 표현 방식이다. 그러나 우리의 GPU는 이러한 implicit representation에 최적화되어있지 않다. 음함수 표현법은 특정 위치에서 값을 계산하기 위한 연산량이 많을 뿐더러, GPU가 병렬로 나누어 처리하기가 쉽지 않기 때문이다. 따라서 그래픽스에서 object를 표현할 때에는 이러한 음함수를 사용하기보다 표면의 sampled points를 활용한 Polygon Mesh를 활용한다.
이 Polygon Mesh는 보통 삼각형 또는 사각형 면으로 이루어지게 되고, 전형적인 closed mesh의 경우 vertex의 개수의 약 두배의 삼각형 면이 만들어지게 된다.
그럼 사각형 면은 언제 사용할까?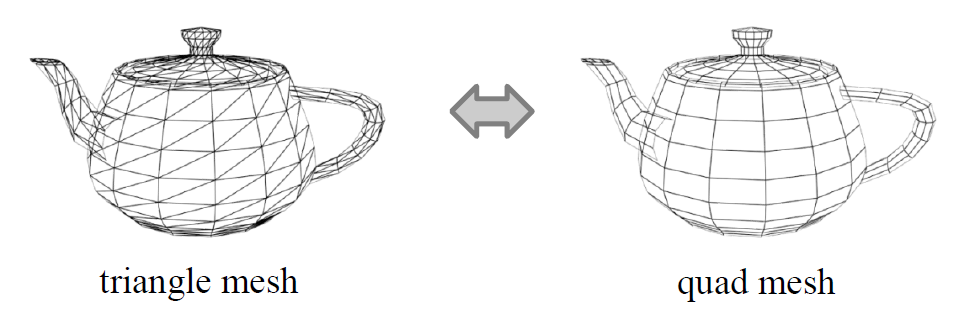
위의 사진과 같이, GPU 연산은 triangle mesh에 최적화되어 있지만 실제 CG 작업 파이프라인에서는 quad mesh가 선호된다. 그 이유는 작업의 편리성과 clean mesh 생성이 가장 큰 이유이다.
quad mesh를 활용할 때 모델링 작업에서 더 topologically clean한 mesh를 생성할 수 있다. 따라서 애니메이션과 리깅 과정에서 모델의 변형을 더 매끄럽게 표현이 가능하다.
또한 모델링 과정에서 면을 쪼개거나(subdivision), edge loop나 ring을 만드는 등의 과정이 더 쉽고 정확하며, UV mapping 과정에서 왜곡이 감소한다.
다만, GPU 연산이 처리될 때에는 quad mesh도 triangle mesh로 변환되어 연산된다고 한다.
그래픽 작업에서 직접적으로 triangle mesh를 활용하는 경우는:
- real-time graphics
- 불규칙한 표면(ex. terrain) 표현
정도가 있을 수 있겠다.
Level of Detail(LOD)
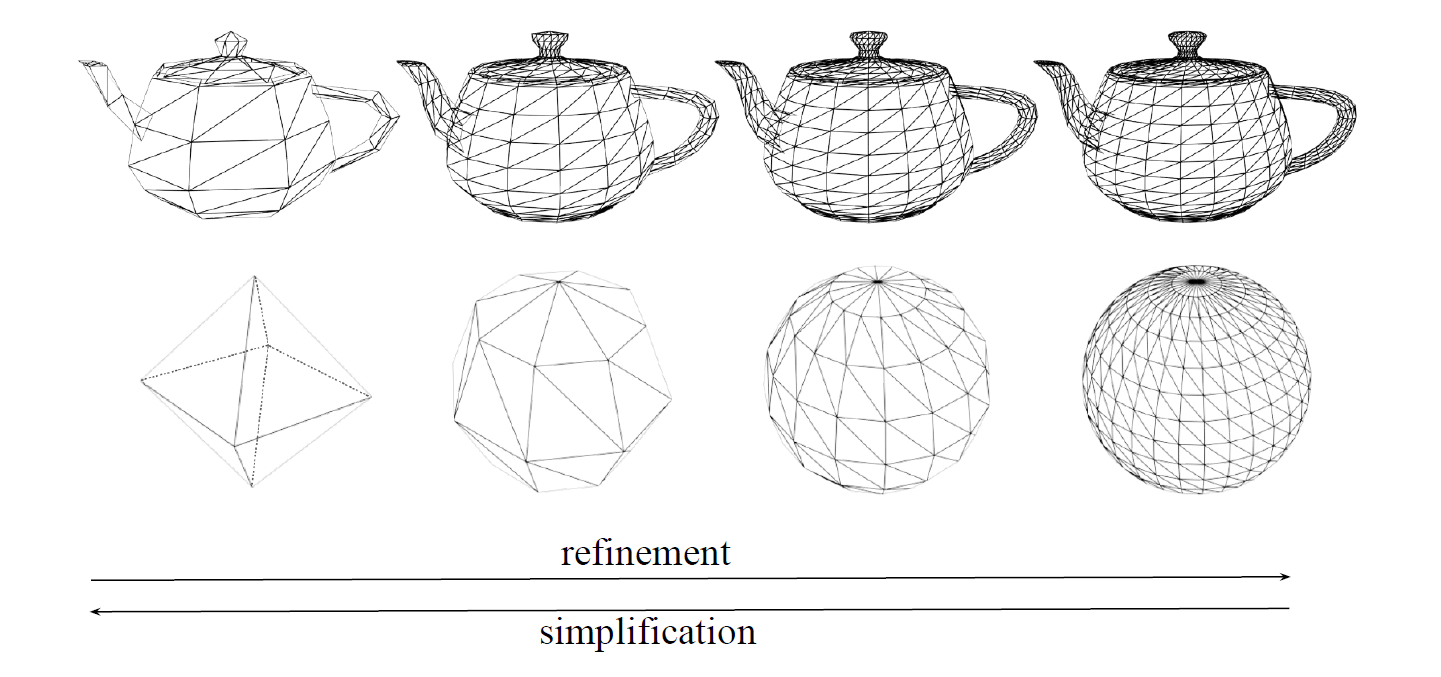
LOD는 polygon mesh가 정점 몇개로 표현되는지 그 정도를 나타낸다.
여기서 accuracy 와 efficiency 사이의 트레이드오프가 발생한다. LOD가 높을수록 더 정확한 surface 표현이 가능해지지만 동시에 연산 효율성은 낮아지고, LOD가 낮을수록 surface 표현은 부족해지지만 연산은 더 효율적으로 처리된다.
Array Representation
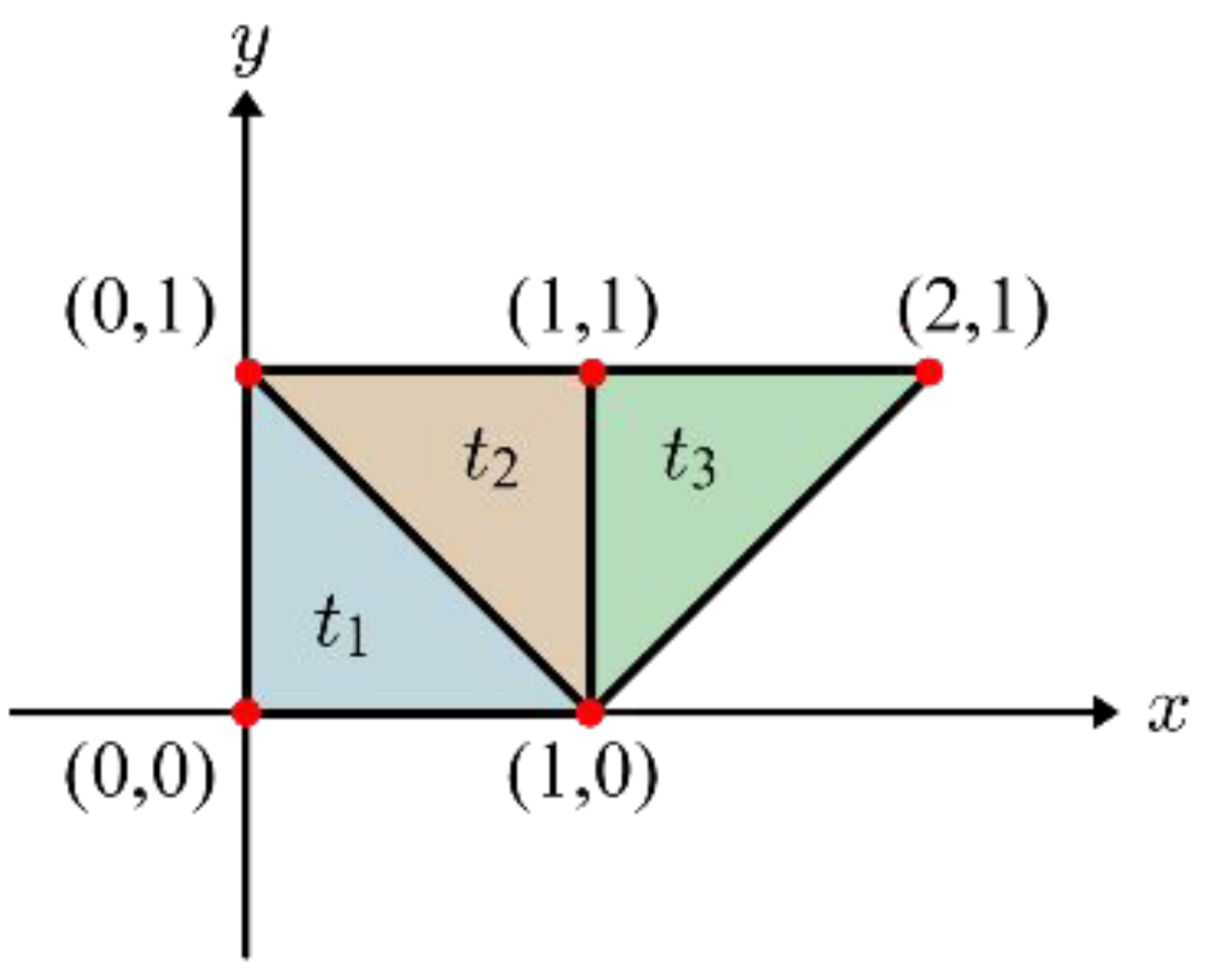
다음과 같은 mesh를 보자. 삼각형 면 로 이루어져 있는 이 mesh의 정점을 memory space에 array의 형태로 정리한다면 어떤 방식이 좋을까?
여기서 중요한 지점은 세 면들이 서로 만날 때, 두 개의 정점을 공유하게 된다는 사실이다. 즉, 단순히 각 면에 대응하는 세 개의 정점을 각각 나열하는 방식을 취한다면 중복이 발생하게 되고, 이는 효율성이 낮으므로 좋지 않은 표현이 된다.
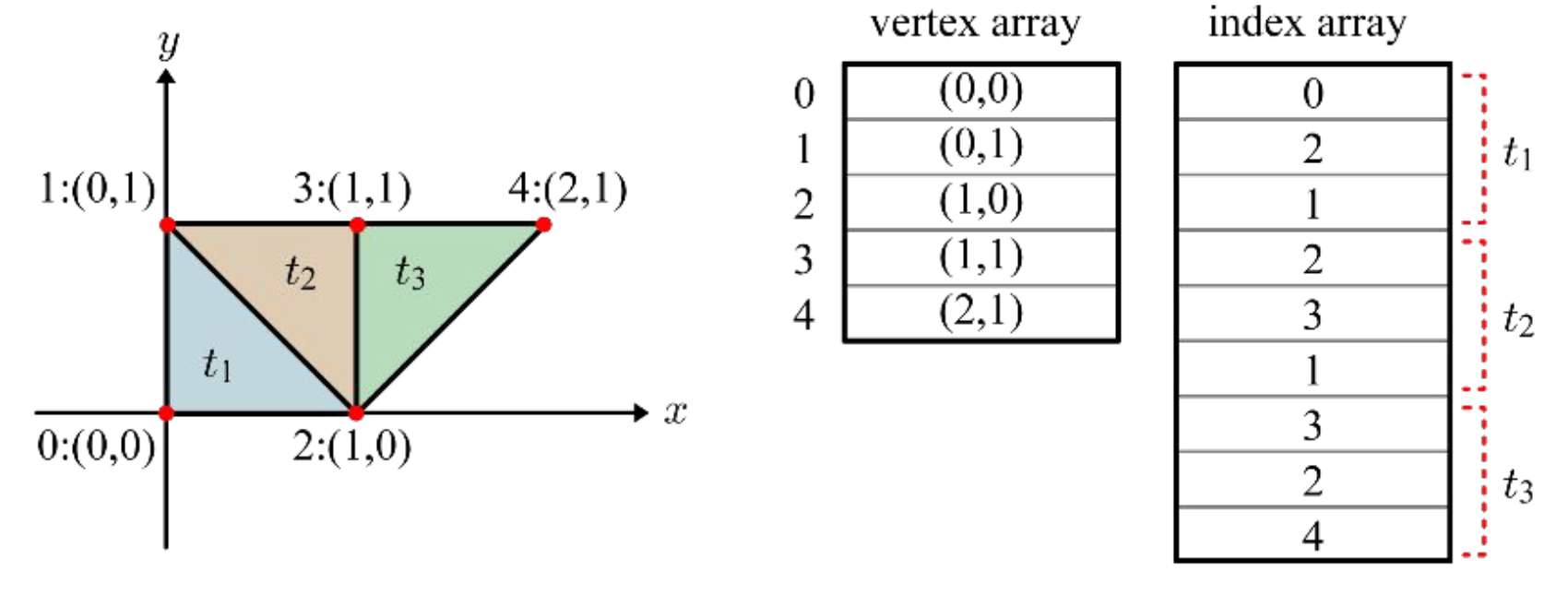
하지만 다음과 같이 array를 vertex array와 각 vertex의 index를 면에 따라 나열한 index array로 나누어 memory space에 두 가지 array를 저장한다면 효율성 문제를 개선할 수 있다. 먼저 vertex array에는 mesh를 구성하는 모든 정점을 중복 없이 나열하고, 인덱스를 붙인다. 그리고 index array에는 각 면을 구성하는 vertex의 index를 시계 반대방향으로 저장한다.
메모리를 크게 차지하는 vertex array의 value들 대신 index만 중복이 일어나므로 메모리 공간을 효율적으로 사용할 수 있다. 이 때 array를 두 개 사용해야 함에도 이 방식이 효율적인 이유는, vertex array의 각 cell이 위치 좌표 뿐 아니라 각 정점의 attribute를 포함하기 때문에 메모리에서 차지하는 공간이 크기 때문이다.
그런데 왜 index array에 vertex index를 저장할 때 시계 반대방향으로 저장해야 할까? 그 이유는 normal과 관련이 있다.
Normals
Surface(Triangle) Normals
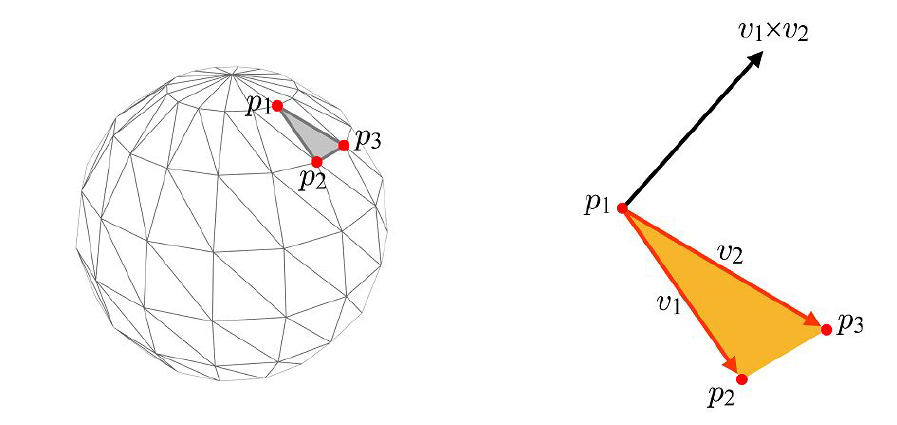
Surface Normal은 보편적인 노멀 벡터를 말한다. 3차원 그래픽스에서 노멀은 polygon mesh를 구성하는 면의 방향성을 알려주기 때문에 중요하다.
노멀을 구할 때에는 외적을 사용한다. 평행하지 않은 어떤 벡터 가 있을 때 그 외적 의 방향은 모두에 수직이고, 따라서 가 이루는 평면에도 수직임을 알 수 있다. 노멀은 항상 크기가 1인 unit vector로 나타내므로,
로 표현될 수 있다.
여기서 중요한 지점은, 노멀이 벡터이기 때문에 방향이 있다는 점이다. 즉 의 순서에 따라 노멀이 "뒤집힐"수 있다는 것이다.

그래픽스 소프트웨어에서 면의 노멀이 뒤집히면, 이미지의 검은 면처럼 비정상적으로 면이 표현되고, lighting 이나 texturing이 제대로 처리되지 않는다. (그림은 Maya)
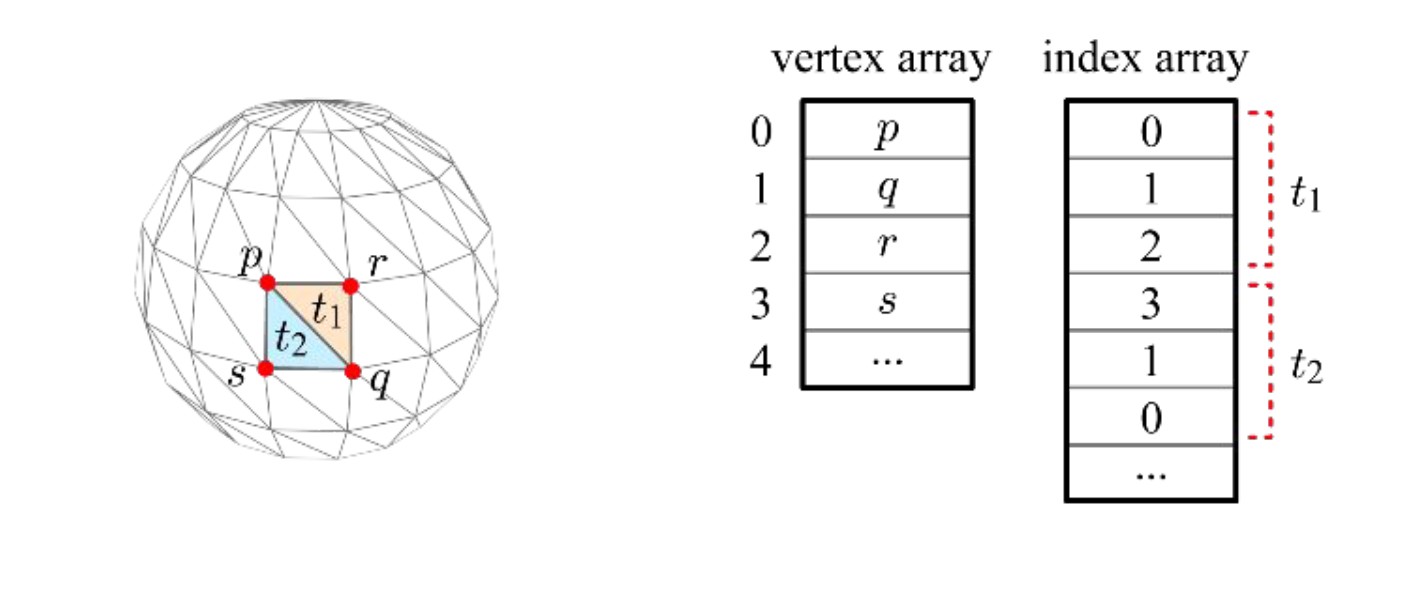
그렇기에 vertex index를 저장할 때에 index를 시계 반대방향으로 저장하여 항상 노멀이 올바른 방향을 향하도록 해야한다. 이 때 이 시계 반대방향의 순서를 counter-clockwise를 줄여 CCW 순서라고 이야기한다.
노멀벡터 방향 찾기 노멀벡터의 방향은 외적의 방향을 찾는 오른손 법칙으로 쉽게 찾을 수 있다.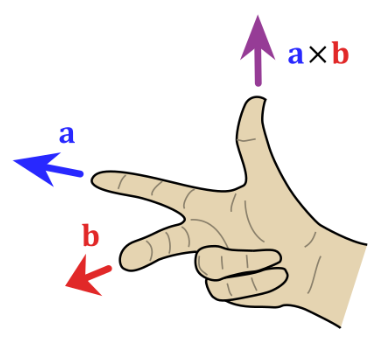
Vertex Normals
그런데 사실 실제 3D 그래픽스 소프트웨어에서, 항상 이렇게 surface normal을 연산하여 사용하는 것은 무리가 있다. mesh의 세부 구조에 따라 매번 계산하여 surface normal을 실시간으로 처리하는 데에 계산 비용이 많이 들기 때문이다.
대신 Vertex Normal을 활용하여 계산 효율성과 퀄리티를 동시에 적절히 확보하는 방식이 사용된다.
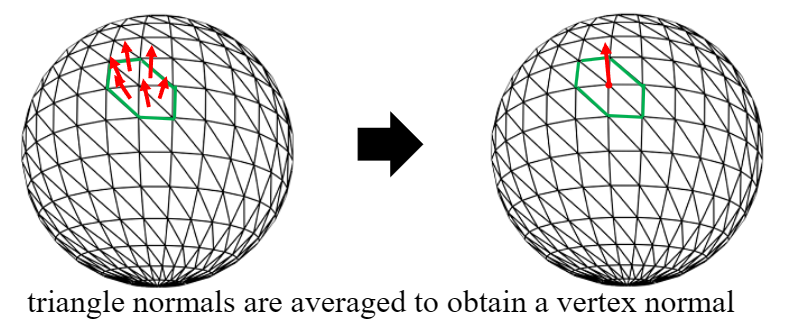
Vertex Normal은 각 정점에서의 법선을 말한다. 정점에서 어떻게 법선이 있지? 라고 생각할 수 있지만, 이는 인접한 면들의 법선을 샘플링하여 평균을 내 계산된다.
.obj
3D 그래픽스 작업중에는 소프트웨어간 모델 import/export를 해야하는 상황이 많다. 주로 .obj의 포맷으로 모델을 저장하게 되는데, 앞서 다루었던 vertex array, index array, 그리고 vertex normal의 데이터가 obj 형식으로 export되고 다시 소프트웨어에서 import되어 읽어올 때 인식되면서 모델을 재구성하게 된다.
.obj 파일은 그럼 어떻게 생겼을까?

obj의 구조를 살펴보면, 크게 v, vn, g, f로 시작하는 부분을 확인할 수 있다. 하나씩 살펴보면 다음과 같은 정보를 포함한다:
- v: vertex. 정점의 위치정보
- vn: vertex normal. 정점의 노멀벡터
- f: face. 각 면을 이루는 정점의 index//vertex normal의 index 세개로 이루어짐.
- g: group. 위의 데이터들로 이루어진 객체(그룹)의 이름
이 정보는 다시 import될 때 position과 normal로 이루어진 vertex array와 index array로 이루어진 데이터로 읽어오게 된다. vertex array의 각 index의 정보는 하나의 cell을 이루고, 다시 소프트웨어에서 texture 등의 attribute가 cell에 추가되기도 한다.

