🥸 파이썬을 잘 모르는 파린이임.
일단 뭐가 됐든 프레임워크를 쓰는게 나을 것 같아서 찾아봤다.
: Django, Flask, FastAPI 등이 있음
FastAPI
비동기 작업을 쉽게 처리할 수 있어 실시간으로 데이터를 주고받는 AI 채팅에 적합
okay.. 너로 정했다.
프로젝트 구조
my_project/
│
├── app/
│ ├── __init__.py
│ ├── main.py # FastAPI 애플리케이션 시작점
│ ├── models.py # Pydantic 모델
│ ├── services.py # OpenAI API 통신 및 세션 관리
│ ├── endpoints/ # 각 엔드포인트별 파일
│ │ ├── chat.py # /chat, /chat/stream 등
│ │ ├── session.py # /new-session, /session/{session_id} 등
│ ├── utils.py # 유틸리티 함수 (예: 세션 정리)
│
├── .env # 환경 변수 파일 (OpenAI API 키 등)
├── requirements.txt # 프로젝트 의존성
└── README.md근데 FastAPI 프레임워크는 직접 다 파일 만들어야 하는거 실화인가?
각 파일 설명
__init__.py
app 폴더를 패키지로 인식하게 만들어줌.빈 파일로 둬도 된다.
main.py
FastAPI 애플리케이션을 실행하는 파일
models.py
Pydantic 모델을 정의하는 파일
services.py
OpenAI API 호출과 세션 관리를 처리하는 서비스 로직 파일
endpoints/chat.py
/chat 엔드포인트를 처리하는 파일
endpoints/session.py
/session 관련 엔드포인트를 처리하는 파일
requirements.txt
FastAPI와 Uvicorn을 포함한 서버 실행에 필요한 패키지와 OpenAI API 통신 및 환경 변수 관리에 필요한 패키지를 포함
패키지 설치
제일 먼저 requirements.txt 파일을 생성함
파일 내에 아래와 같이 적었다
fastapi
uvicorn
openai
pydantic
python-dotenv그리고 인스톨
pip install -r requirements.txt파일 직접 생성해주기.
session.py
새로운 세션 열기
@router.post("/new-session", response_model=NewSessionResponse)
async def new_session():
"""새로운 대화 세션 시작"""
session_id = get_or_create_session(None)
return NewSessionResponse(
session_id=session_id,
message="새로운 대화가 시작되었습니다."
)세션 닫기
@router.delete("/{session_id}")
async def delete_session(session_id: str):
"""특정 세션 삭제"""
if session_id in conversation_store:
del conversation_store[session_id]
return {"message": "세션이 삭제되었습니다."}
else:
raise HTTPException(status_code=404, detail="세션을 찾을 수 없습니다.")chat.py
@router.post("/", response_model=ChatResponse)
async def chat_endpoint(request: ChatRequest):
try:
# 세션 가져오기 또는 생성
session_id = get_or_create_session(request.session_id)
# 사용자 메시지를 대화 히스토리에 추가
conversation_store[session_id]['messages'].append({
"role": "user",
"content": request.message
})
conversation_store[session_id]['messages'][0]["content"] = request.system_message
# OpenAI API 호출
response = openai.ChatCompletion.create(
model=MODEL,
messages=conversation_store[session_id]['messages']
)
assistant_response = response['choices'][0]['message']['content']
# 어시스턴트 응답을 대화 히스토리에 추가
conversation_store[session_id]['messages'].append({
"role": "assistant",
"content": assistant_response
})
# 대화 히스토리가 너무 길어지면 최근 대화만 유지 (시스템 메시지 + 최근 20턴)
if len(conversation_store[session_id]['messages']) > 41:
system_msg = conversation_store[session_id]['messages'][0]
recent_messages = conversation_store[session_id]['messages'][-40:]
conversation_store[session_id]['messages'] = [system_msg] + recent_messages
return ChatResponse(response=assistant_response, session_id=session_id)
except Exception as e:
raise HTTPException(status_code=500, detail=str(e))LLM은 gpt-4o-mini 사용
MODEL = "gpt-4o-mini"
파일 내용은 일부만 적었음. 더 자세한건 chatgpt에게,,,,
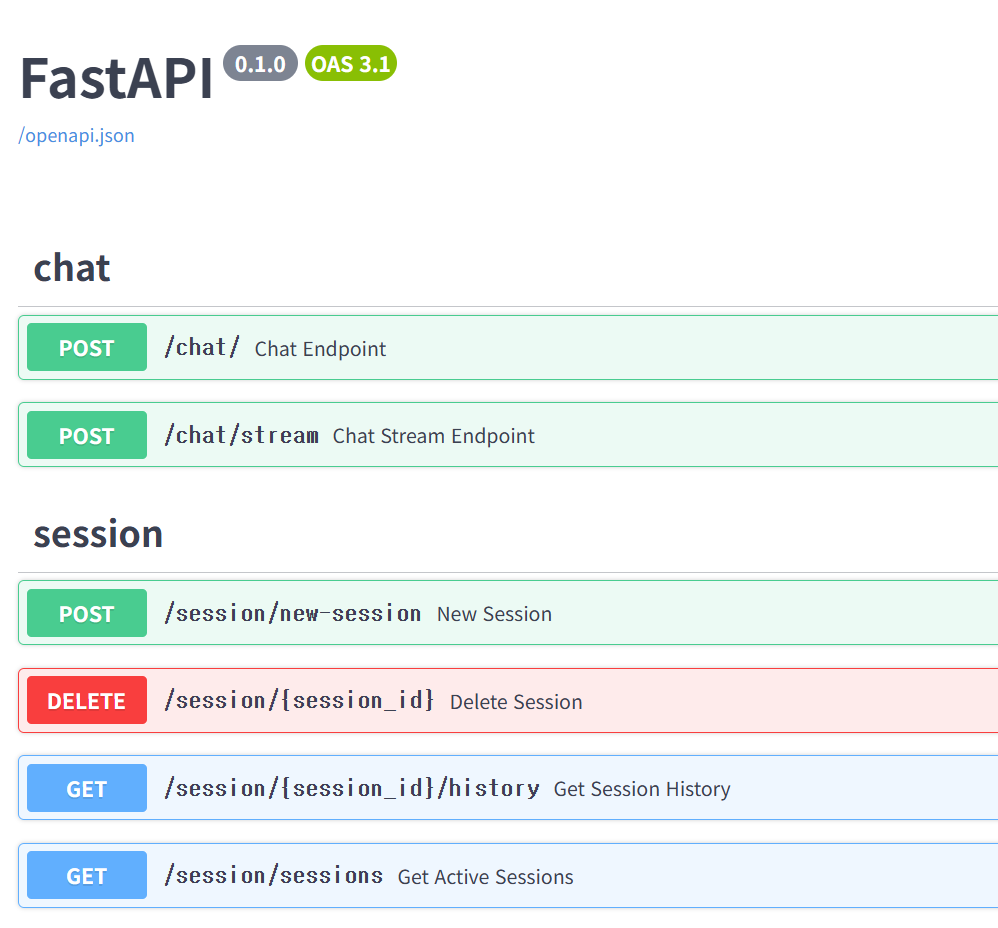
서버 띄움. 기본 포트는 8000번으로 뜸.
http://127.0.0.1:8000/docs로 들어가면 위와 같이 스웨거를 확인 가능하다.
서버 실행 cmd
uvicorn app.main:app --reload
kill 할때는 pID로 킬해야한다.
