
Atchapedia #5 - MovieDetailView & Refactoring
평균별점
한 영화에 대해 전체 user가 내린 rating의 평균값을 구해야 한다.
해당 영화에 대한 전체 rating과 user를 구한 후 나누면 되므로, 아래와 같이 구현했다.
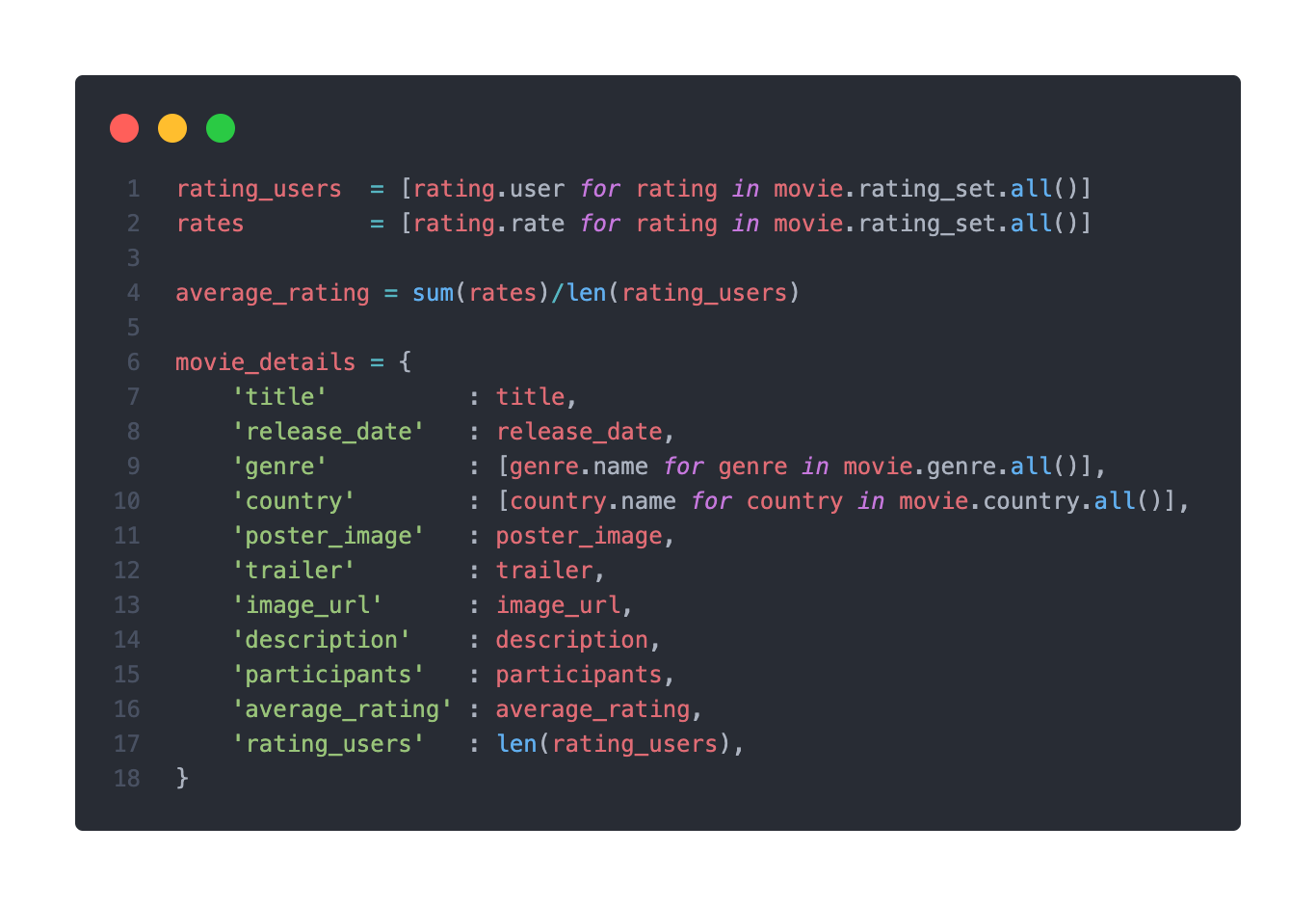
기존에 이용했던 _set 매니저를 통해 영화에 역참조 관계에 있는 rating table에 접근하여 user와 rate을 빼온 후 나눠주었다.
전체 코드
내가 구상했던 영화 상세 페이지에 대한 전체 코드는 아래와 같다.
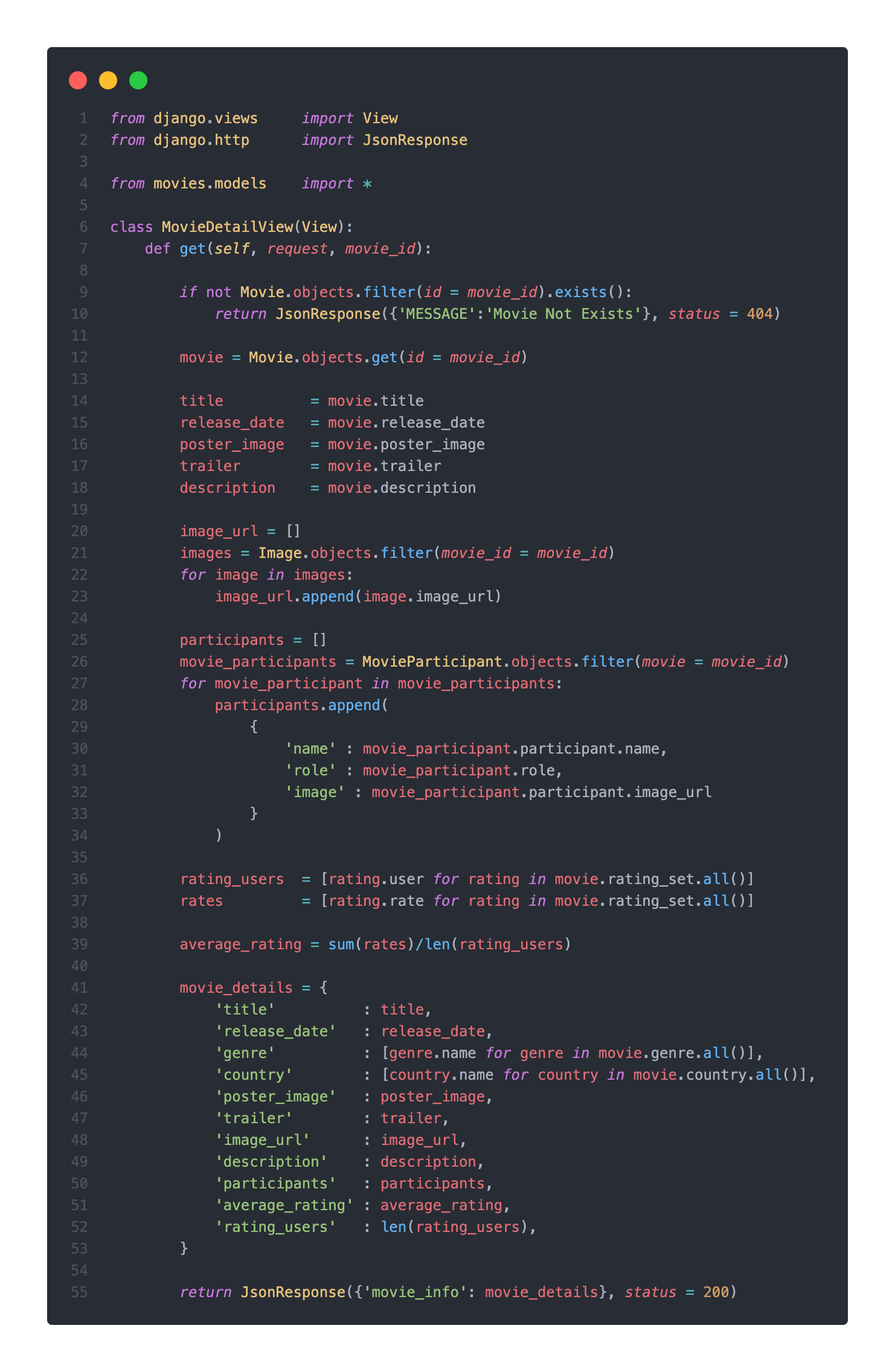
movies 테이블에서 바로 빼올 수 있는 정보들을 제외하고, 역참조 관게에 있는 image, participants, average_rating을 _set 매니저를 통해 구현하였다.
Refactoring
처음 전체코드를 보고나서 느낀점은 "생각보다 길다..?" 였다.
아직 코드를 쭉 훑으면서 바로바로 이해할 수 있는 단계가 아니다 보니, 일단 변수를 지정하여 정보를 담은 뒤, 후에 해당 변수를 다시 json에 담아 출력시키다보니 길다는 판단이 들어 하나하나 수정해나가기 시작했다.
1. 불필요한 변수 제거
가장 처음 바꾸고자 한건, 불필요한 변수를 제거하는 일이었다.
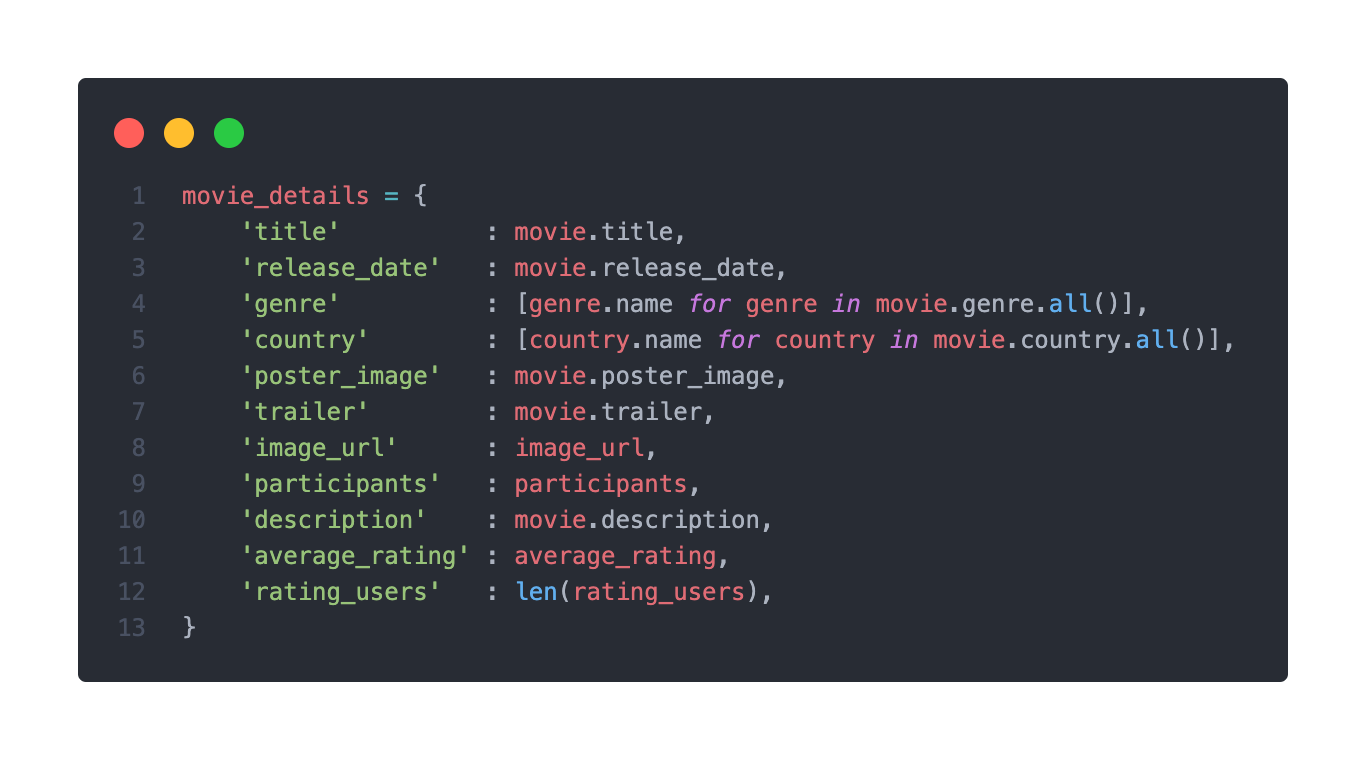
movies 테이블에서 바로 가져올 수 있는 기본 정보들은 굳이 변수에 담아 또 출력시키는 일을 할 필요가 없었다는 생각이 들었다.
이에 title, release_date, poster_image, trailer, description 등과 같은 정보들은 바로 담을 수 있다.
2. _set 매니저 이용
genre와 country의 경우 _set 매니저를 이용하여 한번에 담을 수 있었다.
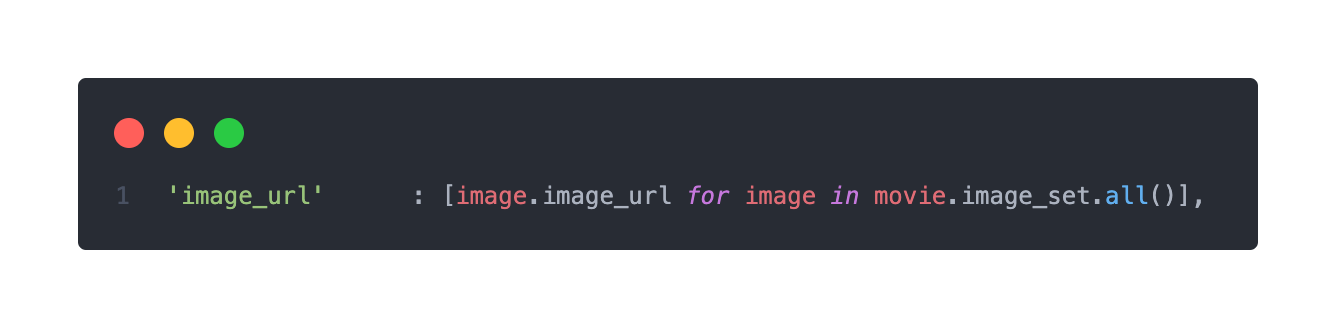
image_url의 경우도 동일하게 담을 수 있다는 판단이 들었고, 기존에 설정했던 movie 객체를 이용하여 아래와 같이 담았다.
3. comprehension 이용
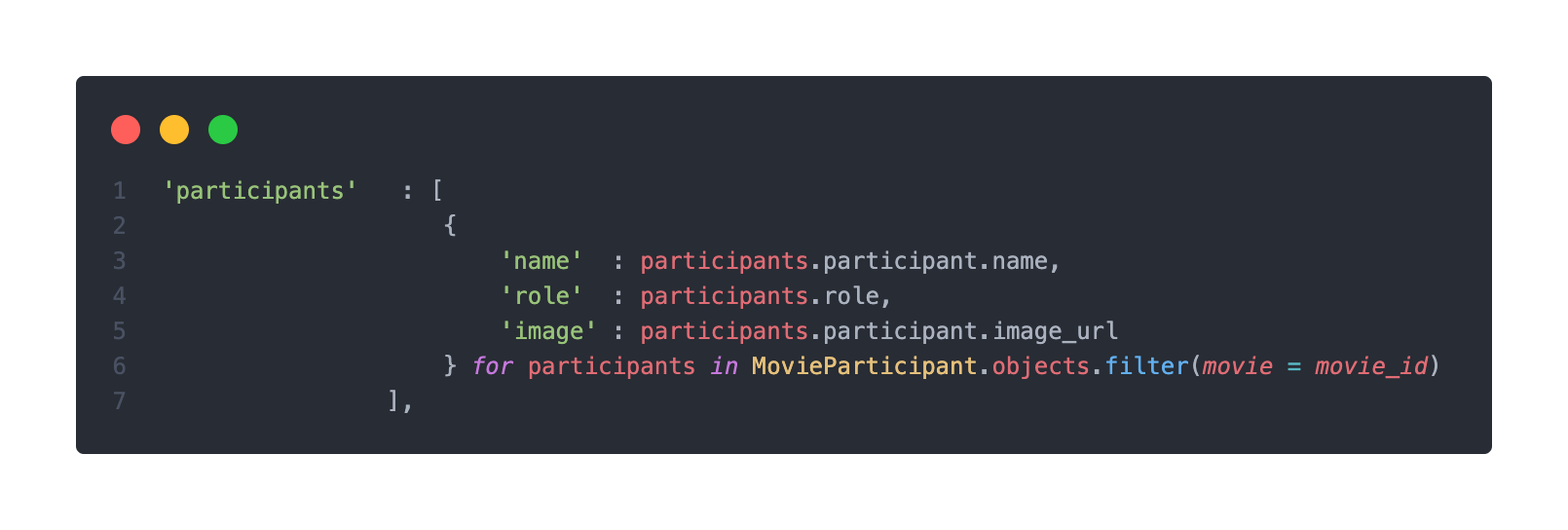
participant의 경우도 비슷한데, 굳이 변수를 따로 호출할 필요 없이 list comprehension을 이용하면 하나에 바로 담을 수 있다.
앞에서 이에 대해 공부하여서 비교적 쉽게(?) 적용할 수 있었다.
(비교적 쉽게라고 했지만 거의 한 15분은 왔다갔다한듯..)
4. .aggregate 메소드 이용
위에선 평균을 구하기 위해, user와 rating 객체를 하나하나 불러와 총 수를 구하고, 전체를 더하는 방식을 이용했다.
멘토링을 통해 간단한 힌트를 듣고난 뒤, 쿼리셋에 집계함수를 이용할 수 있는 aggregate 메소드가 있다는 것을 알게 되었다.
aggregate 메소드를 이용하여 MIN, MAX, COUNT, Avg등을 사용할 수 있다고 한다.
내가 쓰고자 하는 데이터에 접목해보면, 아래와 같이 만들어볼 수 있다.
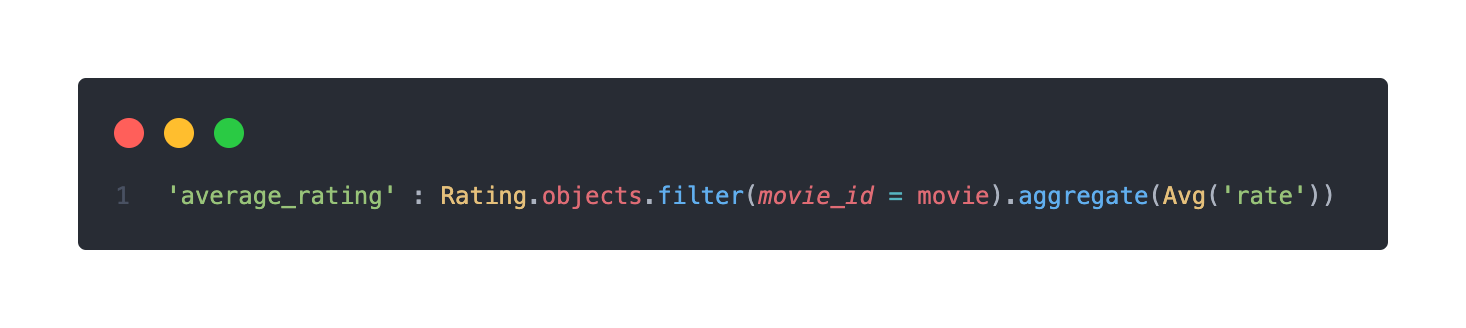
movie 객체와 같은 id를 가진 객체를 Rating 테이블 내에서 filtering하고, 그 테이블 안의 해당 영화 객체들의 rate row들의 평균을 구해주는 것이다.
이를 DB 안에 영화를 예시로 뽑아보면 아래와 같이 나온다.

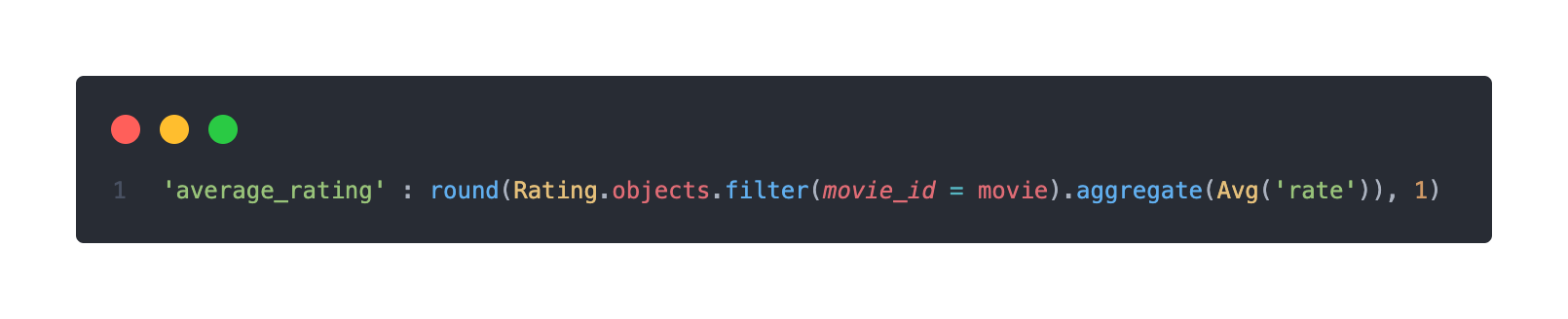
나는 소수점 한자리만으로 제한하고 싶으므로 아래와 같이 코드를 바꿨다.
이를 POSTMAN으로 뽑으니 오류가 떴다.
혹시 저 rate__avg를 기준으로 설정해줘야하나 싶어서 아래와 같이 바꿔보았다.

POSTMAN으로 실험을 해보면..

잘 나온다.
.aggregate 메소드 사용시 주의점
이렇게 변경을 하고 나니 차이점을 보였다.
나는 실제 코드 안에서 averagr_rating key의 value로 바로 float 형식의 별점이 뽑히길 원했지만, 별도로 설정을 해주지 않으면 아래와 같이 dictionary 형태로 출력이 되었다.
그러므로 코드 내에서 별도로 ['rate_avg']으로 특정을 해주어야 제대로 출력이 가능한 것이다.
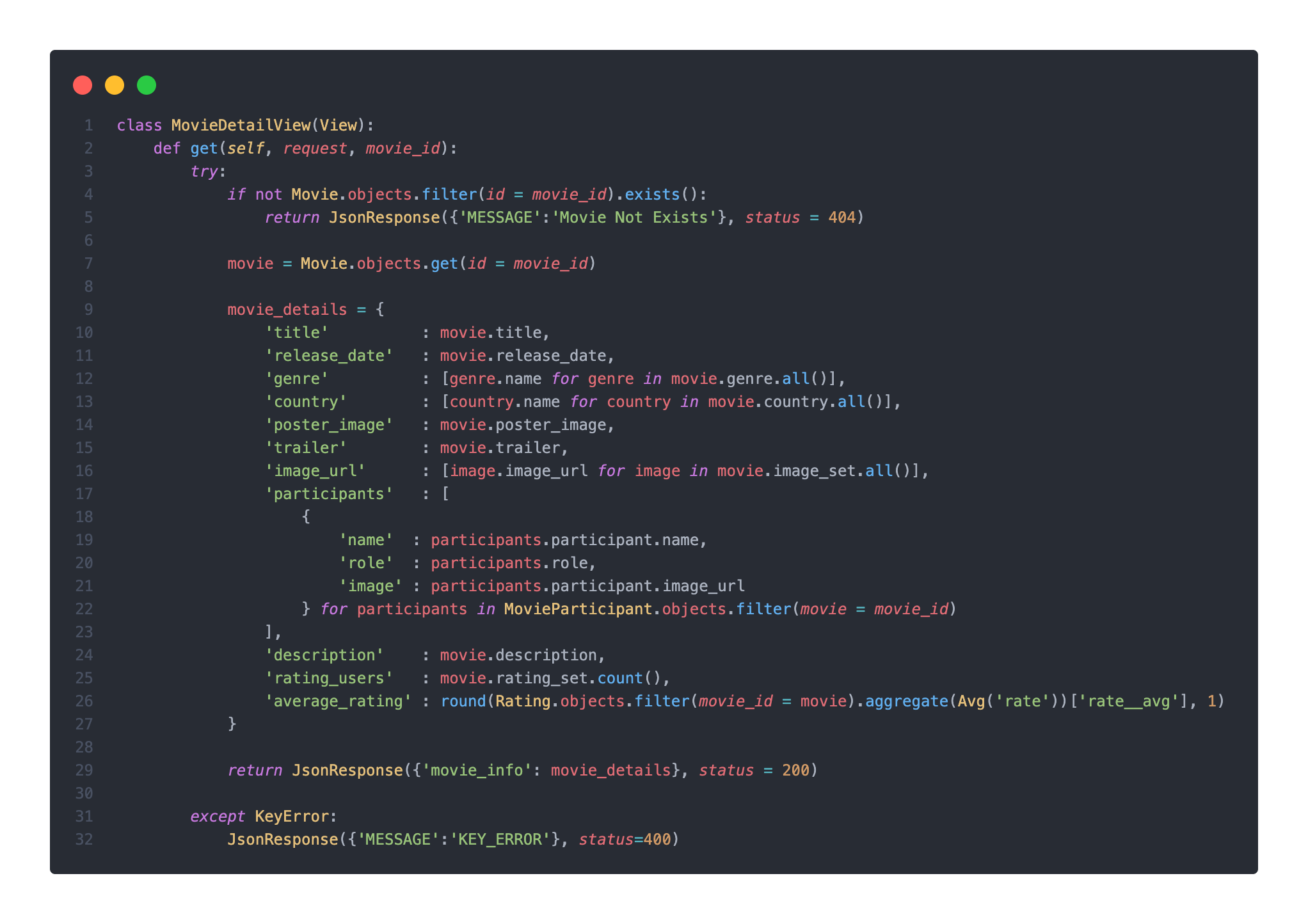
최종 코드
리팩토링을 마친 나의 최종 코드는 아래와 같다.
Take Away
후련함
처음 상세페이지 뷰를 시작할 때는 간단할거 같으면서도 불안했는데, 역시나 나의 얕고 모호했던 지식이 나의 발목을 잡았다.
조금식 어긋나있었던 나의 머릿속 지식을 하나하나 끄집어내어 조립하고, 재정렬시켜가며 한줄의 코드를 완성시켜나갈때마다 재미와 희열, 아쉬움을 동시에 느꼈던 것 같다.
리팩토링은 필수
처음엔 엄청나게 길었던 나의 코드도, 멘토링과 동기들의 도움을 거치면서 하나하나 다듬어나가니 내가 보기에 나름 만족스러운 코드로 변해나갔다.
단순히 출력이 되게 만드는건 쉽지만, 얼마나 연산이 적게 이용되고, 변수를 적게 부르며, 쿼리셋을 적게 이용하느냐에 따라 최적화의 효율을 낼 수 있다고 하니..
그저 만들고 작동하기만 하면 끝! 이라는 생각으로 코딩을 하면 안될 듯 하다.
참고
https://velog.io/@magnoliarfsit/ReDjango-8.-QuerySet-Method-2
