Regions with CNN
object detection에 최초로 딥러닝을 적용한 RCNN에 대해 정리해 보려고한다.
RCNN방식은 Region proposal 방식에 기반한 object detection이다.
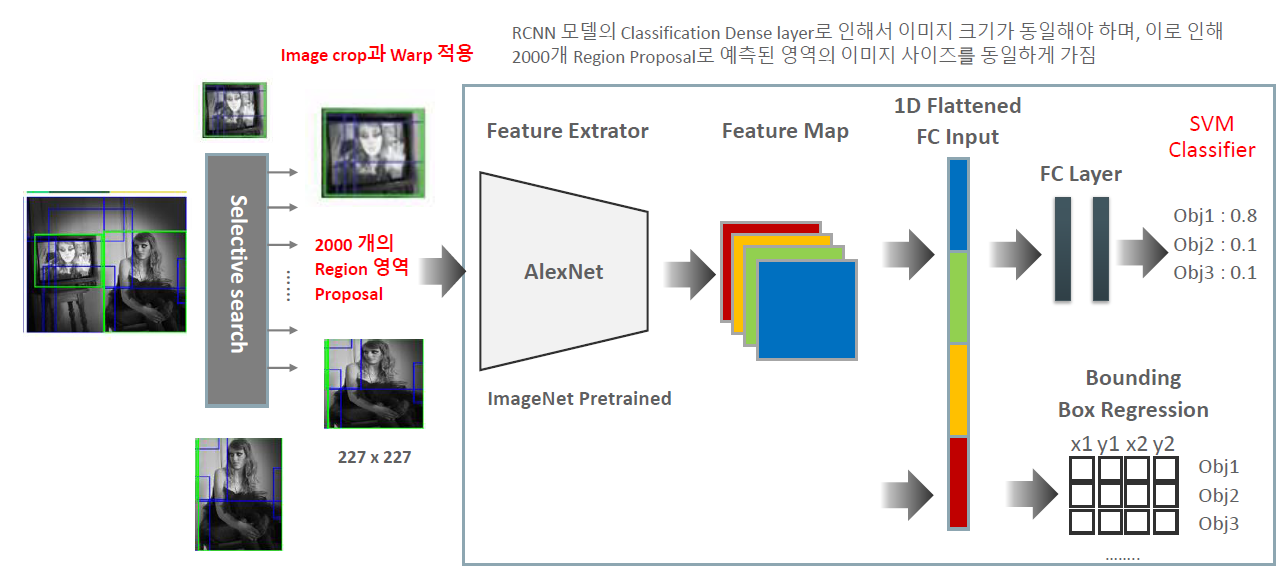
RCNN (Region-based Convolutional Neural Network)은 Object Detection을 수행하는 딥러닝 기반 알고리즘이다. RCNN의 작동 방식을 다음과 같이 요약할 수 있다.
- Region Proposal: 먼저 입력 이미지에서 Object가 있을 만한 후보 영역을 추출하기 위해 selective search 알고리즘을 사용한다. 이를 통해 약 2000개의 Bounding Box 후보들을 생성한다.
2. Bounding Box 정규화: 추출된 각 Bounding Box를 동일한 크기로 조정한다. 딥러닝 모델에 입력하기 위해서는 일정한 크기를 가져야 한다. 따라서, 원본 이미지보다 찌그러진 이미지가 입력으로 사용된다.
-
Feature Extraction: Bounding Box 후보 영역에서 CNN(Convolutional Neural Network)을 사용하여 특징을 추출한다. 주로 사전 학습된 CNN 모델(VGG, ResNet 등)을 사용하여 Bounding Box 내부의 Feature Map을 생성한다.
-
Classification and Bounding Box Regression: 생성된 Feature Map을 입력으로 받아, 해당 영역에 어떤 Object가 있는지 분류(Classification)하고, Object의 Bounding Box의 위치를 조정(Bounding Box Regression)한다. 이를 위해 추가적인 Fully Connected Layer와 SVM(Support Vector Machine)을 사용하여 Classification과 Bounding Box Regression을 수행한다.
-
Fine-tuning: RCNN은 미리 학습된 CNN 모델을 사용하며, 해당 모델의 가중치를 고정하고 Bounding Box 후보 영역을 학습시킨다. 따라서, RCNN은 CNN 모델을 특징 추출기로 사용하며, SVM과 같은 전통적인 머신 러닝 알고리즘을 활용하여 Object Detection을 수행한다.
RCNN은 CNN과 전통적인 머신 러닝 알고리즘을 결합한 형태로, 완전한 딥러닝 기반의 Object Detection 기법은 아니다. 그러나 RCNN은 Object Detection 분야에서 좋은 성능을 보여주었고, 후속 모델인 Fast R-CNN, Faster R-CNN 등의 발전된 버전이 개발되었다.
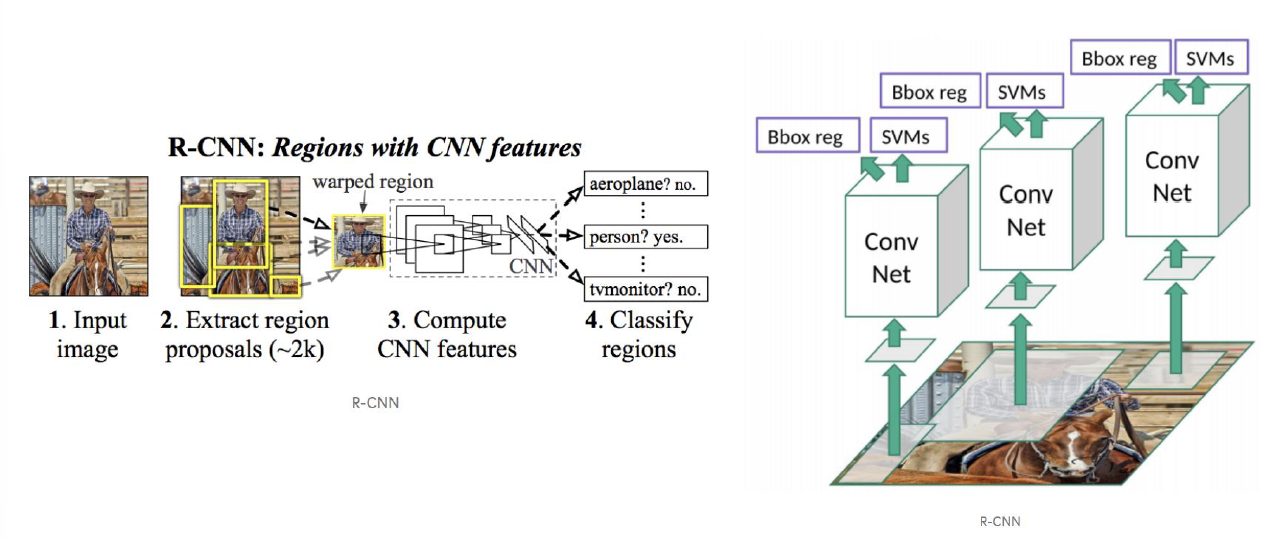
그림을 참고해서 보면 conv Net을 통해 feature map을 추출하고, 이를 분류할 때 경험적으로 SVM을 이용했을 때 예측 성능이 잘 나왔기 때문에 혼합된 알고리즘을 만든것이 RCNN인 것을 알 수 있다.
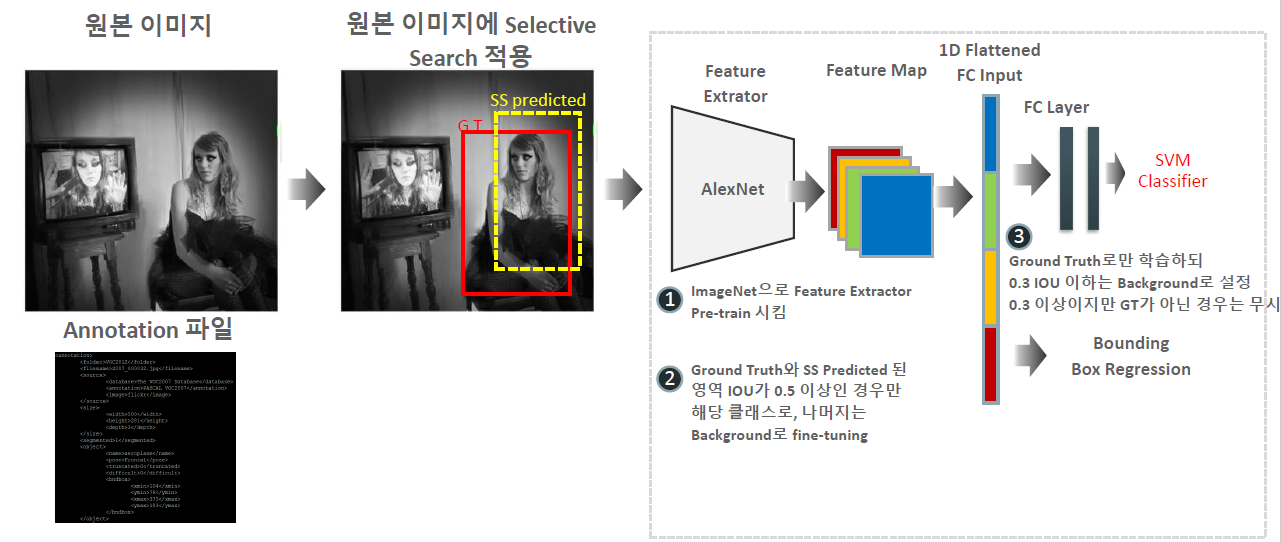
2013년 당시 나와있는 alexNet을 기반으로 해서 구현한 알고리즘으로, FC layer까지 딥러닝을 통해 feature extraction을 통해 학습시킨다. 이후 pretrained된 모델에 fine-tunning을 시킨다. 예측한 object가 있을 만한 위치를 함께 적용해서 학습을 시켜야 한다. IOU가 0.5이상일 때 해당 클래스로 학습시키며, 그 이하는 background로 fine-tunning을 시킨다. 이후, 만들어진 feature map을 SVM을 이용해 다시 학습시킨다. 이런 과정을 통해 나온 2000개 분류를 ground truth로만 학습하되 0.3 IOU이하는 backgtound로 설정하고, 0.3 이상이지만 GT가 아닌 경우는 무시해서 최종 학습을 한다.
bounding box regression
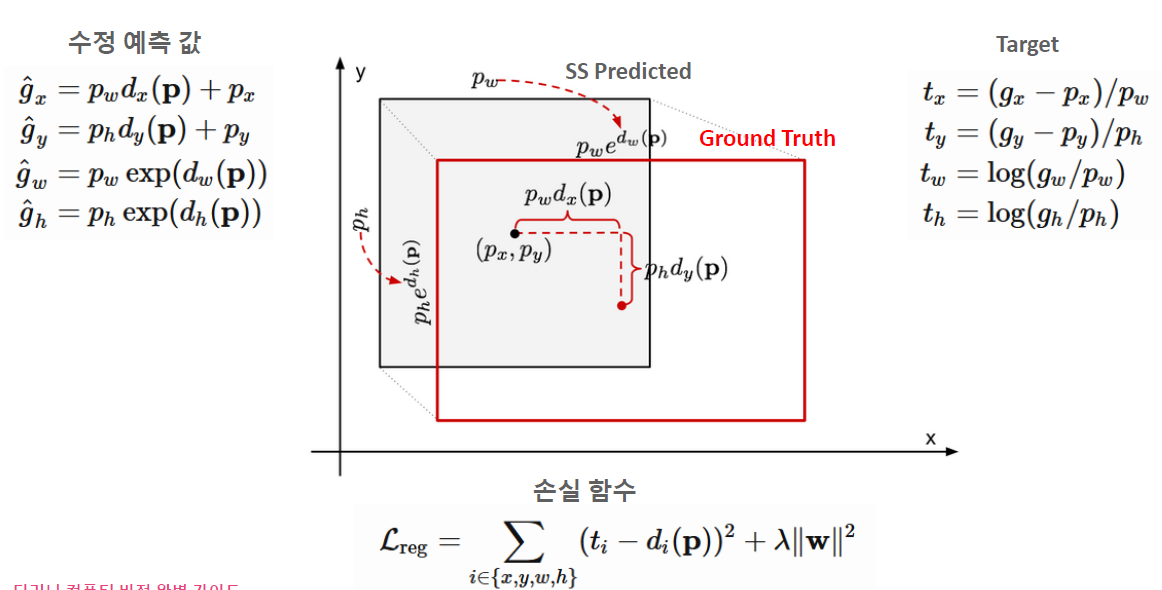
bounding box regression에 대한 예측 평가는 어떻게 할까?
RCNN은 regression을 통해 나온 SS prediected의 중앙값(Px, Py)값과 Ground Truth의 중앙 값의 차를 통해 판단하며, 중앙값의 거리의 차(loss)가 최소가 되도록 optimization한다. 즉, 앙값(Px, Py)의 거리 차이를 최소로 만들기 위해 손실 함수를 정의하고, 역전파 알고리즘을 사용하여 가중치를 업데이트한다.
RCNN 성능
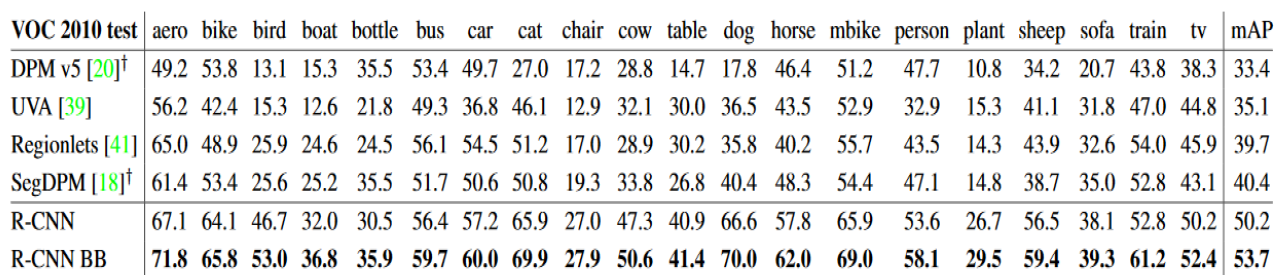
동시대에 다른 알고리즘에 비해 매우 높은 성능을 보여준다. 하지만 실행 속도가 느린 특징을 보여주어 아쉬운 점이 남긴한다. 하지만 object detection을 딥러닝을 적용해서 확연한 성능을 보여줄 수 있다는 선도적인 알고리즘인 것은 분명하다.
