Object detection 성능평가: IoU
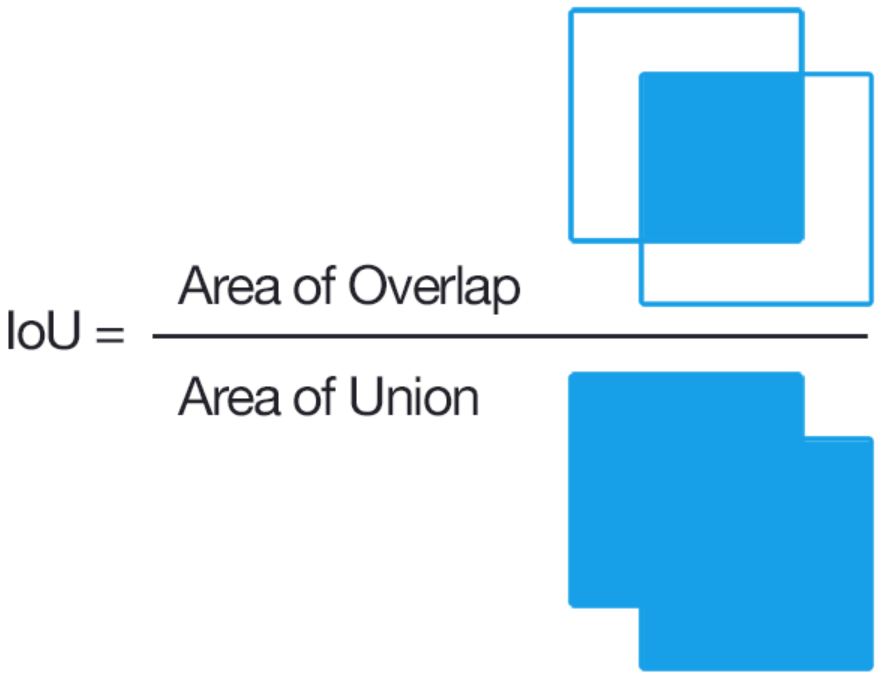
Intersection over Union (IoU)는 Object Detection에서 Object Detection의 정확도를 측정하기 위한 지표 중 하나로, Object Detection 결과와 Ground Truth간의 겹치는 면적의 비율을 나타내는 값이다.
IoU의 분자는 Object Detection 결과와 Ground Truth의 Bounding Box에서 겹치는 면적이다. 예를 들어, Object Detection 결과와 Ground Truth가 모두 동일한 Object를 검출한 경우, 분자는 Object Detection 결과와 Ground Truth의 Bounding Box가 겹치는 면적이 된다.
IoU의 분모는 Object Detection 결과와 Ground Truth의 Bounding Box 면적의 합에서 분자(겹치는 면적)를 빼준 값이다. 이 값은 Object Detection 결과와 Ground Truth의 Bounding Box가 겹치는 면적 대비, 둘의 전체 면적의 차이를 나타내는 값입니다. 예를 들어, Object Detection 결과와 Ground Truth가 서로 다른 Object를 검출한 경우, 분모는 Object Detection 결과와 Ground Truth의 Bounding Box 면적의 합에서 겹치는 면적을 뺀 값이 된다.
따라서, IoU 값이 1에 가까울수록 Object Detection 결과와 Ground Truth의 Bounding Box가 유사하며, 검출된 Object의 정확도가 높다는 것을 의미합니다. 반면에, IoU 값이 0에 가까울수록 Object Detection 결과와 Ground Truth의 Bounding Box가 매우 상이하며, 검출된 Object의 정확도가 낮다는 것을 의미한다.
IoU 기준은 사용하는 데이터셋이나 Object Detection의 목적에 따라 다를 수 있지만, 보통 0.3: poor, 0.7: good, 0.9: excellent로 판단한다고 한다.
NMS(Non Max Supression)
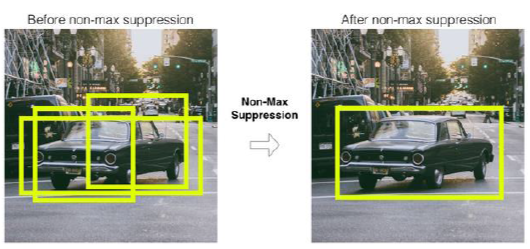
NMS(Non-Maximum Suppression)은 Object Detection에서 중복되는 Bounding Box를 제거하는 기법 중 하나다. NMS는 Object Detection 모델에서 생성된 Region Proposal에 대해 적용된다.
NMS는 먼저, Object Detection 모델이 생성한 모든 Region Proposal 중, Confidence Score가 가장 높은 Region Proposal을 선택합니다. 이후, 선택된 Region Proposal과 다른 Region Proposal 간의 IoU 값을 계산하여, IoU 값이 일정 기준 이상인 Region Proposal을 제거합니다. 이 과정을 모든 Region Proposal에 대해 반복합니다.
여기서 Confidence Score란, Object가 존재할 확률을 나타내는 값이다. 일반적으로 0과 1사이의 값으로 표현되며, 값이 높을수록 해당 Bounding Box가 선택된 클래스에 속할 확률이 높다는 것을 의미합니다. 예를 들어, Confidence Score가 0.8인 Bounding Box는 해당 클래스에 속할 확률이 80%라는 것을 의미한다. 따라서, Object Detection에서는 Confidence Score를 이용하여 Object Detection 결과의 신뢰도를 판단하고, 후처리 과정에서 Confidence Score가 일정 수준 이상인 Object Detection 결과만을 선별하여 사용한다.
다시 돌아가서, NMS를 적용하면 동일한 Object를 검출한 여러 개의 Bounding Box 중, 가장 Confidence Score가 높은 Bounding Box를 선택하고, 나머지 중복되는 Bounding Box를 제거할 수 있다. 이를 통해, Object Detection 결과의 정확도를 향상시키고, 중복된 Bounding Box로 인한 성능 저하를 방지할 수 있다.
NMS에서 IoU 값의 기준은 보통 0.5다. 즉, IoU 값이 0.5 이상인 Bounding Box를 중복으로 간주하고, 제거한다. 이 기준은 Object Detection 모델에서 가장 일반적으로 사용되는 기준 중 하나이다.
mMAP
mAP (mean Average Precision)이란 실제 Object 가 Detected 된 재현율 (Recall)의 변화에 따른 정밀도(Presion)의 값을 평균한 성능 수치이다.
mAP는 Precision-Recall Curve(P-R Curve)을 기반으로 계산된다. P-R Curve는 Object Detection 모델의 Precision과 Recall 값을 시각화한 그래프다. Precision은 모델이 검출한 Object 중 올바르게 검출한 Object의 비율을 나타내며, Recall은 검출해야 하는 Object 중 실제로 검출한 Object의 비율을 나타낸다.
mAP는 P-R Curve의 면적(Area Under the Curve, AUC)을 계산하여 얻을 수 있다. Object Detection 모델에서 여러 개의 클래스를 검출하는 경우, mAP는 모든 클래스의 AUC의 평균값으로 계산된다. 즉, 모든 클래스의 Precision-Recall Curve에 대한 AUC 값을 계산한 후, 이를 평균하여 mAP 값을 얻는다.
mAP는 Object Detection 모델의 다양한 클래스에 대한 성능을 종합적으로 평가할 수 있으며, 모델의 성능을 비교하기 위한 대표적인 지표 중 하나다.
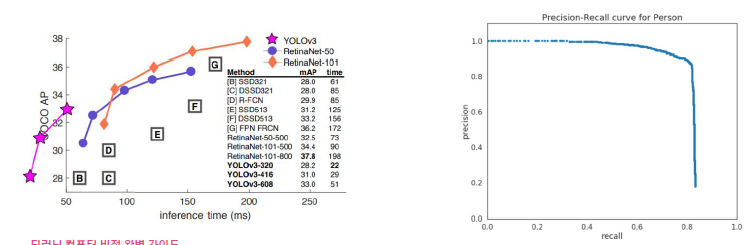
왼쪽의 그래프를 보면 x축은 inference time(ms)이 적으면 적을 수록 수행시간이 작으므로 우수한 method라고 할 수 있다. y값은 AP(Average Precision)로 성능수치를 나타낸다.
여기서 AP를 더 자세하게 설명하자면, AP는 P-R Curve 상에서 Precision이 일정 Recall 값을 기준으로 계산된다. AP는 Recall 값이 0부터 1까지 일정 간격으로 증가할 때, 해당 Recall 값에 대한 최대 Precision 값을 구한 후, 이들 Precision 값을 평균하여 계산하게 된다.
Precision과 Recall

Precision과 Recall은 Object Detection에서 검출 결과의 정확도를 측정하는 지표다.
Precision은 모델이 검출한 Object 중 실제로 해당 Object가 존재하는 비율을 나타내는 지표다. 즉, Precision이 높을수록 모델이 검출한 Object가 실제 Object와 일치할 확률이 높다. Precision은 다음과 같이 계산된다. 여기서, TP는 모델이 검출한 Object 중 실제로 해당 Object가 존재하는 개수를, FP는 모델이 검출한 Object 중 실제로 해당 Object가 존재하지 않는 개수를 나타낸다.
Precision = TP / (TP + FP)Recall은 실제 Object 중 모델이 검출한 Object의 비율을 나타내는 지표다. 즉, Recall이 높을수록 모델이 검출해야 하는 Object를 놓치지 않고 검출할 확률이 높아진다. Recall은 다음과 같이 계산된다.
Recall = TP / (TP + FN)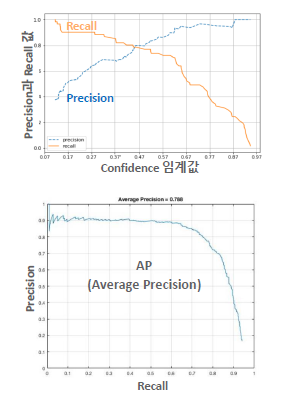
Precision과 Recall모두 높으면 좋겠지만, Precision과 Recall은 서로 trade-off 관계에 있다. 즉, Precision을 높이기 위해서는 모델이 검출한 Object의 수를 줄여야 하므로 Recall이 감소할 수 있으며, Recall을 높이기 위해서는 모델이 검출한 Object의 수를 늘려야 하므로 Precision이 감소할 수 있다. 따라서, Precision과 Recall은 Object Detection 모델의 정확도를 평가할 때 함께 고려해야 한다.
또, Precision이 높아야 하는 경우가 있는데 안전을 보장해야 하는 경우,비용이 큰 작업을 수행해야 하는 경우, 모든 Object를 검출해야 하는 경우가 있다.
안전을 보장해야 하는 경우는 예를 들어, 자동 운전차량의 Object Detection 모델의 경우, Precision이 높아야 한다. 왜냐하면, 모델이 잘못된 Object Detection 결과를 내리는 경우, 인명사고를 유발할 수 있기 때문이다.
비용이 큰 작업을 수행해야 하는 경우는 예를 들어, 의료 영상에서 종양 등을 검출하는 Object Detection 모델의 경우, 검출 결과를 검토하기 위한 추가적인 검사나 수술 등의 비용이 많이 들기 때문에, Precision이 높아야 한다.
반대로 Recall이 높아야 하는 경우는 모든 Object를 검출해야 하는 경우와 Object의 검출률이 중요한 경우가 있다.
모든 Object를 검출해야 하는 경우는 예를 들어, CCTV나 보안 검색 등에서는 검출해야 하는 Object들이 있다. 이 경우, Recall이 높아야 해당 Object를 놓치지 않고 검출할 수 있다.
Object의 검출률이 중요한 경우는 마케팅에서는 모든 고객들을 검출할 때를 예를 들 수 있다. 이 경우, Recall이 높아야 해당 고객을 놓치지 않고 검출할 수 있다.
오차행렬(confusion Matrix)
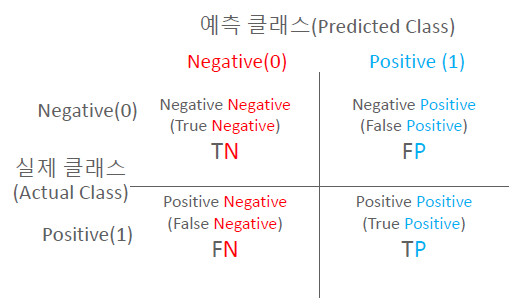
오차행렬은 실제 값과 예측 값을 비교하여, 모델이 예측한 결과를 TP(True Positive), TN(True Negative), FP(False Positive), FN(False Negative)으로 구분하여 나타내는 것이다.
- TP(True Positive)는 모델이 Positive라고 예측한 것 중에서 실제로 Positive인 것
- TN(True Negative)은 모델이 Negative라고 예측한 것 중에서 실제로 Negative인 것
- FP(False Positive)는 모델이 Positive라고 예측한 것 중에서 실제로 Negative인 것
- FN(False Negative)은 모델이 Negative라고 예측한 것 중에서 실제로 Positive인 것
오차행렬을 통해 Precision과 Recall 등의 평가 지표를 계산할 수 있다. Precision은 TP / (TP + FP)로 계산되며, Recall은 TP / (TP + FN)으로 계산된다. 또한, Accuracy는 (TP + TN) / (TP + TN + FP + FN)로 계산된다.
