Open Manus 로컬 및 Docker 사용
2025년 3월 6일 중국의 Monica에서 manus AI를 출시함
완전 자율형 인공지능 에이전트로서 단순한 챗봇을 넘어, 복잡한 작업을 독립적으로 계획하고 실행하는 존재
ReAct 기반으로 동작
- ReAct 프레임워크(Reasoning + Acting)를 기반으로 하여,
"생각(Thought)" → "행동(Action)" → "관찰 결과(Observation)"의 반복 과정을 통해 도구들을 필요에 따라 골라서 실행

환경 세팅
Method 1 : 로컬 Anaconda 환경 설정
[conda 가상환경 생성]
conda create -n open_manus python=3.12
conda activate open_manus
[git clone]
git clone https://github.com/mannaandpoem/OpenManus.git
cd OpenManus
[dependencies 설치]
pip install -r requirements.txtMethod 2 : Docker 환경 설정
[install uv]
curl -LsSf https://astral.sh/uv/install.sh | sh
[git clone]
git clone https://github.com/mannaandpoem/OpenManus.git
cd OpenManus
[venv 가상환경 세팅]
uv venv --python 3.12
source .venv/bin/activate # On Unix/macOS
# Or on Windows:
# .venv\Scripts\activate
[dependencies 설치]
uv pip install -r requirements.txt
playwright install (option)uv- Rust로 만든 최신 툴
- 가상환경 생성, 패키지 설치/관리 (
pip+venv+Poetry)
venv- python 기본 도구
- python 가상환경 생성 (.venv/ 폴더 생성)
cp config/config.example.toml config/config.toml이후 변경 및 실행
-
toml파일 복사 : 해당 파일에 사용할 api key를 넣어줄 수 있음 (gpt-4o/gemini 2.0 flash 사용) -
vs code 에서 docker 컨테이너로 작업 중 headless를 True로 바꿔야 웹 서칭이 가능해졌음
headless False > True -
vs code 상에서 실행 시 웹 브라우저 검색의 과정을 실시간으로 확인할 수 없어 아쉬움이 있었음
-
그래서 로컬 가상환경에서 실행한 결과, 첫번째 step에서 웹 브라우징 창을 띄우며 조사하고 그에 대한 결과를 출력해주었음

-
이후 사용자 입력 프롬프트에 대해 웹 브라우징 및 deep_searching 등의 tool을 사용하지 않고, LLM의 응답만을 출력하도록 명시했을 때,
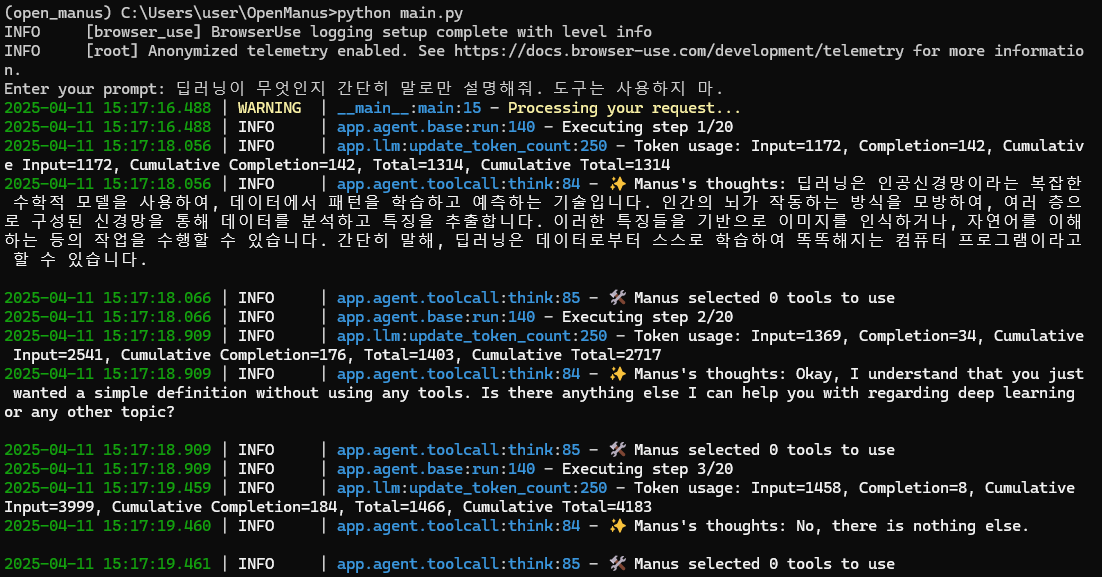
-
Gemini API만 사용하여 응답하는 것을 확인했음
OpenManus 코드 구조
- 터미널에서
python main.py로 실행하므로 main.py 파일부터 올라가봄
OpenManus
- main.py
- Manus 클래스 인스턴스를 생성, agent로 할당, 이 객체가 사용자 프롬프트를 받아서 행동을 수행
- 사용자 입력값만 받아서 app/agent/manus.py의 Manus 클래스로 비동기 통신
- main.py의 실질적 실행 로직은 우선 manus.py 파일로 가야 하는 것
- app/agent/manus.py
- Pydantic 모델과 ToolcallAgent 를 상속
- OpenManus 에이전트의 핵심 기능(기억, 추론, 툴 실행 등)이 ToolCallAgent에 구현되어있음 (ToolcallAgent > toolcall.py 파일에 정의됨)
- 에이전트가 사용할 수 있는 툴을 정의
- 최근 메세지 3개를 추출하여 그 안에 Browser_use_tool을 사용했다면, 브라우저 컨텍스트 도우미를 사용하여 브라우저 상태를 반영한 새로운 프롬프트를 구성 ex) next_step_prompt :: “검색 결과 ~~ 결과가 있어. 이제 어떤 도구를 사용해서 무슨 작업을 진행할까?”
- super().think() 호출하여 상위 ToolCallAgent의 추론 로직을 사용 (새로운 프롬프트를 통해 LLM에게 다음에 어떤 과정을 진행할지 답변을 받아오는 과정) ex) next_step_prompt > GPT > 이번엔 ~ 웹 페이지로 들어가서 웹 브라우징을 해보자.
- 이후 next_step_prompt는 원래의 프롬프트로 복원시킴 (추후 혼란 방지를 위해)
- app/agent/toolcall.py
- ReActAgent를 상속 → LLM이 생각하고 행동하는 구조기반
- 실제 행동(추론)을 하는 부분 → manus.py는 이 추론을 위해 방향성을 잡아주는 부분인 것
- 실행단
- 하단의 run(request)에서 상휘 에이전트의 run()을 실행
- 마지막에 cleanup()을 사용해서 자원 정리
- 추론단
- LLM에게 어떤 도구를 사용할지 물어보고, 응답에 따라 도구 호출 목록(tool_calls) 또는 텍스트 응답(content)을 저장
- next_step_prompt 있다면 메세지 스택에 추가
- llm.ask_tool()로 LLM 호출
- LLM 응답에 따라 도구면 tool_calls, 텍스트면 content에 저장
- 개별 도구 실행단
- execute_tool(command) : 도구 이름과 인자를 파싱하고 해당 도구 개체를 호출하여 실행
- available_tools_execute(name, tool_input) 호출 : 결과를 observation 형태로 정리
- specialtool(terminate)이면 _handle**special_tool()호출 → 상태 종료 → 결과 반환
- 도구들은 어디있나?
- 도구 정의 : app/tool/*.py
- 도구 수집 : ToolCollection class
- 실행 호출 : available_tools.execute() 이름에 맞는 툴을 찾아 실행
- 입력값 : LLM이 호출한 도구의 arguments를 dict로 전달
- 실행 메서드 : call() 또는 run()
- 출력값 : ToolResult / ToolFailure
- → 모든 도구는 baseTool 인터페이스를 상속해야만 ToolCollection으로 등록될 수 있음
- app/sandbox
- 도구가 직접 파일을 만지지 않고 sandbox를 우회해서 접근하도록 함
예시 상황
"웹 사이트 검색을 통해서 딥러닝이 어떤 건지 정리하고 txt 파일로 저장해줘”
- prompt = "웹 사이트 검색을 통해서 딥러닝이 어떤 건지 정리하고 txt 파일로 저장해줘”
- main.py → Manus.run(prompt)
- 해당 프롬프트는 Manus.next_step_prompt 로 들어가게 됨
- Manus.think()
# 현재 prompt를 메시지로 추가 selt.message += [Message.user_message(self.next_step_prompt)]- system_prompt : “너는 도구를 사용할 수 있는 AI 에이전트야. 필요한 경우 도구를 써”
- next_step_prompt : 사용자 프롬프트 적용
- ToolCallAgent.think() → llm.ask_tool()
- LLM에게 다음 질문을 함
“너는 Manus야. 지금 사용자 요청은 이거야. 사용할 수 있는 도구는 이것들이야. 다음에 뭐 할래?”tools: [BrowserUserTool, StrReplaceEditor, PythonExecute, Terminate] tool_choice : AUTO - 여기서 LLM이 판단
- 문장에 “웹 사이트 검색” → BrowserUserTool 호출
- 문장에 “정리” → 내부 요약
- 문장에 “txt 파일로 저장” → StrReplaceEditor 호출
-
즉 LLM은 아래와 같이 tool_call 구조로 응답
{ "tool_calls": [ { "name": "BrowserUseTool", "arguments": { "query": "딥러닝이란" } } ] }
-
- act()
- act()가 이 도구를 찾아서 실제로 실행함
- 결과를 memory에 저장
- 다시 think() 반복
- “이제 웹 검색 결과가 있어. 이젠 뭘 할래?”
- LLM이 이번엔 “StrReplaceEditor”를 호출해서 결과를 파일에 저장
MCP 파일의 역할?
- MCP는 외부 서버에 존재하는 도구들을 OpenManus 내부의 에이전트가 “실시간으로 연결해서 사용하는 인터페이스”
- 이를 통해 OpenManus는 자기 내부에 없는 기능도 외부 MCP 서버를 통해 확장할 수 있게 됨
-
app/tool/mcp.py
- 외부 MCP 서버와의 연동을 통해 “원격 툴”을 실행할 수 있도록 도와주는 도구 통합 클래스
- mcp.py는 MCP 서버에 연결해 원격 도구(tool)를 로딩하고, 해당 도구들을 마치 로컬 도구처럼 사용할 수 있게 래핑하는 역할
- 구성 요소
- MCPClientTool
- MCP 서버에 정의된 원격 도구를 나타냄
- execute() 시 실제로는 MCP 서버로 요청을 보내고 결과를 받아오는 프록시 역할
- 내부적으로 self.session.call_tool() 호출
- MCPClients (ToolCollection 상속)
- 여러 MCP 원격 도구들을 관리
- connect_sse() 또는 connect_stdio()로 MCP 서버와 연결
- session.list_tools()로 원격 툴 목록 조회 → MCPClientTool 객체로 변환 → tool_map에 저장
- 도구 목록을 정리해 OpenManus에서 쓸 수 있게 등록
- MCPClientTool
-
app/agent/mcp.py
- MCPAgent
- MCP 서버에 연결된 상태에서 도구를 사용하는 에이전트
- MCPAgent
-
app/prompt/mcp.py
- LLM이 MCP 도구를 적절히 사용할 수 있게 지침 제공
- SYSTEM_PROMPT
- NEXT_STEP_PROMPT
- TOOL_ERROR_PROMPT …MCP 작동 흐름 (Manus 에이전트 관점)
[1] MCPAgent 생성
[2] MCPAgent.initalize() 호출
→ MCPClients.connect_sse() 또는 connect_stdio()
→ MCP 서버에 연결
→ list_tools() → 사용 가능한 도구 목록 수신
→ MCPClientTool 인스턴스화 → Toolcollection으로 등록
[3] run(request) 호출
→ BaseAgent.run() → step() → think() → act()
→ LLM에게 SYSTEM_PROMPT+ nexy_step_prompt + tools 전달
→ LLM이 tool_call 반환 → MCPClientTool.execute() 실행
[4] 결과 수신
→ base64 이미지 포함 시 MULTIMEDIA_PROMPT 추가
→ terminate 호출 시 종료
