1. GROUP BY
집계 함수는 조건에 맞는 그룹에 대한 통계를 냄.
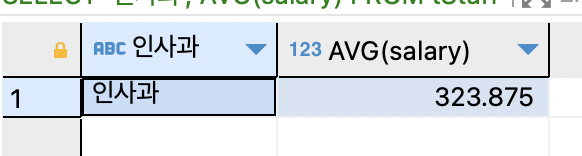
SELECT '영업부', AVG(salary) FROM tStaff WHERE depart = '영업부';
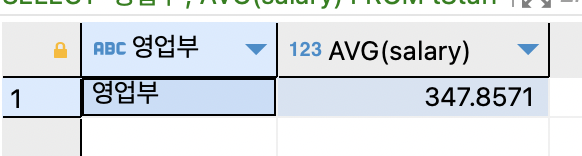
SELECT '총무부', AVG(salary) FROM tStaff WHERE depart = '총무부';
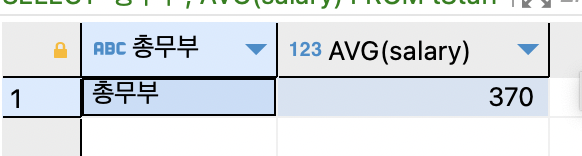
SELECT '인사과', AVG(salary) FROM tStaff WHERE depart = '인사과';
부서별 월급 평균을 알고 싶으면 부서마다 AVG 함수를 호출.
하지만 부서 목록을 만들고 각 부서마다 명령을 일일이 실행해야 하고 결과도 따로 출력되어 보기도 불편.
또한 집계함수와 일반필드를 같이 적을 수 없어 필드 목록에 부서명을 한 번 더 적어야 함.
이 경우에 필요한 구문이 GROUP BY.
기준이 되는 필드를 뒤에 적어주면 기준 필드가 같은 레코드를 모아 통계값을 구함. 게다가 기준 필드는 집계 함수와 같이 쓸 수 있어서 목록도 보기 좋게 출력 할 수 있음.
SELECT depart, AVG(salary) FROM tStaff GROUP BY depart;

부서별 월급 평균을 구하려면 depart 필드 기준으로 그룹핑.
1) 기준 필드순으로 정렬하여 같은 그룹끼리 구분해 놓고
2) 통계 대상 필드를 순서대로 읽어 집계를 구함.
GROUP BY 구문은 그룹핑을 해 줄 뿐이며 어떤 통계를 낼 것인가는 필드 목록의 집계 함수에 따라 달라짐.
SELECT depart, COUNT(*), MAX(joindate), AVG(score) FROM tStaff GROUP BY depart;

여러 개의 집계함수를 동시에 사용 가능.
부서별 인원수, 최근 신입 입사일, 성취도 평균을 한꺼번에 구함.
2. 기준 필드
GROUP BY의 기준 필드는 중복 값이 있을 때만 의미.
레코드별로 고유한 값을 가지는 필드는 그룹핑 기준으로 부적합하며(예 : 아이디), 구분이나 분류 필드가 적합.
한 부서에서 여러 직원이 소속되어 있고 부서가 같은 직원이 많기 때문에 부서별 집계가 가 능.
성별도 중복값이어서 그룹핑 필드로 적합.
SELECT gender, AVG(salary) FROM tStaff GROUP BY gender;
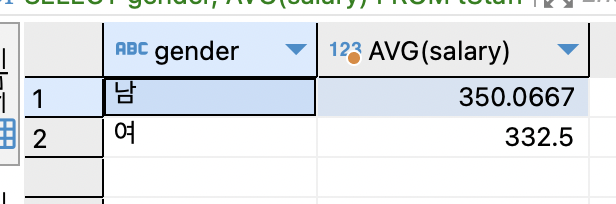
남녀 성별로 평균 월급을 구함. 성별은 남자, 여자 두 부류이며 그룹핑한 결과도 2개의 레코드로 출력.
중복 값을 가지는 필드만 그룹핑의 기준이 되는 것은 아니며 임의의 필드를 기준으로 그룹핑 할 수 있음.
이름을 기준으로 그룹핑을 하는 것도 문법적으로 가능하지만 전 직원의 월급이 각각 출력이 되어 의미가 없음.
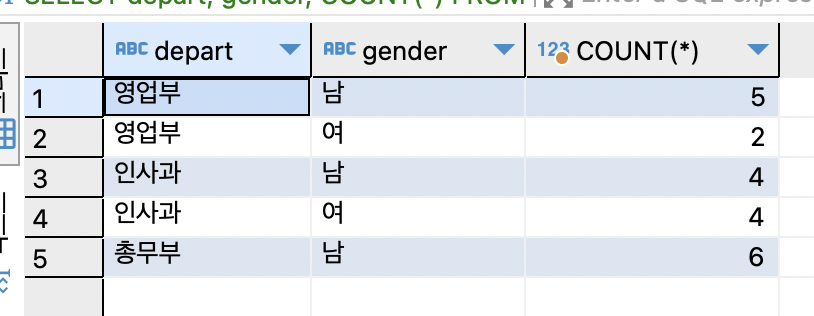
SELECT depart, gender, COUNT(*) FROM tStaff GROUP BY depart, gender;
기준 필드를 콤마로 구분하여 두 개 이상도 쓸 수 있음.
이 경우 첫번째 기준으로 그룹을 나누고 그 그룹 내에서 다시 두번째 기준으로 그룹을 나눔.
부서별, 성별로 그룹핑하여 직원수을 구함.
총무부는 여직원이 없어서 5개의 그룹만 나옴.
SELECT gender, depart, COUNT(*) FROM tStaff GROUP BY gender, depart;
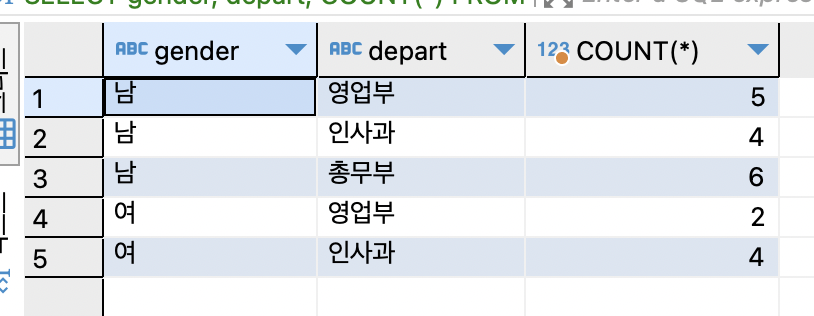
기준 필드의 순서는 그룹핑 과정에 영향을 주지만 결과에는 별 영향을 미치지 않음. 결과셋의 출력 순서가 다른데 순서는 별 의미가 없음.
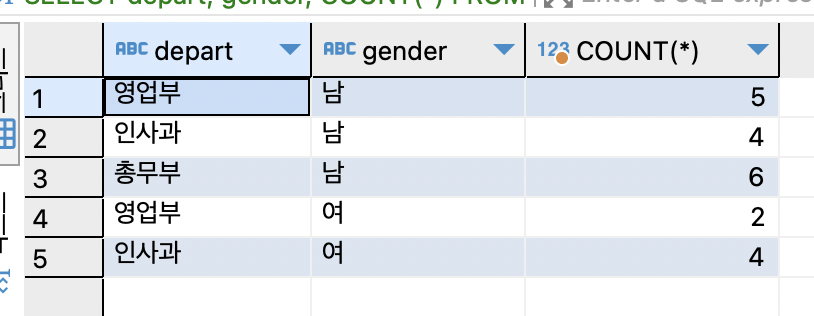
순서는 ORDER BY로 조정 가능
SELECT depart, gender, COUNT(*) FROM tStaff GROUP BY depart, gender ORDER BY gender, depart;
3. GROUP BY의 필드 목록
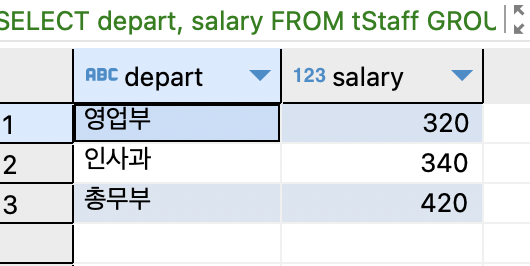
SELECT depart, salary FROM tStaff GROUP BY depart;
GROUP BY 절이 있으면 필드 목록에는 기준 필드나 집계 함수만 와야 함.
SELECT SUM(salary) FROM tStaff GROUP BY depart;
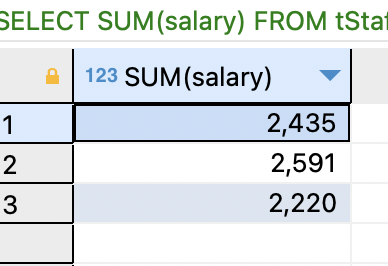
필드 목록의 제일 처음에는 통상 기준 필드를 출력하여 어떤 그룹에 대한 통계인지 표시. 기준 필드를 빼고 집계 함수만으로 쿼리를 구성하면, 계산은 똑바로 됐지만 각 행이 어떤 부서에 대한 통계치인지 알아 볼 수 없음.
SELECT depart, SUM(salary) FROM tStaff;
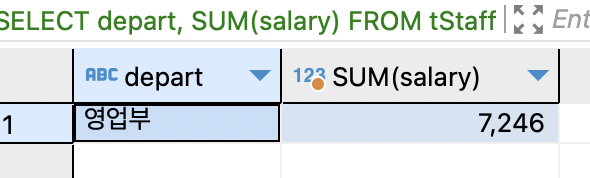
집계 함수는 다중 값이 있어야 계산할 수 있으므로 그룹핑을 할때만 유용,
GROUP BY 절 없이 일반 필드와 집계 함수를 같이 출력하면 의미가 없음.
레코드별로 고유한 부서명과 통계에 의해 계산하는 월급 총합은 같이 출력할 수 있는 값이 아 니라서
이 명령은 다음 둘 중에 하나로 수정하는게 적당.
SELECT depart, SUM(salary) FROM tStaff GROUP BY depart;

SELECT SUM(salary) FROM tStaff;

뒤에 GROUP BY 절을 붙여 부서별로 그룹핑하면 기준 필드인 부서명도 출력할 수 있고 부서의 월급 총합을 구하는 SUM 함수도 사용할 수 있음.
그룹핑 쿼리의 기본 형식은 다음과 같음.
SELECT 기준필드, 집계함수() FROM 테이블 GROUP BY 기준필드;
4. HAVING
HAVING은 GROUP BY 다음에 오며 통계 결과 중 출력할 그룹의 조건을 지정. 즉 HAVING은 GROUP BY 문의 조건절.
부서별 평균 월급을 출력하는 명령은 별다른 조건이 없으면 모든 부서의 평균 월급을 출력. 평균 월급이 340을 넘는 부서만 출력하고 싶다면 GROUP BY 다음에 HAVIING 절을 추가.
SELECT depart, AVG(salary) FROM tStaff GROUP BY depart HAVING AVG(salary) >= 340;
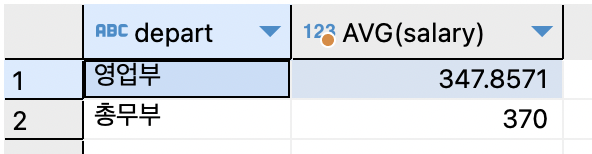
출력 순서를 지정할 때는 ORDER BY 절을 뒤에 붙임.
GROUP BY 다음에 HAVING이 오고 ORDER BY는 항상 제일 마지막.
조건을 제한하는 목적이면 WHRER 절이 이미 있음. WHERE 와 HAVING은 조건을 적용하는 단계가 다름.
SELECT depart, AVG(salary) FROM tStaff WHERE salary > 300 GROUP BY depart;

WHERE 절은 GROUP BY 앞에 나타나며 통계 대상 레코드의 조건을 제한.
월급 300 초과 조건에 의해 월급 300 이하의 직원은 평균에서 아예 제외되어 평균값이 더 높게 나타남.
만약 모든 직원의 월급이 300 이하이면 이 부서는 아예 결과셋에 나타나지고 않음.
HAVING 절은 GROUP BY 다음에 나타나며 집계한 결과셋의 조건을 제한. WHERE 와 HAVING은 적용 시점과 제한 대상이 다름.
SELECT depart, AVG(salary) FROM tStaff WHERE salary > 300 GROUP BY depart;

SELECT depart, AVG(salary) FROM tStaff WHERE salary > 300 GROUP by depart HAVING AVG(salary) >= 360 ORDER BY depart;

월급이 300 초과인 직원들을 대상으로 부서별 평균 월급을 구하고 그 결과 평균 월급이 360 이상인 부서만 고른 후 부서명으로 정렬.
WHERE 절이 직원목록에서 월급 300이하의 직원을 먼저 제거
-> 부서별로 그룹핑하여 AVG 함수로 남은 직원의 부서별 평균 월급을 계산.
-> HAVING 절에 의해 평균 월급이 낮은 부서는 제외. -> 남은 부서를 ORDER BY가 정렬하여 출력
처리과정을 이해하면 키워드의 순서도 자연스럽게 정리. GROUP BY 앞뒤로 WHERE 와 HAVING이 오고 ORDER BY는 마지막.
SELECT ... FROM ... WHERE ... GROUP BY ... HAVING ... ORDER BY
SELECT depart, MAX(salary) FROM tStaff WHERE depart IN ('인사과', '영업부') GROUP BY depart;
SELECT depart, MAX(salary) FROM tStaff GROUP BY depart HAVING depart IN ('인사과', '영업부');

두 쿼리 모두 인사과와 영업부의 최대 월급을 조사.
조건을 적용하는 시점은 다르지만 조건의 내용은 같아 최종 실행 결과는 같음. 하지만 내부적인 실행 과정은 차이가 있음.
1. WHERE 절은 집계전에 총무부를 제외하여 꼭 필요한 계산만 함.
2. HAVING 절은 모든 부서의 집계를 다 끝낸 후 총무부를 제거하는 식이라 출력하지도 않을 총무부이 집계까지 계산하여 비효율적.
5. INSERT
새로운 레코드를 추가하는 명령
INSERT 문을 스크립트로 작생해 놓으면 많은 데이터를 순차적으로 입력할 수 있어서 편리
기본형식
INSERT INTO 테이블 (필드목록) VALUES (값목록)
INSERT 는 삽입하라는 명령어이고
INTO 는 삽입 대상을 명시하는 전치사
INSERT INTO tCITY (name, aera, popu, merto, region) VALUES ('서울', 605, 974, 'y', '경기');
모든 필드를 선언 순서대로 삽입할떄는 필드 목록을 생략 할 수 있음
간단하게 하는 방법은 필드 목록이 없는 대신 값 목록이 완전해야 하며 순서도 반드시 지켜야 함
INSERT INTO tCITY VALUES ('평택', 453, 51, 'n', '경기');
INSERT INTO tCITY VALUES ('용인', 293, 98, 'n', '경기');
INSERT INTO tStaff VALUES ('임진구', '인사과', '남', 20230816, '사원', 300, 60); /* 날짜를 오늘 날짜로 하려면 now() 로 입력하면 됨 */

