1. COUNT
함수는 입력값으로부터 모종의 계산을 하여 출력값을 리턴하는 장치.
입력은 함수명 다음의 괄호 안에 인수로 전달하며 함수 호출문은 실행결과를 리턴.
테이블에 저장된 정보를 함수로 전달하면 원본 데이터를 변형, 가공하여 돌려줌.
함수 호출문이 하나의 값이므로 필드 목록이나 조건절 등에 값처럼 사용하면 됨.
집계 함수 Aggregate Function는 복수개의 레코드에 대해 집합적인 계산을 수행하여 합계, 평균, 분산 같은 통계값을 산출.
COUNT는 개수를 세는 기능을 하는데, 개수를 조사할 필드명을 전달하는데 * 지정하면 필드에 상관없이 조건에 맞는 레코드 개수를 리턴
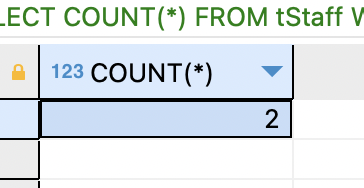
SELECT COUNT(*) FROM tStaff;

tStaff 테이블에 저장되어 있는 레코드 개수를 구함. 계산값은 열 이름이 없는데 별명을 부여하면 결과셋에 이름을 표시.
SELECT COUNT(*) AS "총 직원수" FROM tStaff;
SELECT COUNT(*) FROM tStaff WHERE salary >= 400;

WHERE 절을 붙이면 조건에 맞는 레코드의 개수를 구함. 월급이 400만원 이상인 직원의 수를 조사하고, 결과는 3 명.
SELECT COUNT(*) FROM tStaff WHERE salary >= 10000;

집계는 모든 레코드의 값을 참고하여 하나의 값을 구하는 것이어서 결과셋은 목록이 아닌 딱 하나의 값. 집계하는 말 자체가 다중값으로 부터 단일 값을 산출한 다는 의미.
조건에 맞는 레코드가 없어도 결과값은 역시 하나. 월급이 1억이 넘는 직원의 수를 조사하고, 결과는 0명.
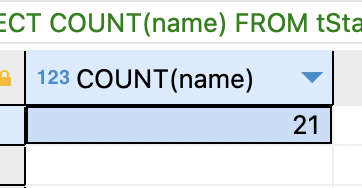
SELECT COUNT(name) FROM tStaff;
SELECT COUNT(depart) FROM tStaff;
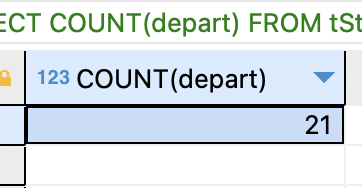
특정 필드의 개수를 구할때는인수로 필드명을 적음.
지정한 필드 값이 존재하는 레코드의 개수를 구함.
SELECT COUNT(DISTINCT depart) FROM tStaff;
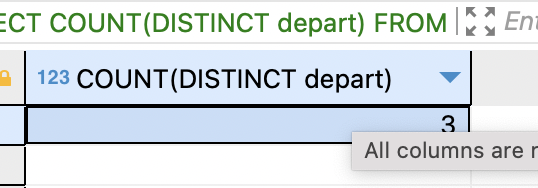
중복 부서를 제외하고 부서의 종류가 몇 개인지 알고 싶으면 필드명 앞에 DISTINCT 키워드를 붙임.
중복을 제거하고 3개의 부서가 있다고 출력.
SELECT COUNT(score) FROM tStaff;
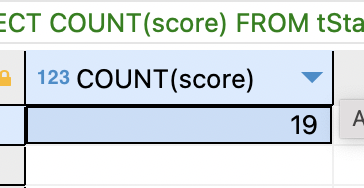
COUNT 함수는 '필드값이 제대로 들어 있는 레코드의 개 수만 구하며' 필드값이 NULL인 레코드는 개수에서 제외. name이나 depart는 NULL이 없어 전체 직원수와 같지만, score 필드는 NULL 값이 있음.
SELECT COUNT(*) - COUNT(score) FROM tStaff;
SELECT COUNT(*) FROM tStaff WHERE score IS NULL;
총 직원 수에서 score의 값이 NULL인 직원의 수을 구할 경우에는 위의 문을 사용.
COUNT 함수의 인수로 필드를 지정하는 경우는 드물고 COUNT(*)로 전체 레코드의 개수를 구하는 경우가 일반 적.
2. 합계와 평균
통계값을 계산하는 함수.
SELECT SUM(popu), AVG(popu) FROM tCITY;
도시 목록에서 인구의 총합과 평균을 구함.
SELECT MIN(area), MAX(area) FROM tCity;
면적의 최소값과 최대값을 구함. 모든 도시의 area 필드 를 조사하여 가장 작은 값과 가장 큰 값을 찾음.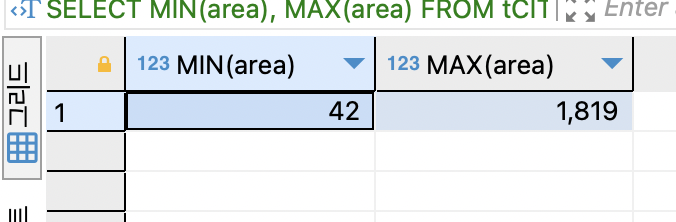
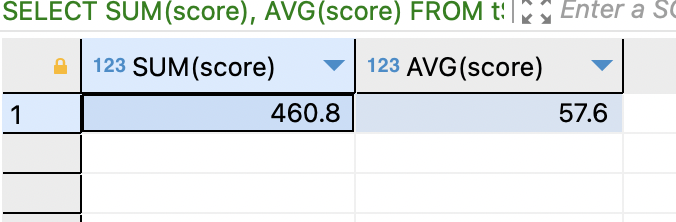
SELECT SUM(score), AVG(score) FROM tStaff WHERE depart = '인사과';
SELECT MIN(salary), MAX(salary) FROM tStaff WHERE depart = '영업부';
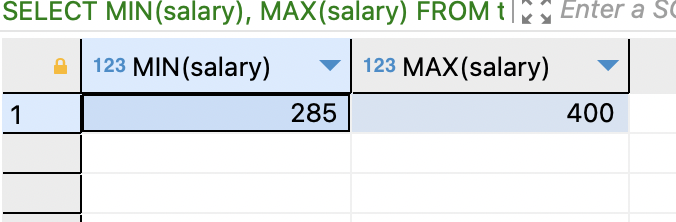
WHERE 절을 붙이면 조건을 만족하는 레코드에 대해서만 집계를 뽑음.
인사과의 총 실적 합계과 평균, 영업부에서 가장 낮은 월급과 가장 높은 월급을 구함.
SELECT SUM(name) FROM tStaff;
문자열 끼리는 더할수 없어 총합을 계산할 수 없고, 평균도 의미 없음
SELECT MIN(name) FROM tStaff;
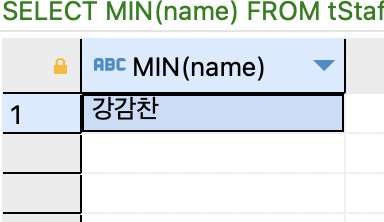
문자열 끼리는 사전순으로 비교할 수 있고, 날짜도 마찬가지 여서 문자열, 날짜에 대해서는 MIN, MAX 함수는 사용 가능
SELECT MAX(popu), name FROM tCITY;

인구가 제일 많은 도시인 서울의 값이 나올 것 같지만 서울의 인구수와 부산이 나옴
집계함수와 일반필드는 같이 사용하면 안됨
3. 집계 함수와 NULL
NULL은 값을 알수 없는 특수한 상태.
모든 집계 함수는 NULL을 무시하고 통계를 계산.
단, 예외적으로 레코드 개수를 세는 COUNT(*)는 NULL도 포함하지만, 인수로 필드를 지정하면 NULL을 세지 않음.
SELECT AVG(salary) FROM tStaff;
SELECT SUM(salary)/COUNT(*) FROM tStaff;

평균은 총합을 개수로 나누어서 구함. 그래서 두 명령은 동일한 결과를 보여줌.
SELECT AVG(score) FROM tStaff;

SELECT SUM(score)/COUNT(*) FROM tStaff;

SELECT SUM(score)/COUNT(score) FROM tStaff;

score의 경우에는 다른 값이 나옴.
AVG 함수는 NULL 값을 제외하고 계산을 하지만, COUNT(*)의 경우 NULL 값도 포함. SUM(score)/COUNT(score) 로 계산해야 정확.
NULL이 0을 나타내는 것일 수 있으므로 정책에 따라서 업무 규칙이 달라짐.
SELECT COUNT(*) FROM tStaff WHERE depart = '비서실';

SELECT MIN(salary) FROM tStaff WHERE depart = '비서실';

COUNT(*)과 다른 집계함수의 경우, COUNT(*)는 없다는 뜻의 0을 리턴하지만,
다른 집계함수는 계산 대상이 없어서 존재하지 않는 0이 아니라 NULL을 반환.
