기본형식
SELECT 필드목록 FROM 테이블 [ WHERE 조건 ][ ORDER BY 정렬기준 ]
1. ORDER BY
SELECT 명령에 별 지정이 없을 경우 레코드의 출력 순서 는 DBMS의 디폴트 순서를 따름.
오라클은 입력 순서을 기억해 그대로 출력하고, 마리아 디비는 기본키에 대해 오름차순으로 정렬.
관계형 DB에서 레코드의 물리적 순서는 큰 의미가 없고, 대신 출력할 때 ORDER BY 절로 정렬 순서를 원하는대로 지정.
기본형식
ORDER BY 필드 [ASC | DESC]
ORDER BY 다음에 정렬 기준 필드를 적고 오름차순일 경 우 ASC 키워드를, 내림차순일 경우 DESC 키워드를 지정. 순서를 생략하면 디폴트인 오름차순으로 적용되므로 키워드 ASC는 보통 생략.
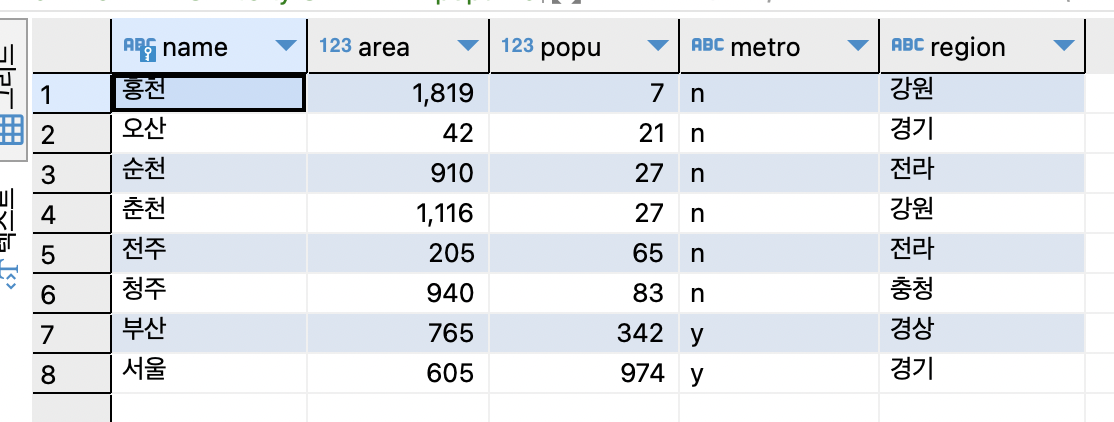
SELECT * FROM tCity ORDER BY popu ASC;
인구수를 기준으로 정렬하여 인구가 작은 도시부터 출력.
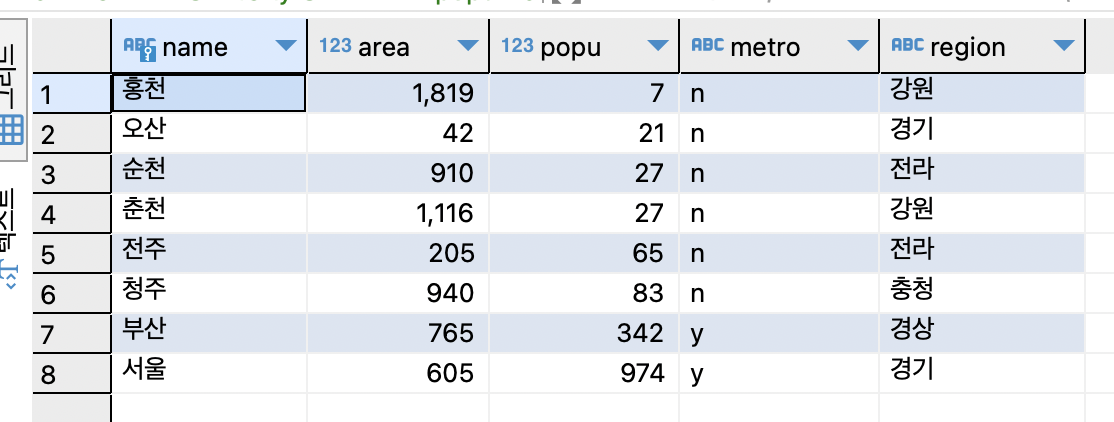
SELECT * FROM tCity ORDER BY popu DESC;
DESC를 붙이면 내림차순으로 정렬해서 인구가 많은 도시 부터 출력.
두개 이상의 기준 필드를 지정할 수 있음.
첫번째 기준 필드의 값이 같으면, 두번째 기준 필드를 비교하여 정렬 순서를 결정.
SELECT region, name, area, popu FROM tCity ORDER BY region, name DESC;
SELECT region, name, area, popu FROM tCity ORDER BY region ASC, name DESC;
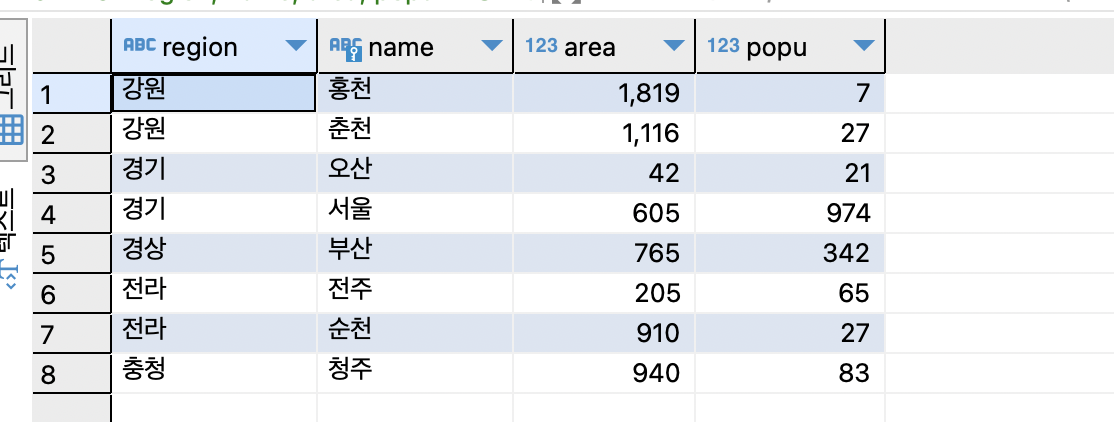
지역별로 정렬하되 같은 지역에 속한 도시끼리는 이름의 내림 차순으로 정렬.
ORDER BY 뒤에 기준 필드를 콤마로 구분하여 나열하되 각 기준별로 오름차순과 내림차순을 따로 지정 가능.
region은 순서를 지정하지 않았으므로 디폴트인 ASC가 적용.
1차 정렬 기준인 지역이 같으면 2차 기준인 이름순으로 정렬하되 이때는 DESC 내림차순으로 정렬.
ORDER BY 기준은 보통 필드명으로 하지만 순서값으로도 지정 가능.
필드 순서 값은 테이블 생성시에 등록한 순서.
tCity의 경우 name이 1번, area가 2번, popu가 3번.
SELECT * FROM tCity ORDER BY area;
SELECT * FROM tCity ORDER BY 2;
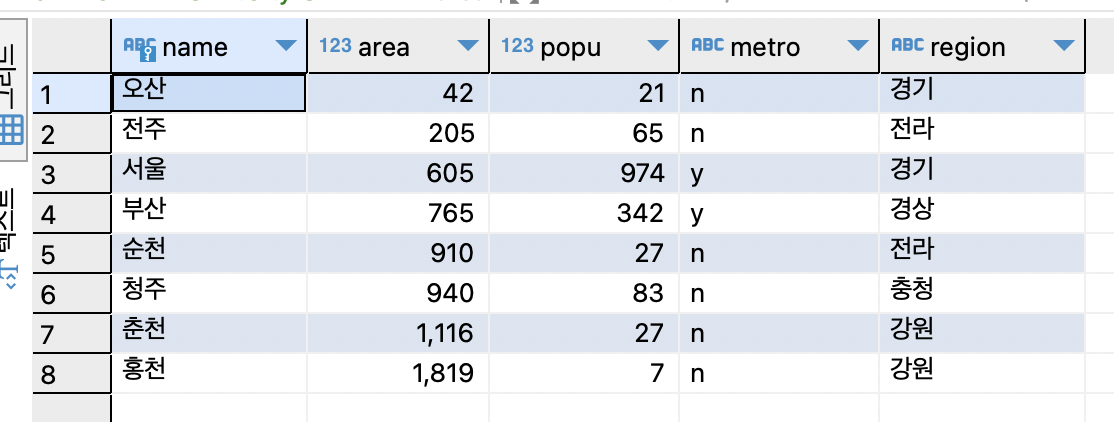
면적순으로 정렬하려면 area를 기준으로 하는 대신 2번 필드 기준으로 해도 결과는 같음.
테이블에 존재하는 모든 필드는 정렬 기준으로 사용 가능.
정렬 기준 필드를 출력 목록에 꼭 포함할 필요는 없음.
SELECT name FROM tCity ORDER BY popu;
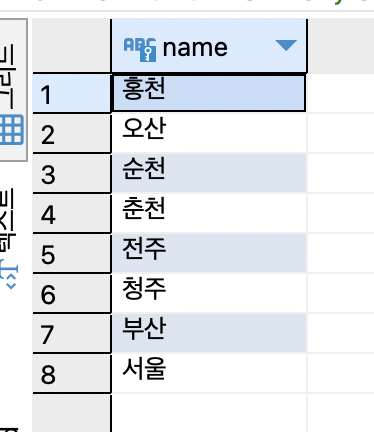
테이블에 존재하지 않은 계산값도 정렬 기준으로 사용할 수 있음.
SELECT name, popu * 10000 / area FROM tCity ORDER BY popu * 10000 / area;
SELECT name, popu * 10000 / area AS tmp FROM tCity ORDER BY tmp;
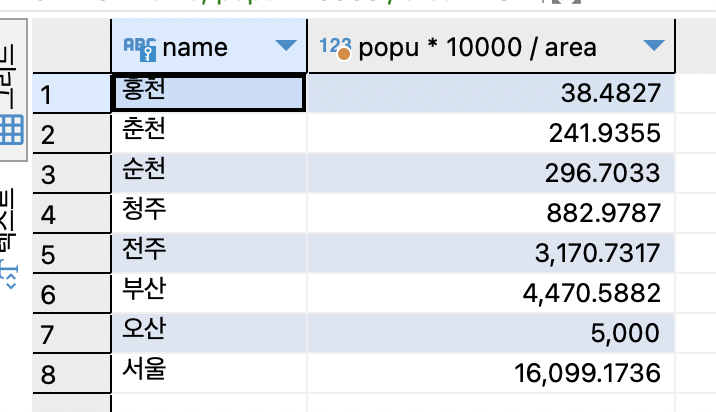
인구수와 면적으로 계산한 인구밀도의 오름차순으로 도시를 정렬.
정렬 기준을 꼭 같이 출력할 필요는 없지만 제대로 정렬 했는지 확인하기 위해 인구밀도를 같이 출력.
레코드의 조건을 지정하는 WHERE 절과 출력 순서를 지정 하는 ORDER BY 절을 동시에 사용 가능.
SELECT * FROM tCity WHERE region = '경기' ORDER BY area;

경기도에 있는 도시만 골라 면적별로 정렬.
이때 ORDER BY 절은 WHERE 절보다 뒤 쪽에 있어야 함.
아래와 같이 사용하면 에러.
SELECT * FROM tCity ORDER BY area WHERE region = '경기';
2. DISTINCT
SELECT region FROM tCity;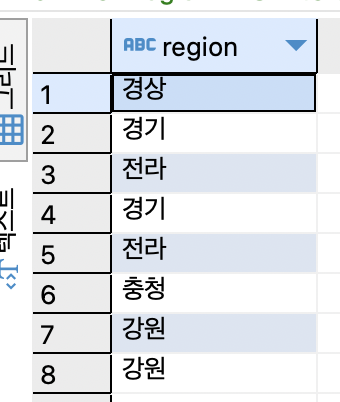
도시 테이블에서 region 필드만 읽어 도시가 속한 지역 의 목록을 조사.
같은 도시가 여럿 있으니 중복된 이름이 출력.
지역별로 몇 개의 도시가 있는지 알고 싶다면 상관 없지 만, 단순이 어떤 지역이 있는지만 조사한다면
굳이 중복된 값을 여러 번 출력할 필요가 없음.
중복된 값을 제거할 때 DISTINCT 키워드를 붙임.
SELECT DISTINCT region FROM tCity;
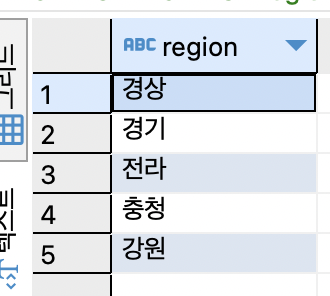
DISTINCT 키워드가 있는 필드는 중복값을 합쳐 한번만 출력.
DISTINCT 키워드로 중복 제거를 하다 보면 순서가 달라 짐.
만약 중복도 제거하고 정렬도 하고 싶으면 ORDER BY 절 을 붙임.
SELECT DISTINCT region FROM tCity ORDER BY region;
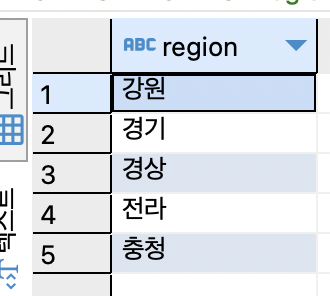
지역명을 중복없이 한 번만 출력하면 정렬까지 수행.
DISTINCT의 반대 키워드는 ALL 이며 중복 제거 없이 모 든 레코드를 출력.
ALL이 디폴트라서 굳이 지정할 필요는 없음.
SELECT DISTINCT depart FROM tStaff;
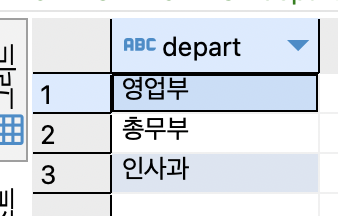
회사에 어떤 부서가 있는지 조사할 경우에는 DISTINCT 키워드를 붙이면 중복 부서명을 합쳐 한 번씩만 보여줌.
매출 테이블에서 매출액이나 판매 개수는 관심이 없고 오늘 어떤 상품이 풀렸는지만 알고 싶을 때 DISTINCT 키 워드가 유용.
3. LIMIT
LIMIT 구문으로 행수를 제한.
기본 형식
SELECT .... LIMIT [건너뛸 개수], 총개수
건너뛸 개수를 생략하면 0으로 적용하여 첫행 부터 출력.
SELECT * FROM tCity ORDER BY area DESC LIMIT 4;
SELECT * FROM tCity ORDER BY area DESC LIMIT 0, 4;
면적이 넓은 상위 4개 도시를 구하는 구문.
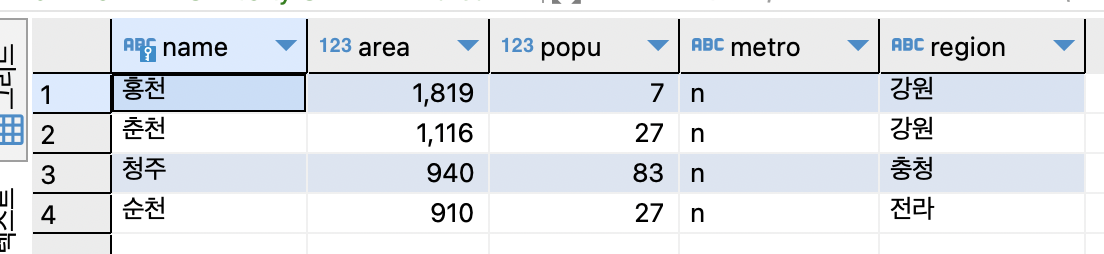
SELECT * FROM tCity ORDER BY area DESC LIMIT 2, 3;
앞쪽 2개는 건너뛰고 이후 3개의 행을 구함.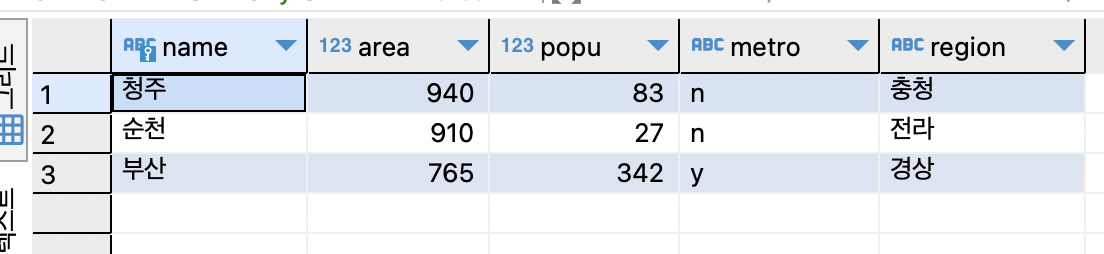
앞쪽 몇 개를 건너뛴 후 일정 개수 만큼 보여주는 이 구문은 게시물을 페이지 단위로 끊어서 출력할 때 실용적.
MySQL과 MariaDB가 게시판용으로 맹위를 떨치는 이유 중 하나가 이 구문.
4. OFFSET FETCH
테이블의 일부 레코드만 조회하는 작업은 빈도가 높고 실용적이지만 DBMS 별로 사용하는 문법이 다름.
SQL 표준이 새로 OFFSET FETCH 문법을 만듬.
일부분을 특정하려면 순서를 지정해야 되서 ORDER BY 문이 반드시 있어야 함.
그래서 OFFSET FETCH 는 별도의 구문이 아니라 ORDER BY 의 옵션.
ORDER BY 기준필드 OFFSET 건너뛸행수 ROWS FETCH NEXT 출력할 행수 ROWS ONLY
SELECT * FROM tCity ORDER BY area DESC OFFSET 0 ROWS FETCH NEXT 4 ROWS ONLY;
SELECT * FROM tCity ORDER BY area DESC LIMIT 0, 4;
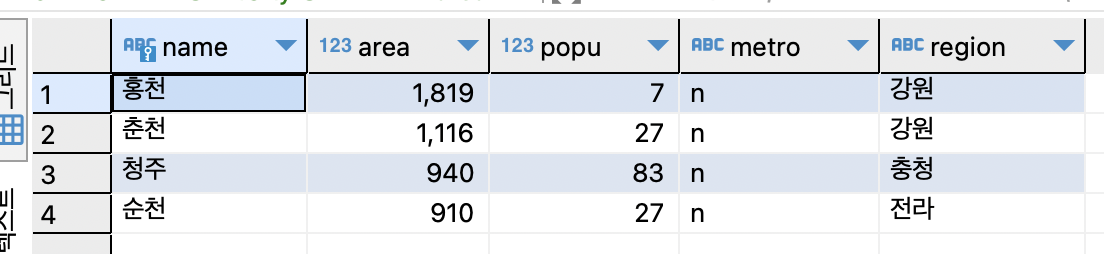
면적 순으로 상위 4개의 도시를 출력.
면적 내림차순을 정렬 후 4개의 행만 읽음.
OFFSET을 지정하면 앞쪽 일부를 건너뛸 수 있음.
SELECT * FROM tCity ORDER BY area DESC OFFSET 2 ROWS FETCH NEXT 3 ROWS ONLY;
SELECT * FROM tCity ORDER BY area DESC LIMIT 2, 3;
상위 2개를 건너 뛰고 다음 순서인 3, 4, 5위 3개의 도 시를 조사.

WHERE 구문과 함께 사용하여 필터링을 먼저 하고 그 중 일부 레코드만 출력할 수 있음.
SELECT * FROM tCity WHERE metro = 'n' ORDER BY area DESC OFFSET 2 ROWS FETCH NEXT 3 ROWS ONLY;
SELECT * FROM tCity WHERE metro = 'n' ORDER BY area DESC LIMIT 2, 3;
광역시는 제외하고 순위를 매겨 3등에서 5등까지 출력.

