Overview
- 논문
- github
- GPT-4를 활용해서 vison instruction set을 생성
- 이미 학습이 된 LLM 모델 (Llama, Viquna)를 활용
- Science QA에서 SOTA달성
Introduction
- 기존 멀티모달 태스크(데이터셋) 에서는 image-text는 단순히 이미지에 대한 설명으로 텍스트가 이루어짐 -> 질의응답과 같은 챗봇 형식에는 한계가 있음
- 이 논문에서는 LLM의 alignment 능력을 보고 그것을 활용
contribution
- multimodal instruction-following data
- GPT4로 instruction set를 생성
- large multimodal models
- Visual Encoder: CLIP
- Language decoder : Vicuna
- 생성한 instruction set으로 FT 진행
- multimodal instruction-following benchmark
- open-source
Method
1. Data Generation

- GPT4를 활용해서 기존의 image-text pair dataset을 multi modal instruction dataset 으로 변경
- 여기서는 image를 넣는 것이 아니라 text로만 GPT-4에게 입력을 줘서 생성함
- 따라서 image를 text로 나타내야하는데, 그때 다음 2가지 사용
- 1) Caption : 원래의 image-text pair의 caption text
- 2) Bounding box: scene의 object 위치
- 다음과 같은 타입으로 데이터를 생성함 (이때 사람이 seed examples는 생성해줌 - fewshot예제)
- 1) Conversation (58K)
- 사진에 대해 질문하는 사람과 대답하는 Assistant 사이의 대화
- 질문은 이미지의 시각정보 (객체 유형, 위치, 상대적 위치)등을 활용해서
- 2) Detailed description(23K)
- 이미지에 대한 풍부하고 포괄적인 설명을 제시할 수 있도록
- 3) Complex reasoning(77K)
- 단계별 추론을 해야지 대답할 수 있는 질문
- 1) Conversation (58K)
2. Visual Instruction Tuning
Architecture
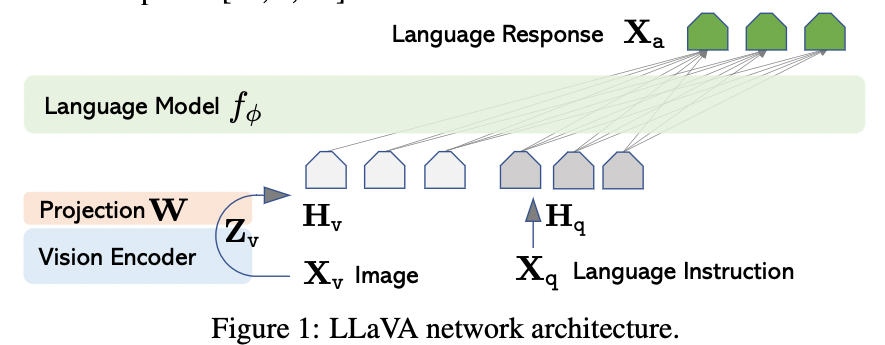
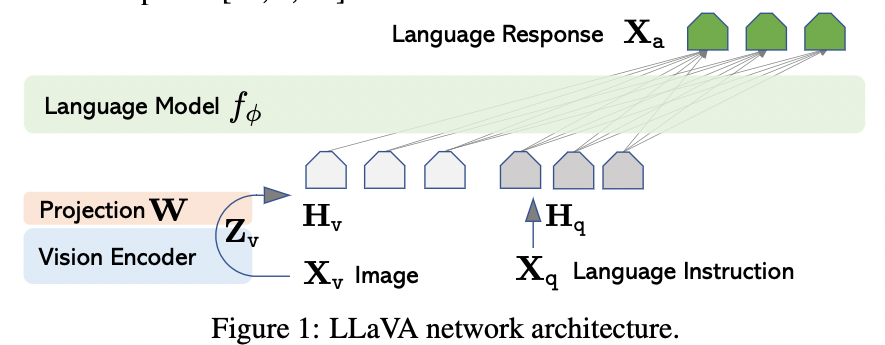
- Pre-trained CLIP visual encoder / Pre-trained LLM을 사용
- 이미지 feature(Z) Layer를 Word Embedding(H) Space에 연결하기 위해서 Projection(W)를 추가함
- Projection Layer의 output embedding은 LLM의 word embedding과 동일한 크기로
- 현재는 가볍고, 빠른 실험이 가능한 간단한 projection 을 쓰고 있지만 다른 것도 고려 충분히 가능함
Training
데이터 구성
-
각 이미지 X에 대해서 multi turn conversation data 생성
-
이때 instruction은 random으로 이미지-텍스트 순서를 변경함

-
그 후 instrcution tuning
- 이때는 Auto-regressive training objective를 사용
- 기존의 언어모델과 다른점 : 이미지 feature를 활용
학습
- LLaVA는 2단계로 학습진행
- 1) Pre-Training for Feature Alignment
- CC3M 데이터를 필터링 진행
- 그 후 싱글턴으로 데이터 셋을 생성 (이미지에 대해 간략하게 설명을 요청)
- visual encoder와 LLM weights는 freeze하고 그 둘사이를 이어주는 projection matrix만 업데이트
- epoch 1
- 2) Fine-Tuning End-to-End
- instruction data set을 가지고 instruction tuning 진행
- Projection Layer와 LLM 업데이트 이때 여전히 visual encoder는 freeze
- epoch 3
Experiment
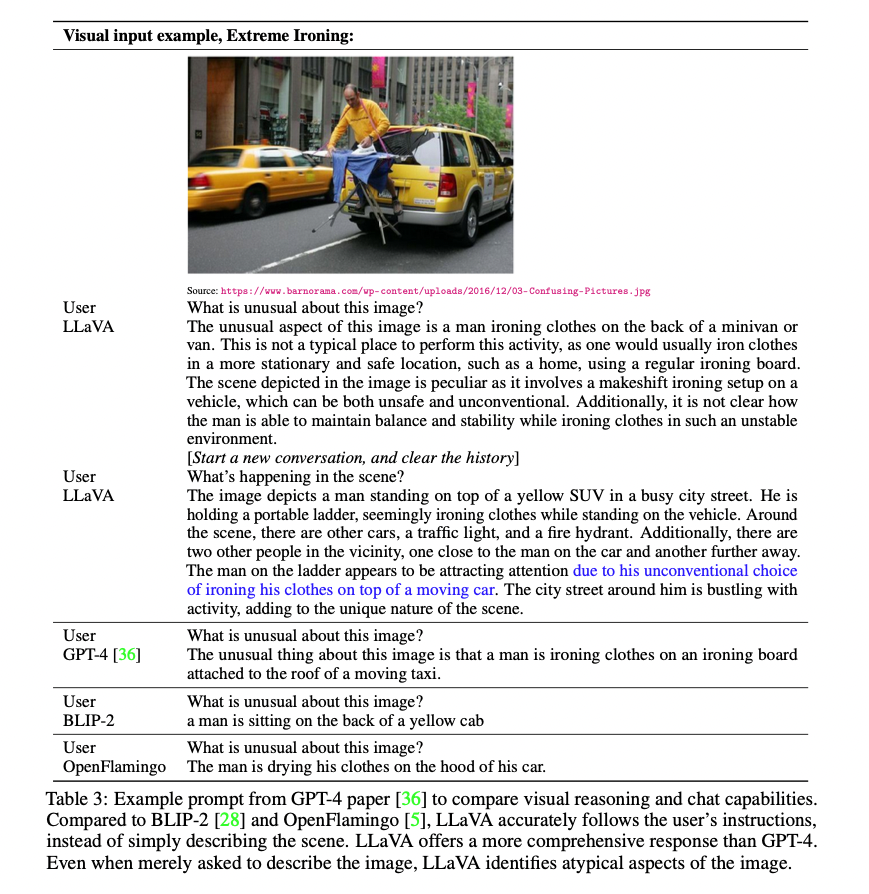
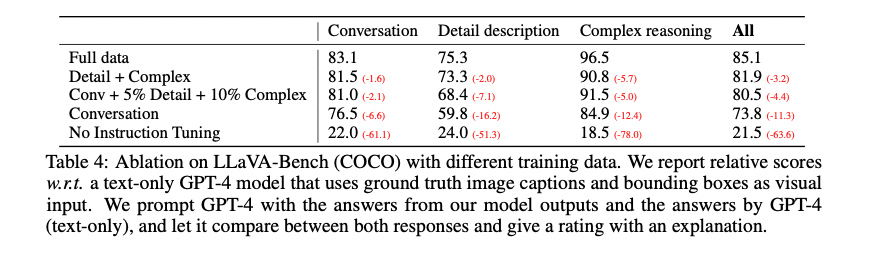
Appendix
Data Creation Fewshot Example

