Overview
- Paper
- Github
- Long Context Alignment를 위한 recipe인 LongAlign 제안
- Instruction-data: construct a long instruction-following-dataset
- training: packing & sorted batching strategies
- evaluation: LongeBench-Chat benchmark
Introduction
- 현재 Long-context LLM의 연구들은 context extension에만 집중
- Position encoding extension, continual training on long text
- 이 논문에서는 long context alignment 관점에서
- 즉 long user prompt를 handle할수 있는 instruction LLM model
- 하지만 다음과 같은 문제점 존재
- 1) long instruction following dataset의 부재
- 2) training efficiency 의 문제 (여러개의 길이를 가진 데이터 셋을 활용하다보니)
- 3) robust benchmark to evaluate LLMs' long-context capacities 가 필요함
- 이 논문에서는 위의 문제를 해결하기위해서 LongAlign recipe를 제안함
- Covering Data, efficient training, evaluation
LongAlign
Data
- 9개의 다양한 sources에서 데이터 수집
- books, encyclopedias, academic papers, code ....
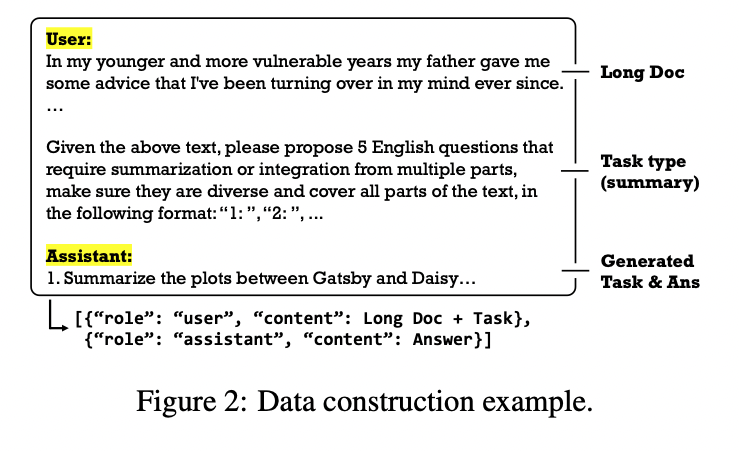
- 그리고 Instruction셋을 생성 (아래 prompt)생성
- 총 4가지 type (General, Summary, Reasoning, Information Extraction)

Efficient Long-Context Training
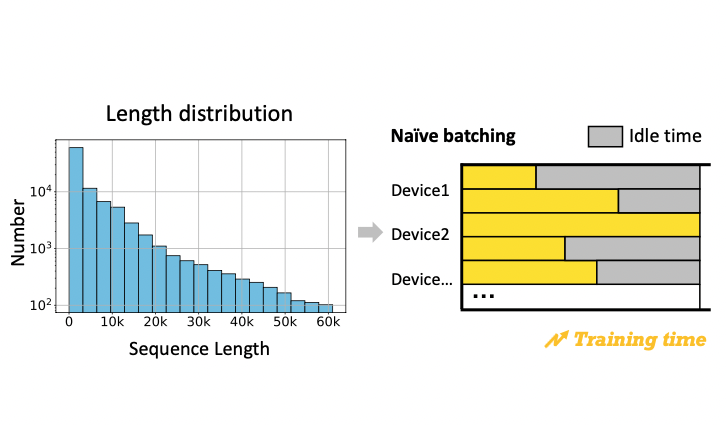
- short text에 대한 능력을 잃지 않기위해서 long instruction data와 short instruction data를 섞어서 학습 진행
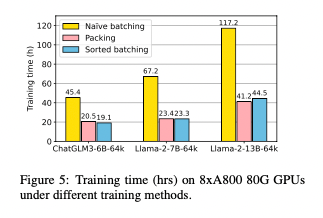
- 배치에 짧은 text와 긴 text가 섞이면서 아래와 같이 idel time이 발생하게 되고, training unefficiency발생
- 이를 해결하기 위해서 다음과 같은 방식 사용
Training 방법
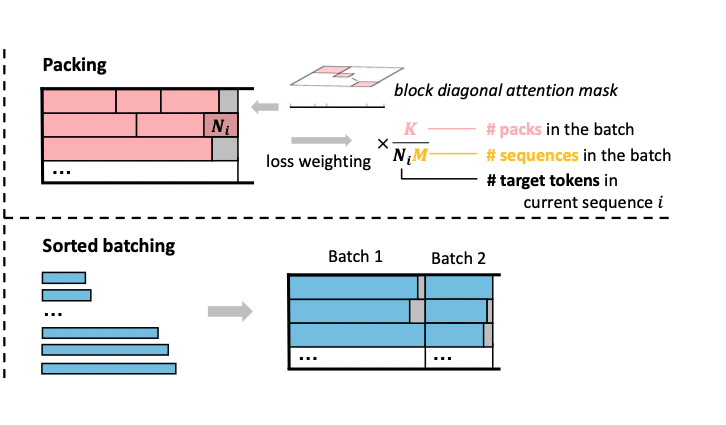
1. Packing
- 다른 length를 가지고 있는 data를 maximum length가 될때까지 concate
- self-attention 시 다른 sequence에 있는 것 끼리 계산이 되는 것을 방지하기 위해 staring\&ending positions을 같이
- Flash-Attention2도 같이 지원함
- 하지만 바로 이렇게 Packing을 활용하면 loss을 계산할 때 문제가 있음
- loss 계산시 target tokens이 더 많은 (대부분 긴 text에) 집중하게 됨.
- 따라서 이걸 완화해주기위해서 loss를 각 sequence마다 scale을 지진행해서 합침
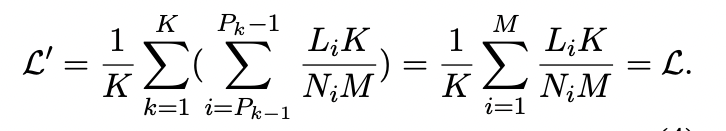
2. Sorted batching
- 데이터를 길이로 정려하고, 반복되지 않고 무작위로된 데이터 그룹을 배치마다 선택함.
Experiment
Training
- 8xA800 80G GPUs and DeepSpeed+ZeRO3+CPU offloading
- batch size to 8, resulting in a global batch size of 96
- 2 epoch
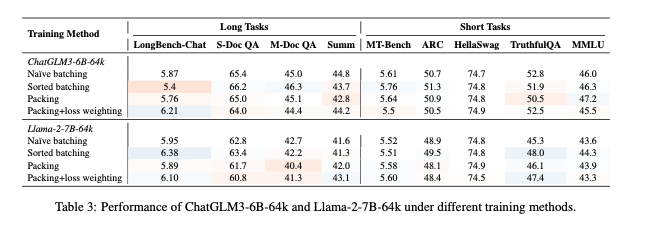
Performance