referenc: "전문가를 위한 C++" / 마크 그레고리
쓰레드 라이브러리와 쓰레드 작업 지정 방식
<thread>헤더 파일에 정의된 C++ 쓰레드 라이브러리를 사용하면 쓰레드를 간편하게 생성할 수 있다.- 플랫폼(OS)에서 제공하는 API가 아닌 C++ 표준 라이브러리를 사용함으로써 플랫폼 종속성에서 벗어날 수 있다.
#include <Windows.h> // 윈도우즈 API를 사용하여 쓰레드 생성
#include <thread> // c++ 11 제공
..
int main(){
//::CreateThread(..);
// 윈도우즈 API (#include <Windows.h>)
// 그러나 코드가 리눅스 환경에서 실행되면 해당 API가 호출될 수 없다.
// C++ 11 부터 OS 종속되지 않고 쓰레드를 생성할 수 있게 끔 <thread> 헤더를 제공해준다.
// 어떤 환경이든 상관없이 공용적으로 사용할 수 있음
// 분기 쓰레드 작업
std::thread t(helloThread); // 메인 쓰레드에서 하나의 쓰레드가 분기해여 병렬적으로 수행
// 메인 쓰레드 => 메인 쓰레드, 분기된 쓰레드
}쓰레드 작업 할당 방식
새로 만든 쓰레드가 할 일을 지정하는 방식은 다양하다.
- 전역 함수로 표현
- 함수 객체의 operator()로 표현
- 람다 표현식으로 지정
- 특정 클래스의 인스턴스에 있는 멤버 함수로 지정
1. 함수 포인터로 쓰레드 만들기
아래와 같은 전역 함수가 있다.
void counter(int id, int iterNum) {
for(int i=0; i<iterNum; i++)
cout << "Counter " << id << " has value " << i << endl;
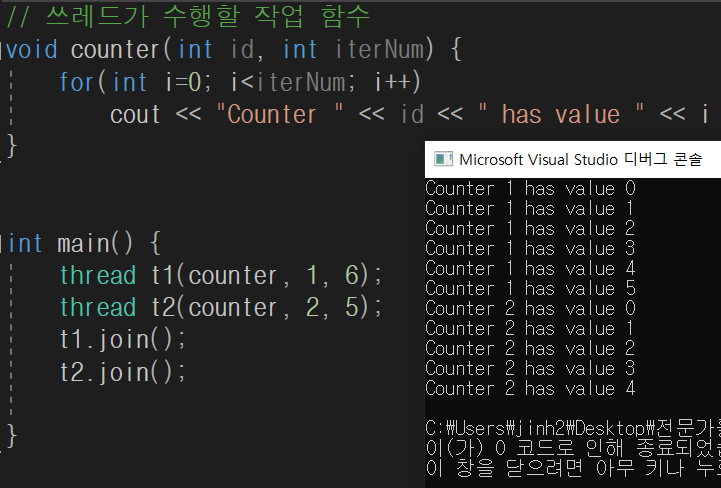
}std::thread를 이용하면 이 전역 함수를 여러 쓰레드로 실행하게 만들 수 있다. 인수로 1과 6을 지정해서 counter()를 수행하는 쓰레드인 t1을 다음과 같이 생성할 수 있다.
thread t1(counter, 1, 6);thread 클래스 생성자는 가변 인수 템플릿이기에 인수 개수를 원하는 만큼 지정할 수 있다. 첫 번째 인수는 새로 만들 쓰레드가 실행할 함수의 이름이고, 그 뒤에 나오는 인수는 쓰레드가 구동되면서 실행할 함수에 전달할 인수들이다.
2. 함수 객체로 쓰레드 만들기
함수 포인터로 쓰레드를 만들면 함수에 인수를 전달하는 방식으로만 쓰레드에 정보를 전달할 수 있다.
반면 함수 객체로 만들면 그 함수 객체의 클래스에 멤버 변수를 추가해서 원하는 방식으로 초기화해서 사용할 수 있다.
counter 함수가 아닌 클래스를 정의하고, ID와 반복 횟수를 멤버 변수로 갖게 한다. 그리고 함수 객체를 만들기 위해 operator()를 구현한다.
class Counter {
private:
int id;
int iterNum;
public:
Counter(int id, int iterNum)
: id(id), iterNum(iterNum)
{}
// 함수 객체화를 위해 operator() 구현
void operator()() const {
for(int i=0; i<iterNum; i++){
cout << "Counter " << id << "has value " << i << endl;
}
}
};이제 함수 객체로 만든 쓰레드를 초기화하는 방법이다. 크게 3가지 방법이 있다.
// (1) 유니폼 초기화를 사용
thread t1{Counter{1, 20}};
// Counter 생성자에 인수를 지정해서 인스턴스를 생성하면 그 값이 중괄호로 묶인 thread 생성자 인수로 전달된다.
// (2) 일반 변수처럼 네임드 인스턴스로 초기화
Counter c(2, 12);
thread t2(c);
// Counter 인스턴스를 일반 변수처럼 네임드 인스턴스로 정의하고,
// 이를 thread 클래스 생성자로 전달.
// (3) 임시 객체를 사용
thread t3(Counter(3, 10));
// Counter(3, 10) 호출 => 임시객체 생성
// 세 쓰레드를 모두 마칠 때 까지 메인 쓰레드가 기다린다.
t1.join();
t2.join();
t3.join();
3. 람다 표현식으로 쓰레드 만들기
람다 표현식은 표준 c++ 쓰레드 라이브러리와 궁합이 잘 맞는다.
int main() {
int id = 1;
int iterNum = 5;
thread t1([id, iterNum] {
for (int i=0; i<iterNum; i++) {
cout << "Counter " << id << "has value " << i << endl;
}
});
t1.join();
}4. 멤버 함수로 쓰레드 만들기
쓰레드에서 실행할 내용을 클래스의 멤버 함수로 지정할 수도 있다. 아래 코드는 기본 Request 클래스에 process()라는 메서드를 정의하고 있다.
main() 함수에서 Request 클래스의 인스턴스를 생성하고, Request 인스턴스인 req의 process() 메서드를 실행하는 쓰레드를 생성한다.
class Request {
private:
int id;
public:
Request(int id)
: id(id)
{}
void process() {
cout << "Processing request " << id << endl;
}
};
int main() {
Request req(10);
thread t{ &Request::process, &req };
t.join();
}이러한 방식으로 특정한 객체에 있는 메서드를 쓰레드로 분리해서 실행할 수 있다.
똑같은 객체를 여러 쓰레드가 접근할 때 데이터 경쟁이 발생하지 않도록 쓰레드에 안전하게 작성해야 한다. 이러한 구현 방법 중 하나는 상호 배제(뮤텍스)라는 기법을 사용하는 것이다.
std::thread 주요 메서드
- joinable
- join
- detach
- get_id
- hardware_concurency
생성된 쓰레드는 보통 부모 쓰레드에게 종료된 사실을 전달, 동기화 신호를 보내게된다. 부모 쓰레드가 아니라도 멀티쓰레드 프로그래밍에서 다른 쓰레드에게 동기화가 될 수도 있다. 어떻게되든 동기화 신호를 보낼 수 있는 쓰레드를 합류가능한 joinable thread라고 한다(참고로 디폴트로 생성된 thread 객체는 조인 불가능).
어떤 자식 쓰레드가 joinable한 상태인데 부모 쓰레드의 종료되면 abort 에러가 발생한다.
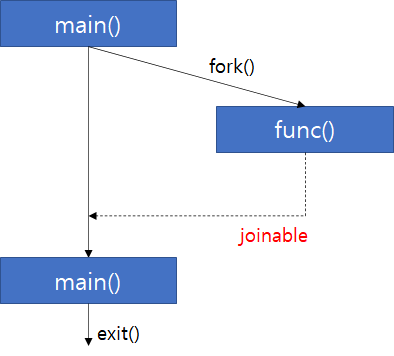
1. joinable()
생성된 쓰레드는 합류 가능한 상태라 하였다. 만약 합류 가능한 쓰레드가 종료되기 전에 해당 쓰레드의 부모 쓰레드의 작업이 끝나 회수되면 abort 에러가 발생한다.
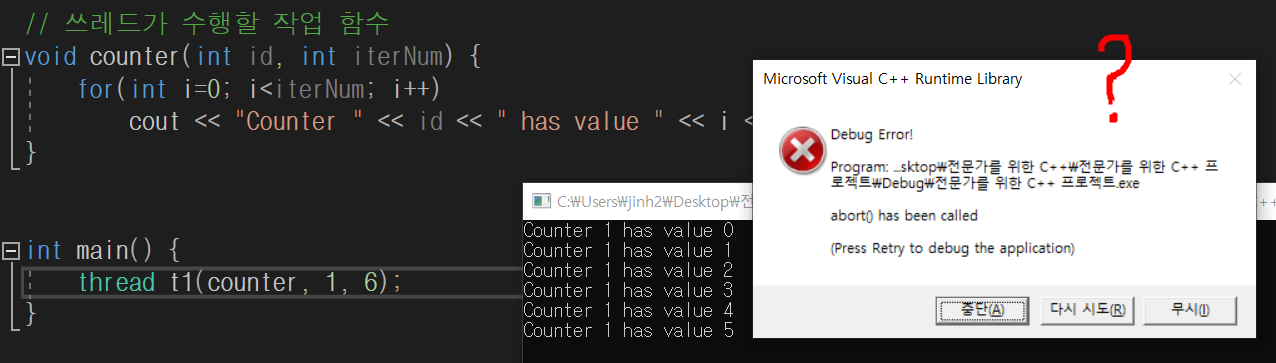
위 코드를 main에서 실행하면 abort() 함수가 호출된다.
C++ thread에서는 합류가능한 쓰레드가 있음에도 메인 프로세스가 종료되거나 thread 객체(callee)를 생성한 쓰레드(caller)의 함수가 반환되면 객체의 소멸자가 호출되면서 std::terminate()가 호출되기 때문이다. terminate()는 더이상 프로그램을 실행할 수 없다는 의미로 주로 비정상적인 상황이나 예외가 발생했을 때 호출된다.
// thread 객체 소멸자 슈도코드
~thread() nonexcept {
if(joinable()) {
_STD terminate(); // abort !!
}
}메인 쓰레드에 국한된 것이 아니라, 부모 쓰레드의 작업 종료가 자식 쓰레드의 작업 종료보다 앞설 때 발생한다.
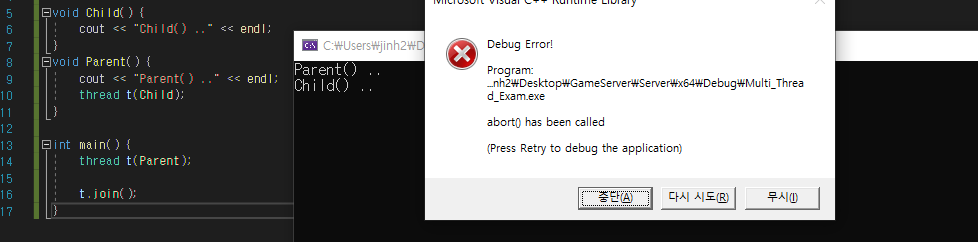
따라서 자식 쓰레드의 합류 가능 상태를 joinable() 함수를 통해 확인하고, 합류 가능 상태이면 join()을 호출하여 종료때까지 기다려야 한다.
void Parent() {
cout << "Parent() .." << endl;
thread t(Child);
if (t.joinable())
t.join();
}2. join()
단순히 쓰레드를 생성하기만 하고, 어떠한 제어를 하지 않으면 문제가 발생할 수 있다. 예를 들어 자식 쓰레드가 아직 구동 중인데 부모 쓰레드가 실행하는 메인 함수가 return 0;에 도달하여 프로그램이 종료되는 경우가 있다(기본적으로 메인 쓰레드가 종료되고도 자식 쓰레드가 계속 실행 중인 것은 비정상적 상황으로 봄. 강제로 오류를 발생시킴. abort()).
이러한 비정상적 상황을 막기 위해 join()을 호출하는 방식으로 제어를 할 수 있다. join()을 호출하면 (호출한)쓰레드는 블록(대기 상태)된다. 다시 말해 (실행)쓰레드가 작업을 끝낼 때까지 기다린다.
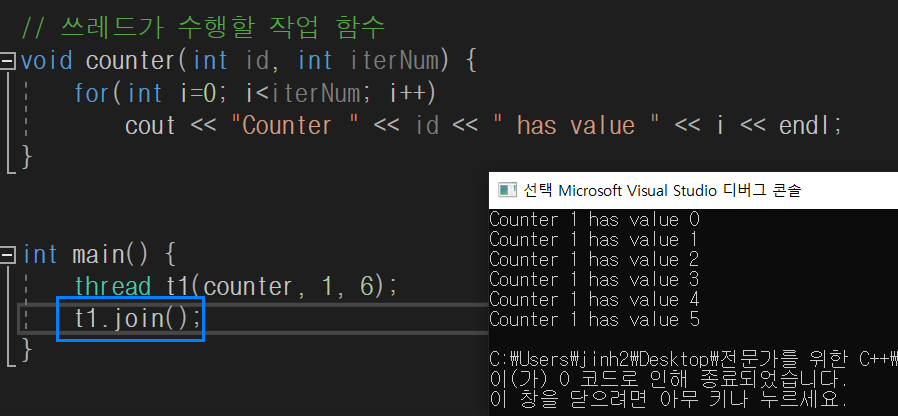
3. detach()
자식 쓰레드가 끝나기 전 부모 쓰레드가 끝나는 것이 의도적이라면 detach() 함수를 사용할 수 있다.
t1.detach();부모 쓰레드는 자식 쓰레드의 실행 또는 종료를 신경쓰지 않고 계속해서 진행해 나간다. 즉, 자식 쓰레드가 끝나기 전 부모 쓰레드가 먼저 끝날 수 있다는 것이다.
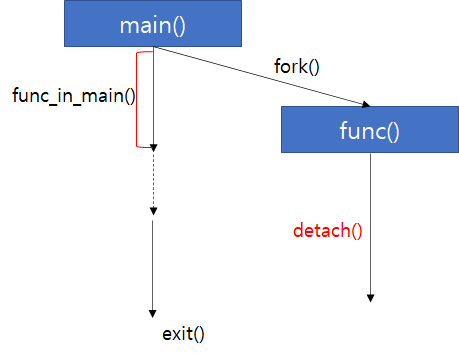
source: https://narakit.tistory.com/134
자식 쓰레드는 부모 쓰레드가 끝나도 계속해서 자신의 일을 진행할 수 있다(비정상적 상태로 간주하지 않고, abort() 함수가 호출되지 않음).
하지만 부모 쓰레드가 메인 쓰레드라면 프로그램 자체가 종료되는 것이기에 자식 쓰레드도 종료된다.
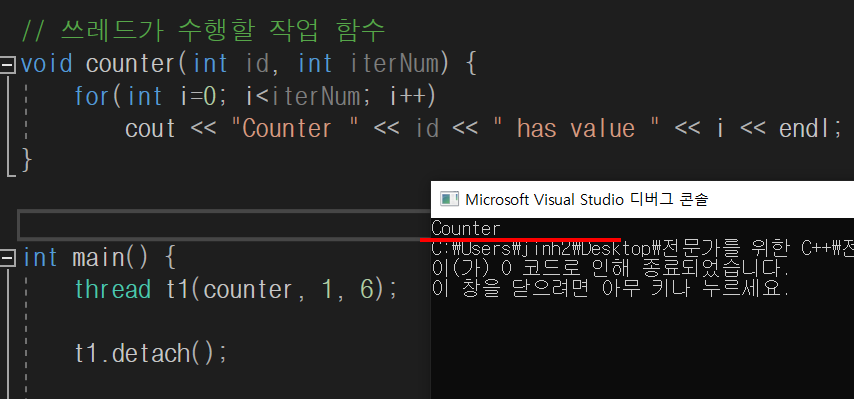
내부적으로 std::thread 객체와 실제 구동 쓰레드와의 연결고리를 끊는 것이다. 연결고리를 끊게되면 백그라운드 쓰레드로 독립적으로 수행하게 된다.
전통적으로 리눅스 환경에서 이렇게 객체와의 연결을 끊고 수행하는 것을 데몬(Daemon)이라고 한다.
std::thread 객체 변수로 제어를 할 수 없는 단점이 있다.
4. get_id()
쓰레드의 고유한 id를 반환한다.
작업을 할당받기 전에는 0을 반환하고, 작업을 할당받았을 땐 할당된 고유의 할당 번호를 반환한다.
std::thread t1;
// <1. get_id()>
// 쓰레드끼리의 고유한 id
auto id = t1.get_id();
cout << "작업을 할당받지 않은 쓰레드 id: ";
cout << id << endl;
// => 0 출력
t1 = std::thread(helloThread);
id = t1.get_id();
cout << "작업을 할당받은 쓰레드 id: ";
cout << id << endl;
// => 18636 출력
t1.join();
cout << "작업이 끝난 쓰레드의 id: ";
cout << t1.get_id() << endl;
// => 0 출력5. hardware_concurency()
현재 시스템의 가용 CPU 코어 갯수를 나타낸다.
auto cnt = t1.hardware_concurrency();
cout << "현재 시스템의 CPU 코어 갯수: ";
cout << cnt << endl;
// => 현재 시스템의 CPU 코어 갯수: 12example 코드
//#include <Windows.h>
#include <thread>
void helloThread() {
cout << "hello thread!!" << endl;
}
void helloThreadWithParam(int32 num, string s) {
cout << "hello thread!!" << " / num: " << num << ", s: " << s << endl;
}
int main() {
//::CreateThread(..);
// 윈도우즈 API (#include <Windows.h>)
// 그러나 코드가 리눅스 환경에서 실행되면 해당 API가 호출될 수 없다.
// C++ 11 부터 OS 종속되지 않고 쓰레드를 생성할 수 있게 끔 <thread> 헤더를 제공해준다.
// 어떤 환경이든 상관없이 공용적으로 사용할 수 있음
// 분기 쓰레드 작업
std::thread t(helloThread); // 메인 쓰레드에서 하나의 쓰레드가 분기해여 병렬적으로 수행
// 메인 쓰레드 => 메인 쓰레드, 분기된 쓰레드
// 또는 아래와 같이 할 수도 있다.
// std::thread t;
// ..
// ..
// t = std::thread(helloThread); // 쓰레드 객체 생성과 동시에 바로 작업을 할당시키지 않아도 된다.
// 실제 구동하는 쓰레드는 이때 생성된다.
// 변수만 선언할 경우 쓰레드 id는 0이다.
// vector<std::thread> vec(10);
// 벡터에 빈 객체 10개를 만들어주고,
// 실제 구동할 시 각 요소에 할당해주는 방식에 사용한다.
// 메인 쓰레드 작업
HelloWorld();
// <join()>
// 쓰레드 t가 끝나기 전에 메인 쓰레드가 먼저 끝나면 에러가 발생
// t 쓰레드를 기다리라는 코드가 포함되어야 함
t.join();
/* 그 외 많이 쓰는 쓰레드 관련 함수 */
std::thread t2;
// <get_id()>
// 쓰레드끼리의 고유한 id
auto id = t2.get_id();
cout << id << endl;
t2 = std::thread(helloThread);
id = t2.get_id();
cout << id << endl;
// <hardware_concurrency()>
// CPU 코어 개수
auto cnt = t2.hardware_concurrency();
cout << cnt << endl;
// <detach()>
// t.join()을 호출하면 메인 쓰레드는 쓰레드 t를 기다려 준다.
// 반면 t.detach()를 호출하면 만든 std::thread 객체와 실제 구동 쓰레드와의 연결고리를 끊는다.
// 연결고리를 끊게되면 백그라운드 쓰레드로 독립적으로 수행하게 된다.
// 전통적으로 리눅스 환경에서 이렇게 객체와의 연결을 끊고 수행하게 하는 것을 데몬(daemon)이라 한다.
// 하지만 이렇게 되면 t라는 std::thread 객체 변수로 제어를 할 수 없기에 잘 활용하지 않는다.
//t.detach();
// <joinable()>
// 실제 구동쓰레드가 존재하는지 여부를 체크한다.
// 쓰레드 변수만 선언하고 작업을 할당하지 않으면 실제 구동 쓰레드가 생성되지 않는다.
// 작업을 수행하지 않을 땐 false를 반환하고, 작업 수행 중에는 true를 반환한다.
if (t2.joinable()) {
cout << "t2 is joinable" << endl;
t2.join();
}
/* 수행 함수에 인자 전달 */
std::thread t3(helloThreadWithParam, 3, "WOW!");
if (t3.joinable())
t3.join();
/* 쓰레드 벡터 */
vector<std::thread> tVec(10);
for (int i = 0; i < 10; i++) {
tVec[i] = std::thread(helloThreadWithParam, i, "Wow~");
// 병렬로 수행
// 어떤 쓰레드가 먼저 수행될 지 모름
// 순서가 필요하다면 별도의 동기화 작업 필요
// cf)
//tVec[i].detach(); // 메인 쓰레드가 종료하면 에러는 발생하지 않지만, 프로그램 자체가 종료
// 참고로 이 for문 안에서 각각 쓰레드 구동과 동시에 join() 해주면 순서대로 출력됨
//if (tVec[i].joinable())
// tVec[i].join();
}
for (int i = 0; i < 10; i++) {
if (tVec[i].joinable())
tVec[i].join();
}
}