reference: "전문가를 위한 C++" / 마크 그레고리
아토믹 타입(atomic type)
아토믹 타입을 사용하면 동기화 기법을 적용하지 않고 읽기와 쓰기를 동시에(원자적으로) 처리하는 아토믹 접근(atomic access)이 가능하다.
아토믹 연산을 사용하지 않고 변수의 값을 변경(증가, 감소 등)시키는 것은 쓰레드에 안전하지 않다(non thread-safe). 컴파일러는 먼저 메모리에서 값을 읽고, 레지스터로 불러와서 값을 시킨 후 그 결과를 메모리에 다시 저장한다. 이 때 이 과정 중 같은 메모리 영역을 사용하는 다른 쓰레드가 건드리면 데이터 경쟁이 발생한다.
int num = 0; // 전역 변수
// 쓰레드 수행 함수
void increment() {
for(int i=0; i<10; i++) {
num++;
}
}위 increment 함수를 3개의 쓰레드가 수행하면 전역 변수 num은 300의 값을 갖게 될 것이다. 그러나 실제로는 데이터 경쟁이 발생하여 예상 아래의 값이 담길 수 있다.
이 변수(num)에 atomic type을 적용하면 뮤텍스 객체와 같은 기법을 따로 사용하지 않고도 쓰레드에 안전하게 만들 수 있다. 위의 코드를 아래의 코드로 고칠 수 있다.
atomic<int> num = 0; // 전역 변수
count ++;이를 통해 전역 변수에 데이터 경쟁이 발생하지 않도록 한다. 연산에서 실행되는 로드, 증가, 저장 기계명령어 처리가 원자적으로 일어나게 한다.
<atomic> 헤더 파일
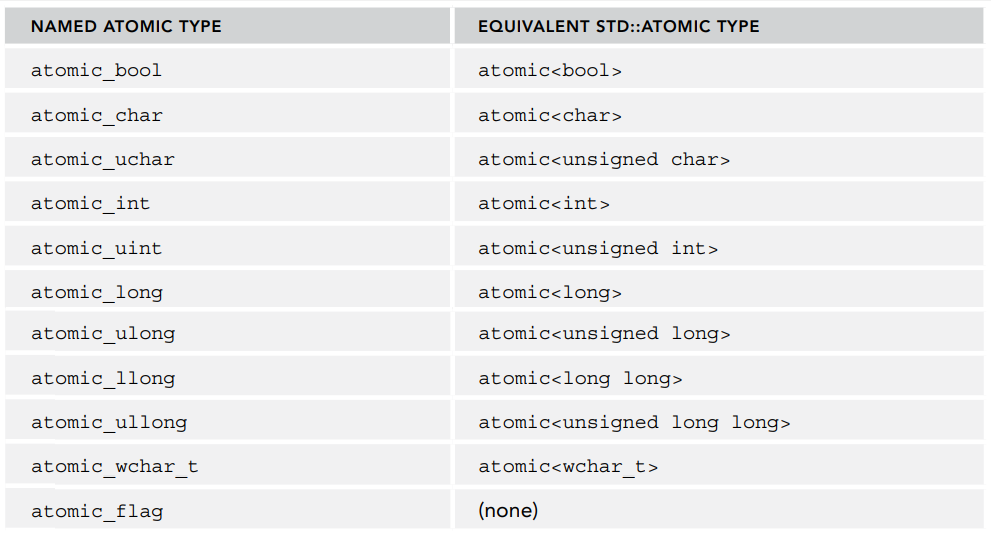
아토믹 타입을 사용하려면 <atomic> 헤더 파일을 포함하여야 한다. C++ 표준 언어에서 제공하는 모든 기본 타입마다 네임드(이름이 지정된) 정수형 아토믹을 정의하고 있다. 아래 표는 이 이중 일부를 나타낸 것이다.
source: https://junstar92.tistory.com/336
아토믹 타입 예제 1
#include <iostream>
#include <thread>
#include "Types.h"
#include <atomic>
using namespace std;
// 주소 공간의 Data 영역의 데이터
// 쓰레드끼리 해당 데이터를 공유할 수 있음
int32 SharedData = 0;
// atomic: All or Nothing
// 모던 c++에서 <atomic> 헤더 제공
// 플랫폼에 종속되지 않고 활용할 수 있음
atomic<int32> AtomicSharedData = 0; // atomic 타입 변수
void Add() {
for (int32 i = 0; i < 100'0000; i++) {
SharedData++;
}
}
void Sub() {
for (int32 i = 0; i < 100'0000; i++) {
SharedData--;
}
}
void AtomicAdd() {
for (int32 i = 0; i < 100'0000; i++) {
AtomicSharedData++; // == AtomicSharedData.fetch_add(1);
// CPU 딴에서 하나의 기계 명령어로 처리
// 일반 연산보다 비교적 느리므로 꼭 필요한 상황에서 쓴다.
}
}
void AtomicSub() {
for (int32 i = 0; i < 100'0000; i++) {
AtomicSharedData--; // == AtomicSharedData.fetch_sub(1);
}
}
int main() {
thread t1;
thread t2;
/* 원자성이 보장되지 않아서 발생하는 문제 */
t1 = thread(Add);
t2 = thread(Sub);
if (t1.joinable())
t1.join();
if (t2.joinable())
t2.join();
cout << SharedData << endl;
// => 50970
// 예상치 못한 결과 발생
// 이유는 문맥교환 상에서 원자성이 보장되지 않아서
/* atomic 타입 변수 활용 */
t1 = thread(AtomicAdd);
t2 = thread(AtomicSub);
if (t1.joinable())
t1.join();
if (t2.joinable())
t2.join();
cout << AtomicSharedData << endl;
// => 0 출력
}전역의 SharedData 변수를 동시 접근하는 Add(), Sub() 수행 쓰레드들에 의해 의도하지 않은 결과가 산출될 수 있다.
더하기, 빼기 연산이 원자적으로 이루어지지 않기 때문이다.
atomic 타입atomic<int32> 변수로 선언하여 원자적 연산을 강제할 수 있다.
아토믹 타입 예제 2 (참조형)
#include <atomic>
#include <thread>
#include <vector>
#include <iostream>
using namespace std;
void increment(int& counter) {
for (int i = 0; i < 100; i++) {
counter++;
this_thread::sleep_for(1ms);
}
}
int main() {
int counter = 0;
vector<thread> threads;
for (int i = 0; i < 10; i++) {
// threads.push_back(thread{ increment, counter }); // (X)
// 쓰레드 수행의 결과를 담을 변수에 대한 포인터나 레퍼런스를 쓰레드로 전달할 때
// std::ref()를 이용해서 레퍼런스를 thread 생성자에 전달해야 한다.
// std::ref는 주로 thread의 인자 또는 bind의 인자로 넘겨줄 때 사용한다.
threads.push_back(thread{ increment, ref(counter) }); // (O)
}
for (auto& t : threads) {
t.join();
}
cout << "Result = " << counter << endl;
}위 코드에서 increment 함수는 인수로 전달된 정수를 100번 증분시킨다. 이 increment 함수를 실행하는 쓰레드를 여러 개 뜨윈다면 counter 변수 하나를 여러 쓰레드가 공유하게 되는 것이다. 아토믹이나 쓰레드 동기화 메커니즘을 사용하지 않고 단순히 구현하면 데이터 경쟁(경쟁 상태)가 발생한다.
실제로 쓰레드 열 개를 실행시켜보았을 때 각각 동일한 counter 공유 변수에 대해 increment 함수를 실행시켜보면 1000이란 예상 결과가 아닌 다른 결과가 도출된다.
// 결과
try 1: Result = 953
try 2: Result = 930
try 3: Result = 933
아토믹 타입 적용을 통한 데이터 경쟁 회피
//void increment(int& counter) {
void increment(atomic<int>& counter) { // 아토믹 타입 적용
for (int i = 0; i < 100; i++) {
counter++;
this_thread::sleep_for(1ms);
}
}
int main() {
//int counter = 0;
atomic<int> counter(0); // 아토믹 타입 적용
vector<thread> threads;
for (int i = 0; i < 10; i++) {
threads.push_back(thread{ increment, ref(counter) });
}
for (auto& t : threads) {
t.join();
}
cout << "Result = " << counter << endl;
}// 결과
try 1: Result = 1000
try 2: Result = 1000
try 3: Result = 1000이와 같은 방식으로 뮤텍스와 같은 동기화 메커니즘을 추가하지 않고도 쓰레드에 안전하고 데이터 경쟁이 발생하지 않게 만들 수 있다. counter++ 연산을 하나의 아토믹(원자적) 트랜잭션으로 처리하여 중간에 다른 쓰레드가 개입할 수 없게 하는 것이다.
cf) 성능 향상을 위한 기법
아토믹이나 동기화 메커니즘을 사용할 때나 병렬성(Parallelism)이 낮아져 성능이 떨어질 수 있음을 부정할 수 없다. 몇가지 최적화 아이디어를 적용하여 병렬성이 낮아짐을 막으면서 데이터 경쟁을 피할 수 있게 할 수 있다.
예를 들어 위의 예제와 같은 경우 increment 함수의 증분 과정에서 공유 데이터 자체를 증분시키는 것이 아닌 각 쓰레드가 독립적으로 가질 수 있는 스택 공간, 즉 지역변수에 증분을 진행하고 최종적으로 공유 데이터에 적용하는 방식으로 최적화를 할 수 있다. 물론 마지막 공유 데이터에 적용하는 과정에서도 데이터 경쟁이 발생할 수 있으니 여전히 아토믹 타입으로 선언하여야 한다.
void increment(atomic<int>& counter) { // 아토믹 타입 적용
int localVal = 0;
for (int i = 0; i < 100; i++) {
//counter++;
localVal++;
this_thread::sleep_for(1ms);
}
counter += localVal;
}최적화 파트 참고: https://velog.io/@jinh2352/Optimization
