reference: 시스템 프로그래밍 수업 / 최종무 교수님
목차
- 최적화에 대한 개념
- 성능 표현 방법에 대한 이해
- CPU 독립 최적화 기법 <= 어느 CPU에서든 적용 가능하다.
- CPU 의존 최적화 기법 <= CPU 특성에 따라 다르다.
- 메모리 계층 구조와 성능 효과
Intro
최적화된 프로그램이란?
1) 문제 상황에 맞는 적절한 알고리즘과 자료구조을 선택한다.
ex) 주소록 프로그램의 검색 기능에 어떤 알고리즘을 도입할 것인가?
- linear search(선형 연결리스트): O(n)의 시간 복잡도 / 삽입에서는 O(1)
- (검색 최적화) 검색이 빈번하다면 이진탐색 알고리즘을 적용하거나(자료구조: 배열, 정렬된 상태 유지), 이진탐색 트리 자료구조를 이용하자. 다만 이진탐색 트리 자료구조를 사용할 시에는 삽입, 삭제에서 복잡할 수도 있다. O(logN)
- Key-Value 구조로 작성하여 Hash 알고리즘을 사용하자, O(1)의 시간 복잡도, 대신 구현이 복잡하고, 적절한 해시함수를 찾아야 한다.
=> 문제 상황에 맞게, 알고리즘/자료구조끼리의 Trade-off를 고려하여 적절한 것을 선택한다!
2) Divide a job into portions that can be computed in parrel! (ex, Map-Reduce Programming model in Google)
- parallelism, 한 시스템의 코어갯수를 고려하여 여러 쓰레드, 프로세스가 동시에 수행토록 구현한다. 작업을 나누는 Map 단계와 수행에서의 결과를 취합하는 Reduce 단계가 필요하다.
- 주소록의 예에서 T(테라)급의 요소들이 존재한다면, 배열을 분활하고 각 분활된 배열을 쓰레드 하나씩 맡아 검색을 진행하여 병렬적 수행을 할 수 있다. "병렬성 활용" => 실행 시간 단축
3) Generate an efficient <= 이번 포스팅 설명 내용
동일한 자료구조, 알고리즘, 동일한 병렬화 => 코드를 보다 더 효율적으로 작성한다!
a = a * 4; vs a = a << 2;위 두 코드 모두 결과는 같다. CPU 입장에서는 곱하기 연산이 쉬프트 연산보다 4~5배 정도 느리다. 곱하기는 multiplication. 쉬프트 연산은 integer 연산. interger 연산은 최근 CPU에선 거의 1클록에 수행. multiplication은 더 많은 클록이 필요.
for(i=0; i<10; i++){
a = 5;
b[i] = c[i] + a;
}위 코드에서 a = 5; 이 대입연산은 굳이 루프문 안에 있을 필요가 없다. 이를 뽑아낸다. "Code Motion" (cpu dependent optimization)
code motion: 반복문 안에 있을 필요가 없는 것을 반복문 밖으로 뺴내어 한번만 수행하도록 하는 테크닉
최적화 고려사항
-
Tradeoff 존재
: 최적화된 코드는 대게 가독성이 떨어질 수도 있다. 따라서 readability vs optimization 이라는 trade-off가 존재한다. -
Deeply CPU dependent
: CPU 내부 구조(이외 메모리 자원 구조까지)에 대한 이해가 필요하며, 어셈블리 레벨까지의 분석도 필요하다. -
Not straightforward!
: 약간의 변화로도 큰 성능 차이를 가져올 수 있지만, 명확한 기법이라도 큰 효율성을 가져오지 못할 수 있다. 즉 직관적인 결과를 기대할 수 없다.
프로그램 성능 표현
void vsum1(int n){
int i;
for(i=0; i<n; i++){
c[i] = a[i] + b[i];
}
}
void vsum2(int n){
int i;
for(i=0; i<n; i+=2){
// "loop unrolling" 기법 적용.
c[i] = a[i] + b[i];
c[i+1] = a[i+1] + b[i+1];
}
}CPE(Cycles Per Element)
예를 들어 a[10] => a[11]과 같이 하나의 요소가 늘어날 때마다 증가되는 사이클을 뜻한다.
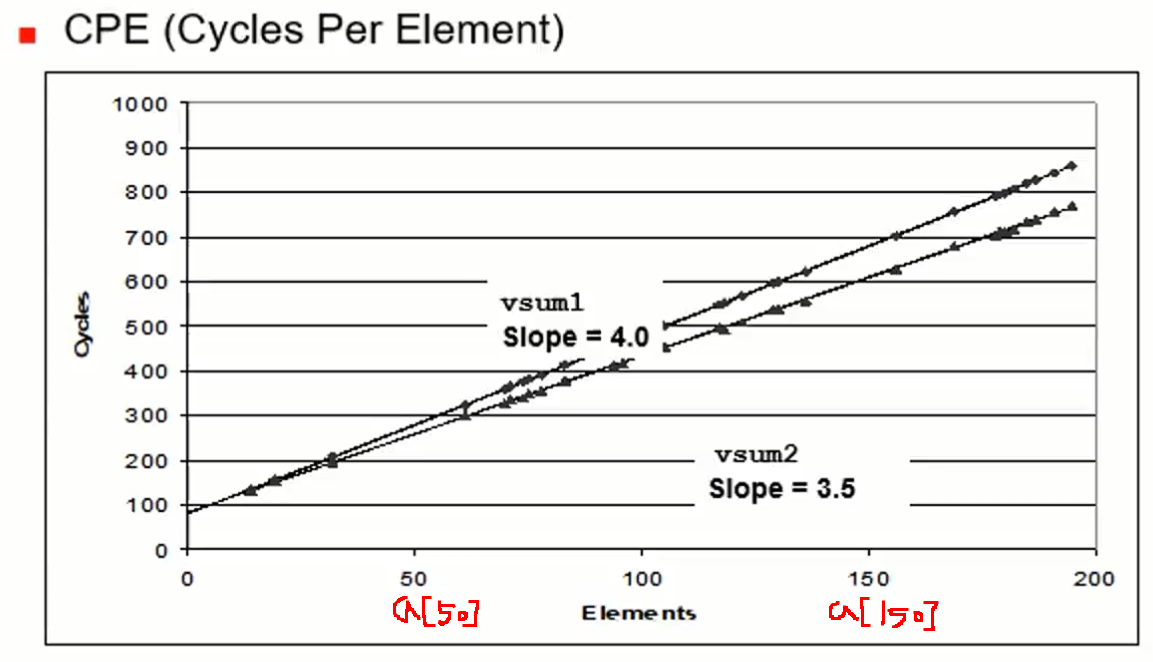
- loop-unrolling 개념을 적용하였을 때 CPE는 3.5로써 적용하지 않는 코드에 비해 CPE가 적음을 알 수 있다. -> 실행 시간 단축
- vsum1은 요소가 1개 증가할 때 마다 클록 사이클이 4증가, vsum2는 요소가 1개 증가할 때 마다 클록 사이클 3.5증가.
- 참고로, 선의 방적식은 'a least square fit mechanism'을 사용한다.
최적화 기법
Basic Program <= 6가지의 단계적 최적화 적용
Data type
typedef struct {
int len;
data_t *data; // data_t는 int or float
} vec_rec, *vec_ptr;
Procedures
- vec_ptr new_vec(int len)
- 전달한 len 길이의 벡터를 생성한다.
- int get_vec_element(vec_ptr v, int idx, data_t *dest)
- 벡터의 요소를 반환하고, *dest에 저장한다.
- out of bounds 시 0을 반환하고, 성공 시 1을 반환한다.
- int vec_length(vec_ptr v)
- 벡터의 길이를 반환한다.
- int *get_vec_start(vec_ptr v)
- 벡터의 start 포인터를 반환한다.
basic program
#include <stdlib.h> // NULL 메크로 사용
#include <stdbool.h>
#define data_t int // or float
// 사용 자료구조
typedef struct {
int len;
data_t *data;
}vec_rec, *vec_ptr;
// 사용 함수들 선언
vec_ptr new_vec(int len);
bool get_vec_element(vec_ptr v, int idx, data_t *dest);
int vec_length(vec_ptr v);
// 함수들 구현
vec_ptr new_vec(int len){
vec_ptr result = (vec_ptr)malloc(sizeof(vec_rec));
if(!result)
return NULL;
result->len = len;
if(len > 0){
data_t *data = (data_t*)calloc(len, sizeof(data_t));
/*
malloc과 calloc은 할당하고자 하는 메모리 크기를 바이트 단위로 할당받을 수 있는 함수.
malloc을 통해 할당받게 되면 기억공간의 값들은 쓰레기값으로 채워져있고,
calloc은 값들이 0으로 초기화되어 있다.
*/
if(!data){
free((void *)result);
return NULL;
}
result->data = data;
}
else{
result->data = NULL;
}
return result;
}
bool get_vec_element(vec_ptr v, int idx, data_t *dest){
if(idx < 0 || idx >= v->len)
return false;
*dest = v->data[idx];
return true;
}
int vec_length(vec_ptr v){
return v->len;
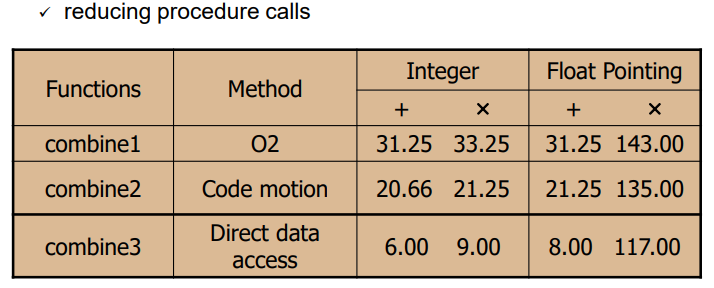
}combine1
void combine1(vec_ptr v, data_t *dest){
int i;
*dest = IDENT; // 0(덧셈) or 1(곱셈)
for(i=0; i<vec_length(v); i++){
data_t val;
get_vec_element(v, i, &val);
*dest = *dest OPER val;
}
// 수행 후 caller의 dest에 총합이 쓰여짐.
}(실험환경: 펜티엄 III, 펜티엄 III는 P6 마이크로 아키텍처를 가짐)

combine2: code motion을 통해 루프내 비효율적 동작 제거
앞서 루프 내 비효울적 대입연산(a=5)을 제거하는 code motion을 보였다. 마찬가지로 반복되는 함수 호출을 없앤다.
int length = vec_length(v);
// eliminating loop ineffcient(code motion)
// Reducing procedure calls
void combine2(vec_ptr v, data_t *data){
int i;
int length = vec_length(v); // 루프 안이라면 의미없는 함수 호출에 여러 번 일어남.
*dest = IDENT;
for(i=0; i<length; i++){
data_t val; // 블록 내에서 의미있는 지역변수를 선언한 것.
// 스택에 자리만 잡힐 뿐 루프 밖으로 배떠라도 성능은 동일
get_vec_element(v, i, &val);
}
}
combine3: combine3와 마찬가지로 반복적인 함수 호출을 줄인다.
data_t *data = get_vec_start(vec_ptr);
함수는 프로그램을 모듈화하기에 도움을 주지만, 호출의 오버헤드로 인해 성능 측면에선 나쁘다.
=> "may impair program modularity"
data_t* get_vec_start(vec_ptr){
return v->data;
}
void combine3(vec_ptr, data_t* dest){
int i;
int length = vec_length(v);
// 한번의 함수 호출
// 벡터의 시작 포인터를 먼저 빼놓아 함수 호출이 아닌, 포인터 연산을 통해 데이터를 가져온다.
data_t *data = get_vec_start(v);
*dest = IDENT;
for(i=0; i<length; i++){
*dest = *dest OPER data[i];
// 여러번의 get_vec_element() 메서드 호출을 줄인다.
/*
함수는 프로그램을 모듈화하기에 도움을 주지만, 호출의 오버에드로 인해 성능 측면에서 나쁘다.
*/
}
}
combine4: 불필요한 메모리 참조를 줄인다.
레이턴시가 긴 메모리 참조가 아닌 레지스터를 최대한 활용하도록 한다.
void combine4(vec_ptr v, data_t *dest){
int i;
int length = vec_length(v);
data_t *data = get_vec_start(v);
// 지역변수
data_t x = IDENT; // *dest = IDENT;
// 지역변수는 함수 내에서만 의미가 있다. 따라서 변수 x 공간을 메모리에 할당하지 않고 레지스터에 할당한다.
// 이에 메모리 접근이 감소할 것이다.
// 예를들어 eax 레지스터를 반복해서 사용할 것이다.
for(i=0; i<length; i++){
x = x OPER data[i];
}
// 마지막에 한번 결과를 반영해주면 된다.
*dest = x;
}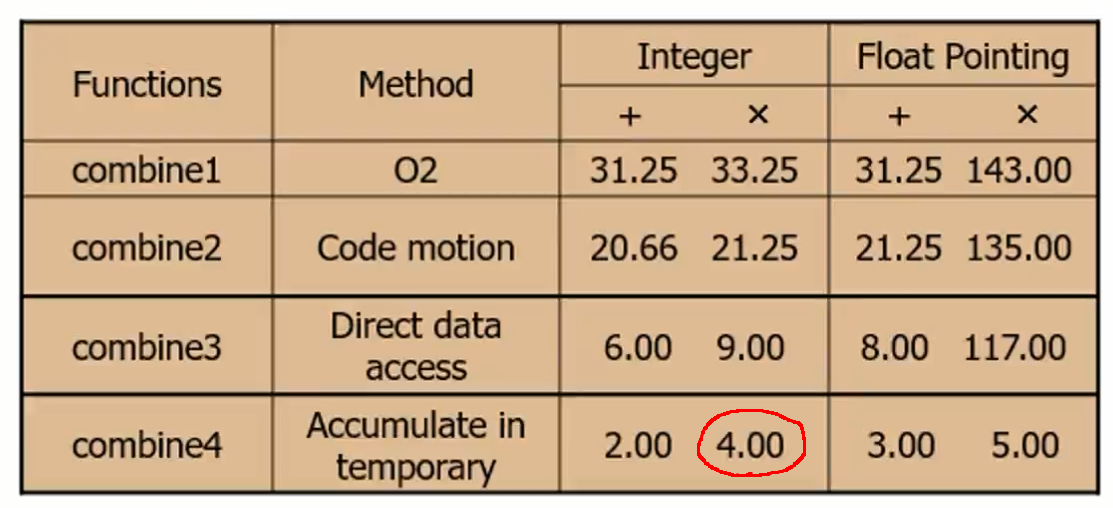
combine4 어셈블리 코드
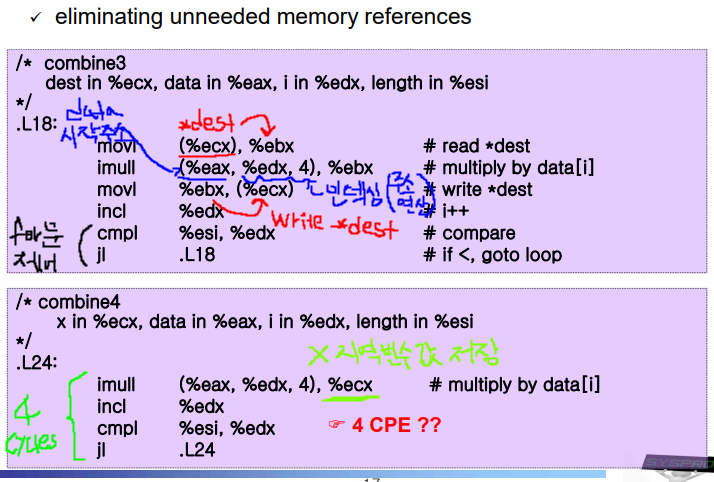
CPU 내부 구조 파악으로 4 CPE임을 확인하기.

overall features
- instruction control: fetch and decode (generates operations)
- execution unit: execute generate operations
addl %eax, %edx<= 하나의 명령어가 하나의 operation으로
addl %eas, 4(%edx)<= 하나의 명령어가 3개의 operation으로
여러 개의 functional unit이 있기에 각 operation들은 동시에 수행할 수 있다. - functional units
- Integer/Branch
- General Integer (정수형 연산은 동시에 2개의 유닛으로 처리 가능)
- Floating-Point Add
- Floating-Point Multiplication/Division
- Load
- Store
(이후의 버전들에선 더 많은 유닛들 존재)
- overall features
- Superscalar: 매 클록 사이클에 다중 operation들을 수행한다.
- Out-of-order(무순서 수행): the order in which instructions execute need not corresopnd to their ordering in the assembly program
- Branch prediction(분기 예측): guess whether or not a branch will be taken
- Speculative execution: commit execution when the prediction is proven as correct. otherwise, discard the results of the incorrect prediction(by retirement unit)
- Register renaming: values passed directly from one functional unit to another / data hazard로 인한 stall 방지에 도움을 준다.
(각 functional unit의 latency, issue time)
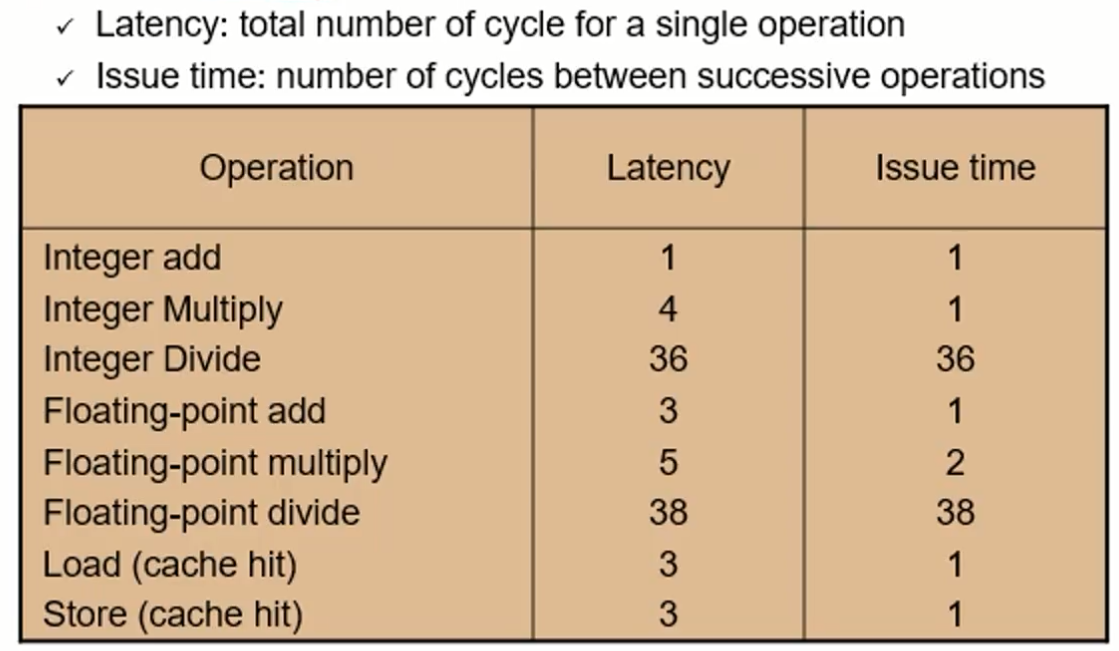
- latency와 issue time의 차이는 곧 파이프라인 구현이 가능하다는 뜻이다! (can be pipelined!)
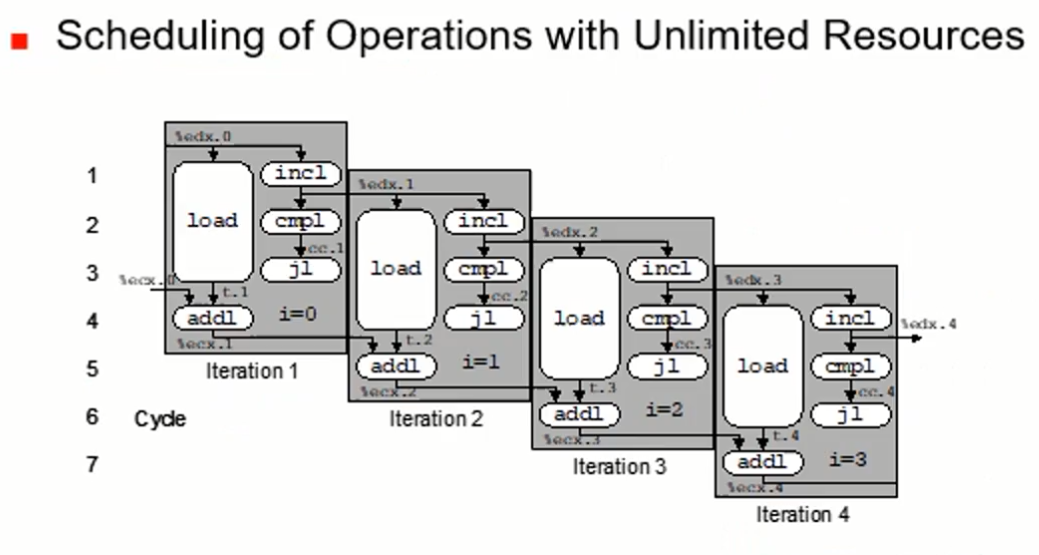
위의 정보들을 바탕으로 4 CPE를 계산해본다.

4개의 instruction은 5개의 u-operation들로 쪼개져 수행된다.
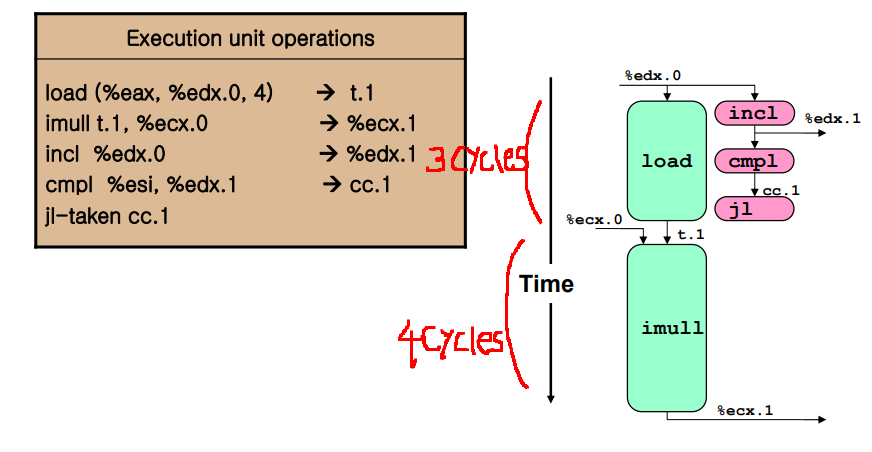
- 여러 개의 functional unit이 있기에 그림에서 볼 수 있듯 load, incl, cmpl 등 병렬 수행이 가능하다. (data dependency 없는 경우, load연산과 mull 연산에는 dependecy가 있다.)
- 한번의 루프에서는 7 사이클이지만, CPE는 아래 그림을 통해 4임을 확인할 수 있다.
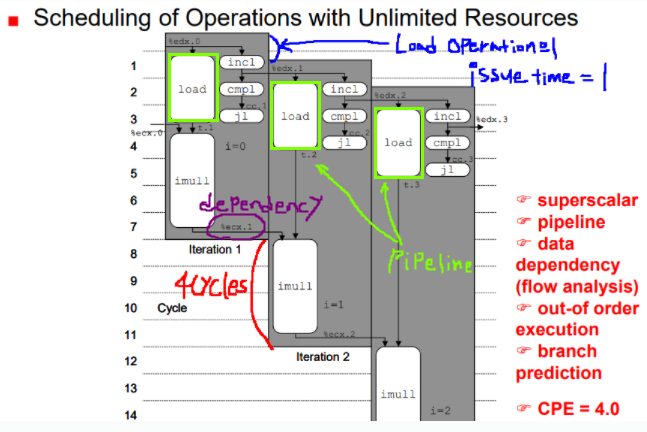
- ecx 레시스터에는 변수 x(sum)의 값이 들어있다.
- imull 연산도 파이프라인이 가능하지만 data dependency로 인해 순차 수행이 된다.
- iteration1/2/3가 순차가 아닌 거의 병렬 수행이 이루어진다. out-of-order 실행이 적용된 것이다.
- jl(작으면 점프)하는 분기문이 끝나야 다음 for문이 수행되어야 하지만, 그림으로 확인할 수 있듯 iteration1/2/3는 그러지 않다. 분기 예층으로 실행하고, 나중에 그 결과를 취하는(taken) 방식을 사용한다.
(추가로 더하기 연산시에는 CPE가 2가 된다.)
(예전 Intel CPU 기준 unit의 제약)

자원이 무한힐 떄,