reference: https://pages.cs.wisc.edu/~remzi/OSTEP/, 시스템 프로그래밍, 운영체제 수업(최종무 교수님)
Consistency definition in File System
일관성: valid state -> valid state
- changes in a file system are guaranteed from a valid state to another valid state
- 비일관된 상태의 예로, 파일이 실제로 할당된 데이터라 할 지라도 비트맵이 해당 블록을 free 블록이라 지칭한 경우.
- 파일 생성 도중 system off -> inconsistent state 발생 가능.
solution: "FSCK(File System Check)" / "Journaling" / "others(COW, Integrity checking..)"
파일에 append 작업만 해도 inode 변경, 데이터 블록 추가, 비트맵 변경 등이 수반된다. 이 과정 중 일부 단계에서 문제가 발생하면 일관된 상태가 깨질 수 있다. 모든 작업의 원자적 수행을 보장해야 한다.
Crash scenario(문제 상황 가정)
Delayed write using cache => 급작스러운 전원 off and system crash => Some writes can be done while others are not!
Three writes: 데이터 블록, 아이노드, 비트맵
-
데이터 블록만 쓰이는 경우: 문제 없음.
-
비트맵만 수정되는 경우: space leak 발생.
-
아이노드만 수정되는 경우: 1) garbage read, 2) inconsistency: inode vs bitmap
-
데이터 블록과 비트맵만 쓰여지는 경우: inconsistency(사실상 space leak, inode가 없으므로 접근하지 못함.)
-
데이터 블록과 아이노드만 쓰여지는 경우: inconsistency
-
아이노드와 비트맵만 쓰여지는 경우: garbage read

=> Need Consistency: write all modifications or nothing! (a kind of atomicity)
Solution 1. FSCK(File System Check)
Too Slow... (will update post soon..)
solution 2. Journaling
- WAL(Write-ahead logging)의 일종 : 쓰기 전에 무언가를 기록
- Key idea: first write down a little note to somewhere in a well-known location, describing what you are about to do.
- crash occur: Redo if Undo (atomicity)
- ext3 file system
: Integrate journaling into ext2 file system
: Three types: 1) journal (data journal), 2) ordered (metadata journal, ordered, default), 3) writeback (metadata journal, non-ordered)

Journaling 종류
(inode, bitmap, data blocks write 가정)
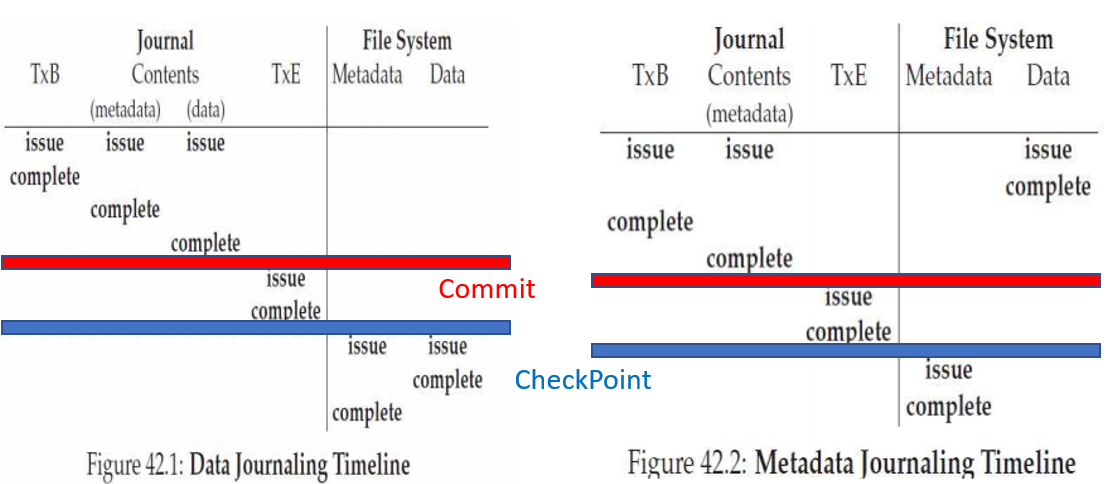
1. Data Journaling
step 1) Jounaling: Before writing them to their final locations, we first write them to the log

(1) TxB: Transaction begin, include Tid and writes information
(2) Log: (보통 Physical logging) same contents to the final locations
(3) TxE: End with Tid
step 2) Checkpointing: After making this transaction safe on disk, we are ready to update the original data
step Recovery(fault handling))
- In the case of failures btw journaling and checkpointing, we can replay journal (redo) -> can go into the next consistent state
- In the case of failures btw TxB and TxE, we can remove journal (undo) -> can stay in the previous consistent state
How to reduce journaling overhead? -> 1. performance
=> employ commit (커밋 프로토콜)
-
TxE(Transaction End) for all other writes (ex, fsync() before TxE)
-
Recovery: (1) not committed -> undo, (2) committed, but not in the original locations -> redo logging

commit before TxE
How to reduce journaling overhead? -> 2. write volume
데이터 저널링의 문제점: writes data twice, which increases I/O traffic(reducing performance), especially painfull for sequential writes
=> Metadata Journaling
2. Metadata Journaling
- Journal Metadata Only
- User data is not written to the journal (I and B, except D)

- User data is not written to the journal (I and B, except D)
- 메타 데이터보다 유저 데이터가 먼저 쓰여지는 것이 낫다. 유저 데이터만 쓰여지는 것은 큰 문제가 아님.
=> Ordered journaling
1) Data write -> 2) Journal metadata write -> 3) Journal commit -> 4) check point -> 5) free
- Timeline (Data Journaling vs Metadata Journaling(non-ordered))