source: Operating Systems: Three Easy Pieces
Remzi H. Arpaci-Dusseau and Andrea C. Arpaci-Dusseau (University of Wisconsin-Madison)
https://pages.cs.wisc.edu/~remzi/OSTEP/file-lfs.pdf
(Original paper: M. Rosenblum and J. Ousterhout, "The Design and Implementation of a Log-Structured File System", ACMToCS)
1. Introduction
- 메모리가 커져감에 따라 더 많은 데이터가 메모리 상으로 캐시될 수 있다. read 작업은 캐시 상에서 주로 이루어져 감에 따라 디스크의 트래픽은 점점 더 write 작업으로 이루어지고, 파일 시스템의 성능은 write 성능에 큰 영향을 받게 된다.
- random I/O 성능과 sequential I/O 성능간의 갭: 하드디스크 상의 seek time과 rotational delay time 감소는 HDD의 bandwidth 증가만큼 급격하지 않았다. 따라서 디스크를 순차적 방식으로 접근하는 것이 성능 향상에 큰 효과를 누릴 수 있다.
- Fast File System의 문제점: 비록 탐색 시간과 회전 지연 시간을 고려하여 설계된 FFS라 할 지라도, FFS 또한 많은 짧은 탐색 시간과 회전 지연 시간을 유발한다. (a large number of writes to create a new file)
- one for a new inode
- one to update the inode bitmap
- one to the directory data block that the file is in)
- one to the directory inode to update it
- one to the new data block (the file)
- one to the data bitmap to mark the data block allocated
이상적인 파일시스템 write 성능에 초점을 맞추어야 한다. 그리고 HDD의 구조를 감안하여 순차적 쓰기를 활용하는 것이 좋을 것이다. 그리고 이는 단순히 데이터 쓰기 작업 뿐 아니라 빈번한 메타데이터 수정 작업에서도 좋을 것이다.
위 논문(Original paper)에서 소개된 LFS(Log-structured File System)는 위 아이디어를 기반으로 설계되었다. 디스크의 write 작업에서 LFS는 메타데이터를 포함한 모든 갱신을 먼저 메모리에 존재하는 '세그먼트(segment)' 공간에 버퍼 작업을 수행한다. 그리고 세그먼트가 꽉 찰 때 비로서 디스크에 write를 하고, 순차 쓰기 방식으로 디스크의 사용하지 않는 공간(unused part)에 쓴다. LFS는 절대 기존 데이터에 over-write 하지 않으며, 언제나 세그먼트 상의 데이터를 디스크의 빈 공간에 쓴다.
2. Writing to Disk Sequently
(시나리오)
새로운 데이터 블록 D를 파일에 쓴다. (디스크 주소 A0에 write)

메타데이터인 inode 갱신, 데이터 블록 옆에 write를 하고 inode는 데이터 블록을 가리킴.
(대부분의 파일시스템에서 데이터블록의 크기는 4KB, inode 크기는 128, 256B임을 감안)
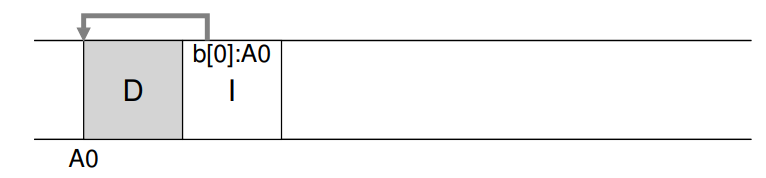
모든 갱신 write 작업을 디스크 상에 순차적으로 하는 것이 LFS의 근본적인 아이디어이다.
3. Writing Sequently and Effectively
LFS가 사용하는 고전적인 기술인 'write buffering'은 디스크 회전에서 기인하는 비효율적 쓰기를 방지한다. 구체적으론 세그먼트라는 in-memory 공간에 모든 업데이트를 먼저 쓰고, 그 세그먼트를 한번에 디스크에 쓰도록 한다.
The mechanism that enables large writes to disk in LFS
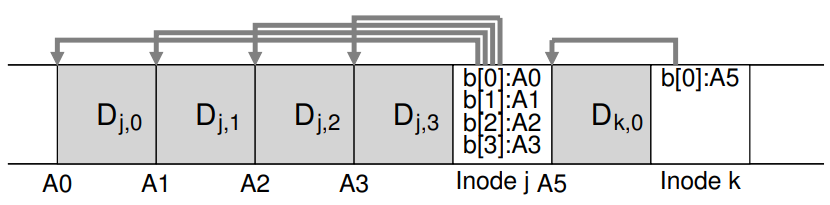
위 그림에서 두 가지 업데이트 후 결과가 되는 디스크 레이아웃이다. LFS는 두 업데이트를 한 세그먼트에 동시에 버퍼 작업을 수행한다. 첫 번째 업데이트는 file J에 4개의 데이터블록을 write하는 것이고(inode 갱신 포함), 두 번째는 하나의 블록을 file K에 더하는 것이다. 이 후 LFS는 7개의 데이터 블록이 포함된 세그먼트를 디스크에 한번에 커밋한다.
4. Finding inodes
기존의 UFS나 FFS와 같은 파일시스템에서 inode를 찾는 것은 큰 문제가 없다. 디스크 상에 고정된 위치에 inode들이 존재하기 때문이다. 그러나 LFS에서는 inode들은 디스크 상에 산개되어있다.(LFS에서의 write 방식을 살펴보면 지당함.) 더욱이 기존 데이터에 overwrite 하지 않은 특성에 기인되어 마지막 갱신 버전의 inode가 매번 위치를 달리하는 것도 inode를 찾는 것에 문제를 준다.
Solution: The inode Map
LFS는 inode finding 이슈를 inode map(imap)이라 불리는 자료구조를 통해 'inode numer'와 'inode'를 간접적으로 연결한다. imap을 통한다면 inode 번호를 입력으로 하여 가장 최근에 갱신된 inode의 디스크 주소를 구한다. 4바이트의 디스크 포인터를 담을 요소로 이루어진 배열로써 구현될 수 있다.
디스크 상에 inode가 새로 써질 때 마다 imap에는 새로운 위치가 매번 갱신된다.
(writes the new data block, its inode, and a piece of the imap all together onto disk)
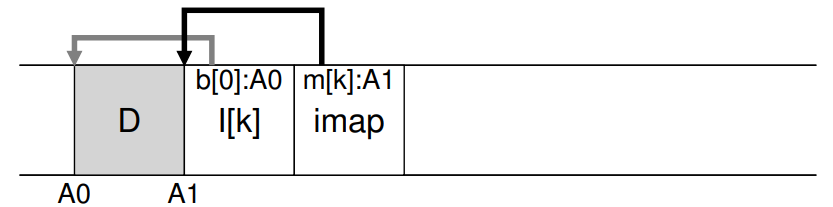
5. How do we find the inode map -> Completing the solution: The Checkpoind Region
파일 lookup을 위해 파일시스템은 어쩔 수 없이 고정되고 알려진 공간이 필요하다. LFS는 checkpoint region(CR)이라는 고정적인 공간을 가진다. CR은 가장 최근의 imap 조각들을 가리키는 포인터들을 담는다. 따라서 CR을 먼저 읽음으로써 imap 조각은 읽혀질 수 있다.
CR의 경우 매 30초 정도에 주기적으로 갱신되어 성능은 크게 하락되지 않는다.
(the overall structure of the on-disk layout)
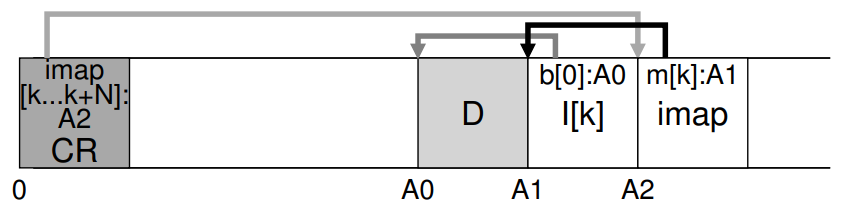
- A checkpoint region: points to the latest pieces of the inode map
- The inode map pieces: each contain addresses of the inodes
- the inodes point to files (and directories) just like typical UNIX file systems.
- in a real file system, a much bigger CR, many imap chunks, and of course many more inodes, data blocks, etc.
6. Reading a File from Disk
(메모리에 캐시된 것이 없다 가정)
1. Read CR, CR은 전체 imap을 가리키는 포인터들이 존재.
2. 전체 imap을 읽고, 메모리 상으로 캐싱한다. => 이 후 imap 탐색은 메모리 상에서 이루어질 수 있다.
3. 찾고자 하는 파일의 inode 번호를 찾고, imap을 통해 맵핑된 주소를 읽는다. 그리고 최신의 inode를 읽는다.
4. 이 지점부터 UFS와 동작이 같다. inode 자료구조의 direct 또는 indirect 포인터를 읽고 실제 데이터 블록을 찾아가 읽는다.
</br?
7. What about Directories?
실제 파일에 접근할 때 해당 파일을 담은 디렉터리를 먼저 접근할 가능성이 크다.
UFS와 같이 디렉터리는 '파일 이름'과 'inode 번호'의 쌍으로 있는 디렉터리 엔트리들의 컬렉션인 파일일 뿐이다.
가정: /home/jinh/foo (파일 이름: foo, inode 번호: k)
foo라는 이름의 파일을 디렉터리에 생성하는 것은 다음과 같은 디스크 레이아웃을 이끈다.
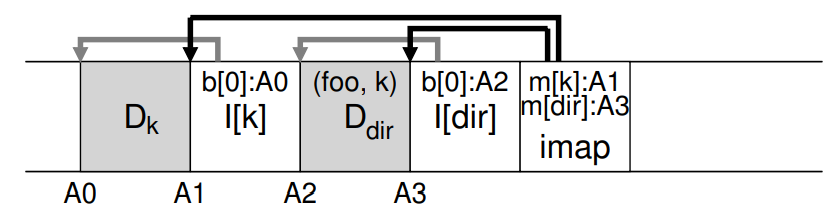
위 그림의 한 조각의 imap은 디렉터리와 파일에 대한 위치정보를 담고있다. 따라서 foo 파일에 접근할 땐 다음과 같은 순서를 거친다.
1. look in the inode map(usally cached in memory)
2. find location of the inode of dir (A3)
3. read directory inode -> the location of the directory data block (A2)
4. read directory data block -> the name-to-inode number ->
5. consult imap again with inode number -> the location of inode number k (A1)
6. d finally
read the desired data block at address (A0)
8. Garbage Collection
LFS는 디스크 상 새로운 공간에 파일의 마지막 버전(inode, data)을 쓴다. 쓰기 작업을 효율적으로 하기 위한 것이지만, 이전 버전의 파일 구조들이 디스크 상에 흩어져 저장되는 문제가 발생한다. 이전 버전들을 garbage라 한다.
(가정)
inode 번호가 k인 inode가 있고, 이 inode가 가리키는 디스크 블록 D0이 디스크 상에 연속된 공간에 있다 가정한다. 이 후 이 데이터 블록에 갱신이 발생하고 디스크 상에 새로운 데이터 블록과 inode가 생성되었다(물론 같은 파일에 해당). 아래 그림과 같은 디스크 레이아웃을 보일 것이다. (imap은 생략, 새로운 imap 조각또한 새로운 inode 옆에 생성될 것이다.)
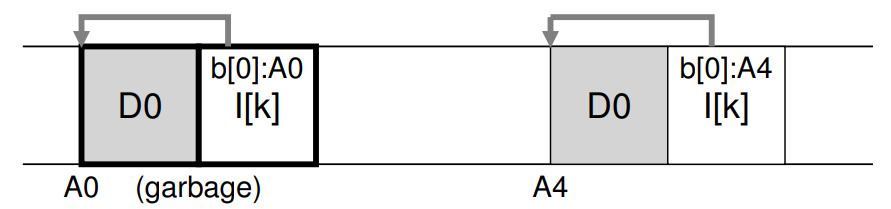
LFS의 write 정책에 기인하여 왼쪽에 old 버전의 데이터 블록과 inode가 있고, 오른쪽이 new 버전의 데이터 블록과 inode가 있는 상황이다.
다른 버전으로 기존 파일에 새로운 데이터 블록을 추가(append)할 때 디스크 레이아웃은 다음 그림과 같다.
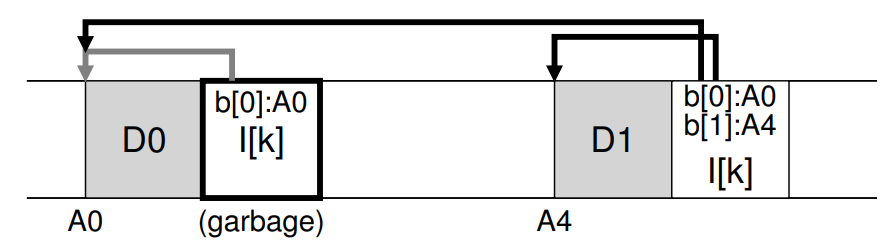
오른쪽 inode가 새로 추가된 데이터 블록까지 가리키는 new 버전의 inode이다.
LFS는 'versioning file system'과 다르게 old 버전의 데이터 블록이나 inode를 유지시키지 않는다. LFS는 주기적으로 old dead 버전의 데이터 블록, inode 또는 다른 자료구조를 찾아 지운다. 지워진 블록들은 다른 순차 쓰기를 위한 공간이 된다. LFS에서 지우기 프로세스는 'garbage collection'의 형태로 이루어진다.
앞부분에 언급된 large writting을 위한 segment 단위는 지우기 작업의 단위이기도 하며, 이는 효과적인 지우기 작업에서 결적적 역할을 한다. 만약 파일 시스템이 segment 단위가 아닌 하나의 블록 또는 inode 단위로 지우기를 수행한다면 많은 수의 free hole들을 발생시킬 수 있으며 이는 곧 쓰기 성능에 까지 악영향을 줄 수 있다. LFS에서 쓰기는 연속적인 큰 공간을 필요로 하기 때문이다.
이에따라 LFS에서는 write와 마찬가지로 segment 단위의 지우기 작업을 수행하며, 이 후 큰 단위의 연속적인 쓰기 작업이 효과적으로 이루어 질 수 있게 하는 것이다.
- The basic cleaning process
주기적으로 LFS cleaner는 old segment(partially-used)들을 읽고 segment의 어떤 블록들이 살아있는지 파악한다(determines live blocks). 그리고 live blocks들만 존재하는 segment에 덧씌운 다음 해당 old segment를 새로운 쓰기 작업을 위해 사용되도록 한다.
M개의 old segment가 있고, 그들의 live contents들을 N개의 세그먼트에 compact한다. 이 후 M개의 old segment들은 이 후 파일 시스템의 순차 쓰기를 위해 free된 상태가 된다.
So how can LFS tell which blocks within a segment are live, and which are dead? and how often should the cleaner run, and which segments should it pick to clean?
9. Determining Block Liveness
LFS는 각 세그먼트 안 블록들의 live / dead 상태를 판단하기 위해 세그먼트 헤드에 'segment summary block'이란 자료주고에 정보를 기입한다. 구체적으로는 데이터 블록이 속한 파일의 inode number와 offset(which block of the file this is).
예를 들어 데이터 블록 D가 디스크 상 주소 A에 있다 가정하자, 해당 블록이 존재하는 세그먼트의 segment summary block을 읽고, inode 번호 N과 파일의 offset T를 찾는다. 이 후 imap을 찾고, inode 번호 N에 해당하는 inode를 찾는다. 그리고 해당 inode를 읽고 offset T를 이용하여 T번째 블록의 위치를 검색한다. 이 때 검색된 블록의 위치가 이전 데이터 블록 D의 위치 A와 같다면 데이터 블록 D는 live 블록으로 판단되는 것이고, 아니면 dead 블록이다. 이런식으로 block의 liveness를 판단한다.
// Determining Block Liveness (pseudo code)
(N, T) = SegmentSummary[A];
inode = Read(imap[N]);
if (inode[T] == A)
// block D is alive
else
// block D is garbage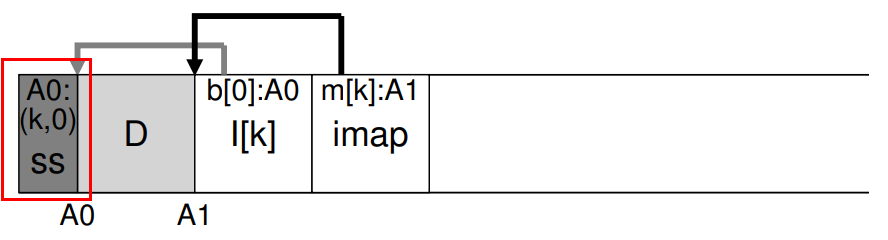
LFS는 위와 같은 복잡한 프로세스말고 간단한 shortcut을 취하기도 한다. 그 중 하나가 'version numbering'이다.
