GFS(Google File System) papaer 요약
source: https://static.googleusercontent.com/media/research.google.com/ko//archive/gfs-sosp2003.pdf
GFS's Architecture
GFS 클러스터는 하나의 마스터와 다수의 청크서버(chunkservers)로 구성되어 있다. 각 각은 평범한(commodity) 리눅스 머신일 뿐이다.
source: https://ko.wikipedia.org/wiki/%EA%B5%AC%EA%B8%80%ED%8C%8C%EC%9D%BC%EC%8B%9C%EC%8A%A4%ED%85%9C
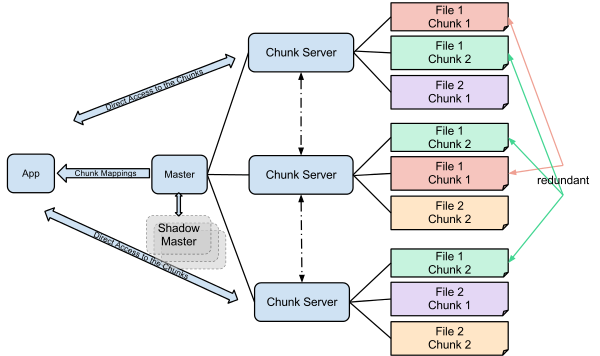
파일은 고정된 크기인 청크 단위로 나누어 저장된다. 각 청크는 불변의 전역으로 고유한 64비트의 '청크 핸들(chunk handle)'로 식별될 수 있고, 이는 청크가 생성될 때 마스터로부터 부여받는다.
각 청크는 청크서버의 로컬 디스크에 리눅스 파일에 저장되고, 데이터는 청크 핸들과 바이트 범위로 식별될 수 있다. 그리고 이를 통해 읽기 또는 쓰기 작업을 한다.
Reliability를 위해 각 청크는 여러 청크서버에 복제된다. 기본적으로 세 개의 복제본을 생성하여 저장한다.
마스터는 모든 파일 시스템의 메타데이터를 메모리에 유지한다. 이 메타데이터는 파일 네임 스페이스(name space), 접근 제어 정보, 파일과 청크의 매핑 정보, 청크의 위치 등을 말한다. 또한 마스터의 역할은 청크 리스 관리, 가비지 컬렉션, 청크 마이그레이션과 같은 시스템 전반의 활동을 제어하는 것이다.
마스터는 주기적으로 청크서버와 명령을 내리거나 상태 정보 등을 받는데 이는 '허트비트(heartbeat)'를 통해 교신한다.
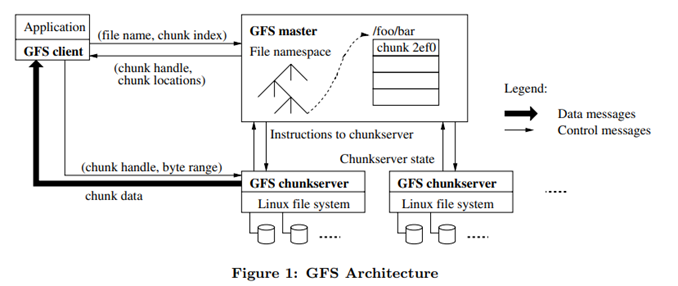
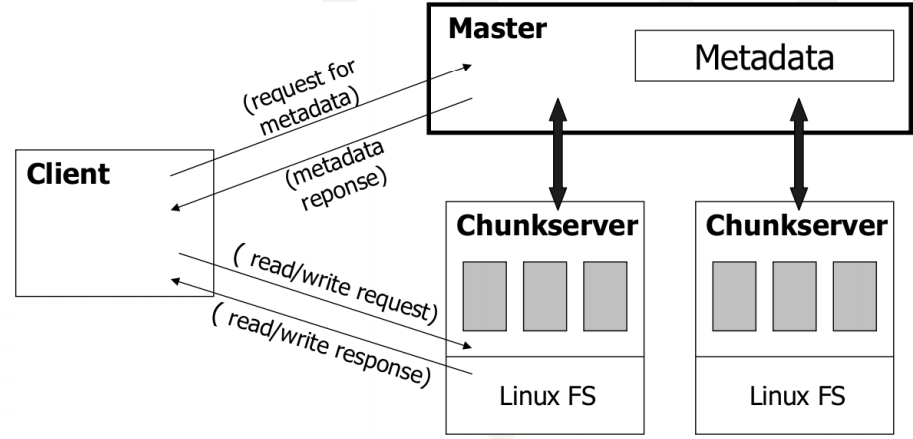
GFS 아키텍처에서 클라이언트는 마스터와 메타데이터 오퍼레이션을 위해 상호작용을 하지만, 모든 데이터 읽기 또는 쓰기 작업은 청크서버와 소통을 하여 이루어진다.
Single Master
클러스터 내 단일의 마스터를 배치하는 것은 GFS의 디자인을 간단하게 만들며, 이 마스터는 정교한 청크 배치나 복제 결정등을 수행한다. 그러나 단일의 마스터와의 교신에서 발생할 수 있는 병목(bottleneck)을 줄이기 위해 데이터 읽기와 쓰기에서의 개입은 하지 않는다. 앞서 설명한대로 클라이언트는 결코 마스터로부터 데이터를 읽거나 쓰는 작업을 하지 않으며, 마스터에게 메타데이터(예를 들어 자신의 작업을 수행하기 위해 어떤 청크서버에 접근해야되는지와 같은 정보)를 받은 후, 이를 캐싱하여 청크서버와 직접적으로 교신을 한다(interacts with the chunckservers directly for many subsequent operations).
디테일한 인터렉션 방식은 본 논문 2.4절 참고
https://static.googleusercontent.com/media/research.google.com/ko//archive/gfs-sosp2003.pdf
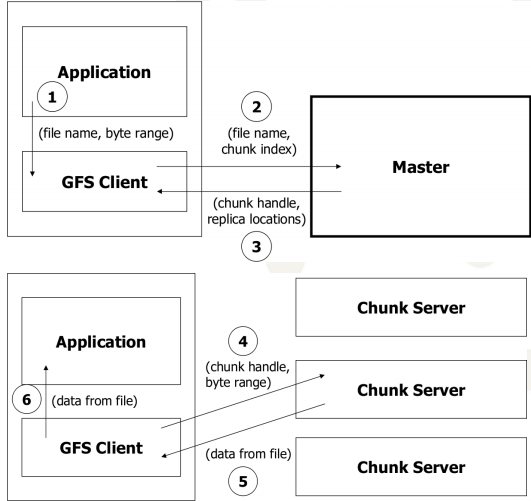
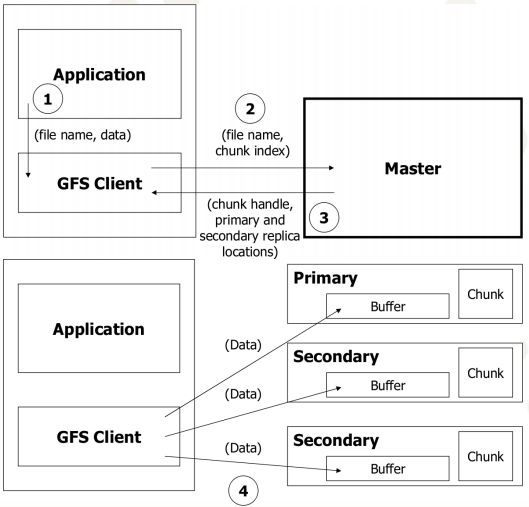
(1) Architecture
source: https://www.uio.no/studier/emner/matnat/ifi/INF5100/h10/undervisningsmateriale/gfs.pdf
(2)Read Operation
(3) Write Operation
Chunk Size
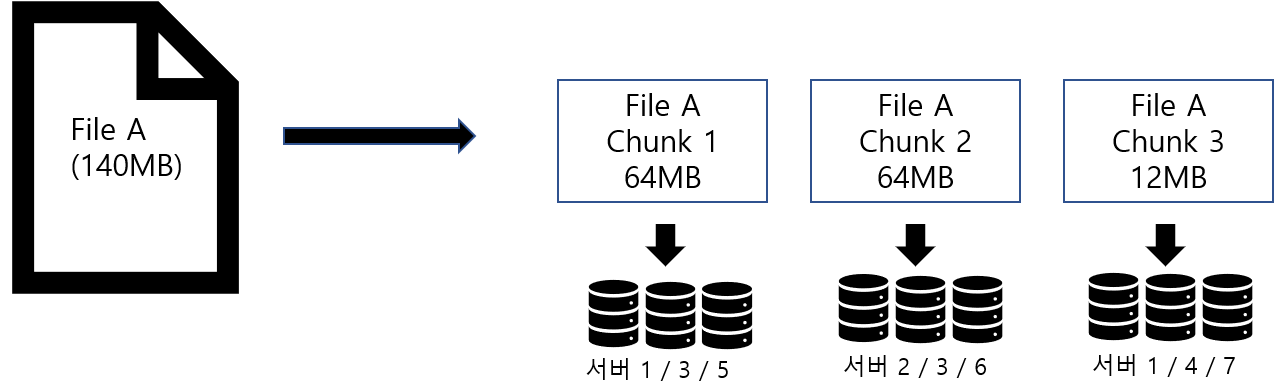
GFS에서 제시한 기본 청크 사이즈는 64MB이다. 이는 일반적인 파일 시스템의 블록 사이즈보다 크다. 큰 청크 사이즈는 내부 단편화로 기인되는 공간 낭비를 줄일 수 있다. 이 뿐아니라 큰 청크 사이즈는 여러 중요한 이점들을 가져다 준다.
먼저 클라이언트-마스터 통신을 줄여준다. 같은 청크에 대한 읽기와 쓰기에 있어 단위가 클수록 자연스레 초기 요청의 응답으로부터 오는 메타데이터가 큰 데이터를 아우르기 때문이다. 반대로 말하면 청크 사이즈가 큰 만큼 마스터에서 저장하는 메타데이터의 크기를 줄일 수 있다는 것도 장점이다.
또한 구글의 에플리케이션 워크로드 관찰에 있어 큰 파일에 대한 순차적 읽기, 쓰기가 빈번하였기 때문에 큰 청크는 이러한 워크로드에도 유리하다.
반면 큰 청크 사이즈는 반면 단점도 존재한다. 많은 클라이언트들이 하나의 파일 청크에 접근하여 '핫스팟(hot spot)'이 될 수 있다.
하지만 이 또한 큰 문제는 되지 않는게 구글의 에플리케이션들은 대부분 거대한 멀티 청크 파일을 순차적으로 읽기 때문이다.
Metadata
마스터는 세 종류의 메타데이터를 저장한다.
(1) 파일과 청크의 네임 스페이스
(2) 파일과 청크의 매핑 정보
(3) 각 청크 복제본의 위치
모든 메터데이터는 마스터의 메모리에서 유지된다.
네임스페이스와 파일-청크 매핑 정보의 경우 변화(mutation)가 생길 시 마스터가 로깅하면서 유지된다. 이 작업 로그(operation log)는 마스터의 로컬 디스크에 저장되고 원격의 머신에 복제된다.
이 로그를 사용하면 마스터의 충돌 시 발생하는 불일치 위험없이 안전정으로 마스터의 상태를 업데이트할 수 있다.
마스터는 청크 위치정보를 영속적으로 가지고 있지 않다. 대신 마스터의 startup시 청크서버와의 통신을 통해 청크에 대한 정보를 받는다.
In-Memory Data structures
메타데이터는 마스터의 메모리에 저장되기에 마스터의 동작은 작업은 빠르다. 또한 마스터가 주기적으로 전체 상태를 효율적으로 스캔하는 것이 가능핟. 이 주기적인 스캔을 통해 마스터는 시스템 전반에 대한 제어를 동작시킨다. 예를 들어 가비지 컬렉션이나 청크 재복제, 청크 마이그래션 등이 있다.
한가지 의문점이 들 수 있다. 이러한 memory-only 접근에 있어 전체 시스템이 마스터의 메모리 크기로부터 제약을 받을 수 있지 않을 까이다. 하지만 이건 실제로 큰 문제는 아닌 것이 마스터는 64MB의 청크에 대한 메타데이터를 64바이트 이하의 크기로 유지한다. 대부분의 파일은 많은 청크를 포함하고, 단지 마지막 청크가 부분적으로 채워졌을 뿐이다. 마찬가지로 파일 네임스페이스 데이터 또한 64바이트 미만으로 각 파일이 유지된다.
Chunk Locations
네임스페이스, 파일-청크 매핑 정보에 대한 작업 로그는 마스터의 로컬 디스크에 영속적으로 저장되는 반면 복제본이 있는 청크서버에 대한 레코드는 영속적으로 저장하지 않는다. 대신 마스터의 시작 시 해당 정보를 위해 청크서버를 폴링한다.
이 후 마스터는 청크 배치와 청크서버의 상태를 허트비트 메시지를 통해 지속적으로 업데이트한다.
이러한 방식은 마스터와 청크서버 사이의 Sync(synchronization)를 유지해야하는 수고를 덜어준다.
Sync as chunkservers join and leave the cluster, change names, fail, restart, and so on. In a cluster with hundreds of servers, these events happen all too often.
(GFS paper 2.6.2절 참고)
Operation Log
작업 로그는 결정적인 메타데이터 변화에 대한 기록을 포함한다. 메타데이터에 대한 유일한 영구 레코드일 뿐 아니라 동시적인 작업의 순서를 정의하는 논리적 타임라인 역할도 한다. 파일 및 청크는 모두 고유하며 생성되었을 때의 논리적 시간에 의해 식별된다.
작업 로그는 중요하므로 안정적으로 저장해야 하며, 메타데이터 변경이 영속적이어질 때까지 클라이어트에게 보이지 않게 한다. 로컬 및 원격의 디스크에 해당 로그 레코드를 플러시한 후에만 클라이언트의 작업에 응답한다.
마스터는 이 작업 로그를 자시 재생함으로써 파일 시스템 상태를 복구하는데, 시작 시간(startup time)을 최소화하기 위해서 로그를 작게 유지한다.
by checkpoints concept
(GFS paper 2.6.3절 참고)
추가로 이 로그를 작성하는 중에서도 에러가 발생할 수 있는데, 복구 코드는 자동으로 불완전하게 종료된 로그들을 무시하여 데이터 무결성을 유지한다.
Consistency Model
GFS는 고도로 분산되어 있는 애플리케이션을 잘 지원하면서 동시에 구현이 비교적 간단하고 효율적인 방식으로 유지되는 완환된 일관성 모델을 갖추고 있다.
이번 파트에선 GFS의 게런티(guarantees)와 애플리케이션에서의 의미를 설명한다. GFS가 어떻게 이러한 게런티를 유지하는지 간단히 언급한다.
파일 네임스페이스의 변경(ex. 파일 생성)은 원자적이다. 이것은 전적으로 마스터에 의해 수행되며, 네임스페이스 'locking'은 원자성과 정확성을 보증한다. 마스터의 작업 로그는 이러한 작업의 전체 순서를 정한다.
데이터 변화(mutation) 후 파일 영역(file region)의 상태는 변화의 유형, 성공 또는 실패 여부, 동시 변화가 있는지 여부에 따라 달라진다. 유형에 따른 변화의 결과는 아래 표와 같다.
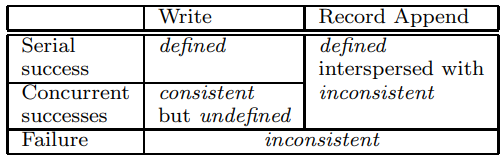
몇 가지 상황을 나누어 살펴보자면,
(1) 만약 모든 클라이언트가 언제나 같은 데이터만을 읽는다면, 어떤 복제본을 읽는지와 상관없이 파일 영역은 일관될 것이다.
(2) 파일 데이터가 변화되고, 이것이 일관적이라면 해당 파일 영역은 'defined' 상태가 되고, 클라이언트들은 변화를 통해 전체에 쓰여진 내용을 볼 수 있다.
(3) 동시 작성자(concurrent writers)로부터 같은 파일 영역에 간섭없이 변화가 성공한다면, 해당 영역의 상태는 마찬가지로 'defined' 상태가 되며, 또한 마찬가지로 모든 클라이언트들은 그 변화를 볼 수 있다.
(3vs4) 그러나 동시에 성공한 변화는 영역을 defined 하지않고, 다만 consistency 상태로 남긴다. 이는 모든 클라이언트는 같은 데이터를 볼 수 있지만, 어떤 변화에 의해 쓰여진 것을 반영하지 못할 수 있다.( it may not reflect what any one mutation has written) 일반적으로 이러한 변화는 여러 변화의 혼합 조각(mingled fragments)로 구성된다.
(5) 실패한 변화는 해당 영역을 비일관된 상태(inconsistency)로 만든다(and alse undefined). 따라서 서로 다른 클라이언트는 다른 데이터를 다른 시간 때마다 읽게 된다.
데이터 변화는 'write'와 'record append'가 있다. 쓰기의 경우 애플리케이션이 명시한 파일 오프셋에 데이터를 쓰는 것이고, append의 경우 원자적으로 데이터가 appended하게 한다. 일반적인 append의 경우 클라이언트가 생각하는 파일의 끝 부분 offset에 추가된다. 반면 record append operation의 경우 GFS가 선택한다. 선택된 오프셋은 클라이언트로 반환되고, 레코드를 포함하는 정의된 영역의 시작을 표시한다.
일련의 변화를 성공적으로 마친 후 변화된 파일 영역은 'defined' 상태로 보장되며, 마지막 변화에 의해 쓰여진 데이터를 포함한다. GFS는 모든 변화를 동일한 순서로 청크에 적용하면서 보장한다. 그리고 청크 버전 번호를 사용하여 'stale'한(오래된) 상태의 복제본을 탐지하는데, stale 상태란 청크서버가 다운되면서 변화를 적용하지 못하게 된 상태를 뜻한다.
stale 복제본은 변화 속에서 돌연변이에 관여되지 않거나 청크 위치를 요청하는 클라이언트에 제공되지 않는다. 이러한 복제본은 가능한 빨리 가비지 컬렉트된다.
