GFS 디자인에서 마스터의 모든 작업안 개입은 최소화되도록 설계되었다. 이번 장은 클라이언트, 마스터, 그리고 청크서버 간의 상호작용에서 어떻게 마스터의 개입은 최소화되며, 이 상호작용을 통해 데이터의 변화(mutation), 원자적 레코드 append, 그리고 스냅샷 오퍼레이션이 어떻게 실현되는지 묘사한다.
Lease and Mutation Order
변화는 청크의 유저 데이터나 메타데이터를 바꾸는 작업(write or recode append)이고, 모든 청크 복제본에 적용되어야 한다. 따라서 복제본들을 거쳐 일관된 변화 순서(consistent mutation order)를 적용하기 위해 리스(lease, 임대)라는 것을 사용한다.
마스터는 'primary'라 불리는 복제본 중 하나에 청크 리스를 부여한다. primary 복제본은 청크에 대한 모든 변화에 대한 일련의 순서를 선택하게 되고, 모든 복제본들은 변화를 적용할 때 이 순서를 따른다.
따라서 전역의 변화(global mutation) 순서는 먼저 마스터가 선택한 리스 부여 순서에 따라 정의되며, primary로부터 할당된 일련의 번호에 의해 정의된다.
이러한 리스 메커니즘은 마스터의 관리 오버헤드를 최소화하기 위해 설계되었다.
만약 마스터가 primary와의 통신을 잃게 된다해도 새로운 리스를 다른 복제본에 부여함으로써 해결되고, 이전의 리스는 만료된다.
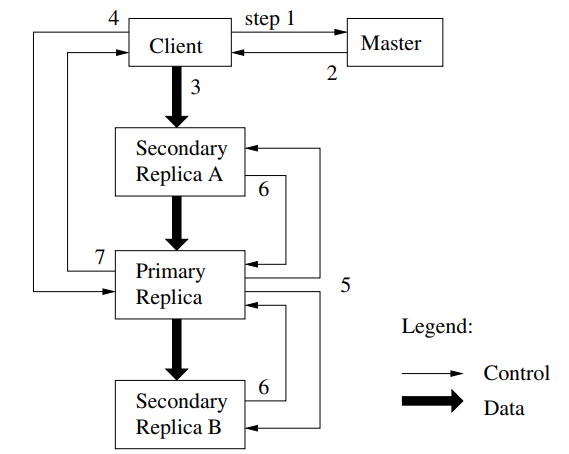
아래 그림은 write 시 제어 흐름을 따라 그린 것이다.
-
클라이언트는 마스터에게 청크에 대한 현재 리스를 보유하고 있는 청크 서버와 다른 복제본의 위치를 요청한다. 만약 해당 리스가 존재하지 않는다면 마스터는 하나의 복제본에 리스를 부여한다.
-
요청을 받은 마스터는 프라이머리의 identity와 다른 복제본의 위치를 전달한다. 클라이언트는 이를 캐싱하고 이 후의 변화(mutation)에 활용한다.
-
클라이언트는 모든 복제본에 데이터를 푸시한다. 어떤 순서든 수행한다. 그리고 각각의 청크서버는 해당 데이터를 내부의 LRU 버퍼 캐시에 데이터가 사용되거나 aged out 될 때까지 저장한다.
전반적인 과정에서 데이터 흐름과 제어 흐름을 나누면서 성능을 향상시킨다. 어느 청크가 primary인지 상관없이 네트워크 토폴로지(topology)를 기반으로 비교적 비싼 비용의 데이터 흐름을 스케줄링하여 성능을 개선시킬 수 있다.
-
모든 복제본이 데이터 수신을 승인하면 클라이언트는 primary 복제본에 쓰기 요청을 보낸다. 이 요청은 모든 복제본에 이전에 푸시된 데이터를 식별한다.
primary 복제본은 필요한 일련(serialization)을 제공하는 주 여러 클라이언트에서 수신되는 모든 변화에 일련의 번호를 할당한다. 이것은 일련의 번호 순 안에서 자신의 로컬 상태에 변화를 적용시킨다. -
primary는 이 후 write 요청을 모든 다른 복제본들에 포워딩시킨다. 각 복제본들은 primary로 부터 부여받은 같은 일련의 번호 순 하에 변화를 적용시킨다.
-
변화 적용이 끝난 복제본들은 다시 primary에게 작업 완수를 알린다.
-
primary는 최종적으로 클라이언트에게 응답한다. (에러 처리 생략)
애플리케이션에 의한 쓰기가 크거나 청크의 경계에 걸치는 경우 GFS 클라이언트 코드는 이를 여러 쓰기 작업으로 나눈다. 모두 위에서 설명한 제어 흐름을 따르지만 다른 클라이언트의 동시 작업으로 interleave 되거나 덮어써질 수 있다. 개별 작업이 모든 복제본에서 동일한 순서로 성공적으로 완료되므로, 복제본이 동일하더라도 공유 파일 region은 다른 클라이언트의 조각(fragment)를 포함할 수 있다.
Data Flow
앞서 네트워크를 효율적으로 사용하기 위해 데이터 흐름과 제어 흐름을 나누었다 하였다. 제어 흐름이 클라이언트 -> primary -> 나머지 복제본들 순으로 흘러간다면, 데이터 흐름은 파이프라인 방식으로 신중하게 선택된 청크서버 체인을 따라 선형적으로 푸시된다. 이를 통해 각 시스템의 네트워크 대역폭(bandwith)을 최대한 활용하고, 네트워크 병목 현상과 고도로 연결된 링크(high-latency link)를 방지하며, 모든 데이터를 푸시하는 지연 시간(latency)를 최소화한다.
자세한 흐름은 DFS paper 3.2절 참고
Atomic Record Appends
GFS는 record append라는 원자적 append 오퍼레이션을 제공한다. 전통적인 쓰기에선 클라이언트는 데이터가 쓰여질 오프셋을 명시한다. 이 경우 같은 region에 동시적 쓰기는 serializable하지 않게 되고, 해당 region은 결국 다수의 클라이언트로부터 인해 데이터 조각들을 포함하게 될 것이다. 그러나 record append에선 클라이언트는 오직 데이터만 명시한다. 그리고 이 데이터를 파일에 append 하는데 마스터가 선책한 오프셋에 원자적으로 진행된다. 그리고 이 오프셋이 클라이언트에게 반환되는 것이다. 이 작업은 마치 Unix에서 다수의 쓰기 작업에서 기인하는 경쟁 상태(race condition)없이 O_APPEND 모드로 열린 파일에 쓰기 작업을 하는 것과 비슷하다.
이 record append 작업은 서로 다른 머신의 다수의 클라이어트가 동일한 파일에 동시적으로 쓰는 작업이 빈번한 구글의 분산 애플리케이션에 정말 많이 사용된다.
보통 클라이언트는 추가적으로 복잡하고 비용이 높은 동기화 작업이 필요하지만, GFS에선 파일은 다수 생산자-단일 소비자 큐의 역할을 한다.
record append 또한 일종의 변화이며 위 그림에서 보인 제어 흐름을 따르며, primary 딴에서 약간의 추가적인 로직이 필요할 뿐이다. 클라이언트는 파일의 마지막 청크의 복제본들에 데이터를 푸시하고, primary에 요청을 보낸다.
요청을 받은 primary는 appending 작업이 청크의 최대 사이즈(64MB)를 넘는지 확인하고, 만약 넘는다면 추가적인 작업을 수행한다.
Snapshot
스냅샷 오퍼레이션은 진행중인 변화에 대한 인터럽션을 최소화하면서 파일 또는 디렉터리 트리의 복사본을 거의 즉각적으로 만드는 작업이다.
스냅샷 오퍼레이션은 전형적인 copy-on-write 기술을 사용하여 구현되었다. 마스터가 스냅샷 요청을 받을 때 먼저 마스터는 해당 청크들에 대한 리스를 철회시킨다. 이것은 차후의 쓰기 작업이 마스터에게 다시 리스를 찾도록 만드는 보장이다. 또한 마스터가 해당 청크에 새로운 복사본을 만들도록 한다.
리스들이 철회되거나 만료되면 마스터는 해당 작업을 디스크에 로깅한다. 이 후 원본 파일 또는 디렉터리 트리의 메타데이터를 복제하여 이 로그 레코드를 메모리 내 상태에 적용한다.
새로 생성된 스냅샷 파일이 원본 파일과 동일한 청크를 가리킨다.
스냅샷 작업 후 클라이언트가 처음으로 청크 C에 쓰기를 할 때 마스터에게 현재 리스 홀더를 찾기 위한 요청을 보낸다. 마스터는 청크 C에 대한 참조수가 1개보다 크다는 것을 인식한다(스냅샷 작업 후). 클라이언트 요청에 대한 응답을 연기하고, 대신 새 청크 핸들 C'를 선택한다. 이 후 C의 현재 복제본이 있는 각 청크서버에 새 청크를 만들도록 요청한다.
원본(C)이 존재하는 청크서버에 새 청크(C')를 만들어 데이터를 네트워크를 통해서가 아닌 로컬로 복사할 수 있다. 이 시점부터 요청 처리는 모든 청크에 대한 요청 처리와 다르지 않다. 마스터는 복제본 중 하나에 새 청크(C')에 대한 리스를 부여하고 클라이언트에 응답한다. 클라이언트는 기존 청크(C)에서 방금 생선된 것을 모르고 청크를 정상적으로 쓸 수 있다.
