Google File system paper - (4) Master Operation
마스터는 모든 네임스페이스 오퍼레이션을 수행한다. 그리고 시스템 전반에 거쳐 청크 복제본을 관리한다. 배치 결청, 새로운 청크와 청크 복제본 생성, 그리고 모든 청크서버에 거친 부하 조절, 사용하지 않은 스토리지 회수 등과 같은 다양한 시스템 활동을 조절한다.
Namespace Management and Locking
대다수의 마스터 오퍼레이션은 시간이 오래 소비될 수 있다. 예를 들어 스냅샷 작업은 스냅샷에 포함된 모든 청크에 대해 리스를 철회해야 한다. 실행 중인 다른 마스터의 작업을 딜레이 시키지 않게 하기 위해서 여러 오퍼레이션을 활성화하는 동시에 네임스페이스 영역에 잠금(lock)을 사용해 적절한 serialization을 보장한다.
대부분의 기존 파일 시스템과 달리 GFS는 해당 디렉터리의 모든 파일을 나열하는 디렉터리별 데이터 구조를 가지고 있지 않다. 또한 동일한 파일 또는 디렉터리에 대한 별칭(Unix 용어로 하드링크 또는 심볼 링크라 한다.)을 지원하지 않는다. GFS는 전체 경로 이름을 메타데이터에 매핑하는 조회 테이블로 해당 네임스페이스를 나타낸다. 접두사를 압축함으로써 이 테이블을 메모리에 효율적으로 나타낼 수 있다.
네임스페이스 트리의 각 노드(절대 경로의 파일 이름 또는 디렉터리 이름)에는 관련 읽기-쓰기 (lock)이 있다.
각 마스터 오퍼레이션은 동작 전 잠금들을 얻는다. 일반적으로 만약 /d1/d2/../dn/leaf 파일이 포함된다면, 디렉터리 이름 /d1, /d1/d2, ... , /d1/d2/../dn에 대해 읽기 잠금을 얻게되고, /d1/d2/.../dn/leaf에 대해선 읽기와 쓰기 잠금을 얻는다(leaf는 작업에 따라 파일이 될 수 있고, 디렉터리가 될 수 있다. 해석에 따라 적절히 판단.).
이 잠금 메커니즘을 통해 /home/user가 /save/user에 스냅샷으로 생성되는 동안 /home/user/foo 파일이 생성되는 것을 방지할 수 있는 예시를 보이면 다음과 같다.
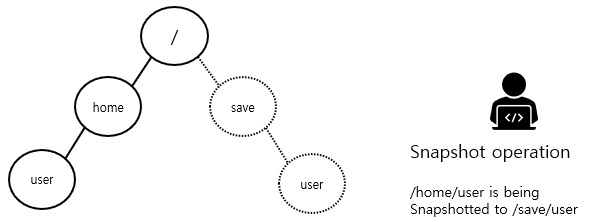
스냅샷 작업은 /home 과 /save 디렉터리에 대해 읽기 잠금을 획득하고, /home/user 와 /save/user 에 대해 쓰기 잠금을 획득한다.
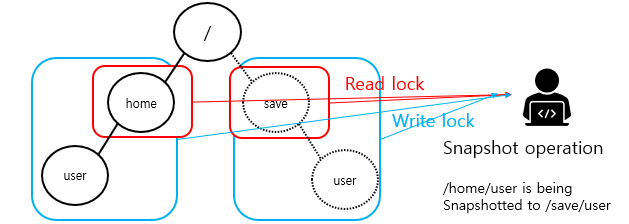
파일 생성의 경우 /home과 /home/user에 대해 읽기 잠금을 얻고, /home/user/foo 에 대해 쓰기 잠금을 얻는다.

위 두 오퍼레이션은 /home/user에 대한 충돌하는 잠금을 얻으려 하기에 올바르게 serialization 된다. 수정으로부터 보호할 디렉터리 또는 inode와 유사한 데이터 구조가 없기에 파일 생성 오퍼레이션은 상위 디렉터리에 대한 쓰기 잠금이 필요하지 않다. 이름에 대한 읽기 잠금은 상위 디렉터리를 삭제하지 못하도록 보호하기에 충분하다.
이 잠금 메커니즘의 장점 중 하나는 동일한 디렉터리에서 동시 변화를 허용한다는 것이다. 예를 들어, 여러 개의 파일 작성을 동일한 디렉터리에서 동시에 수행할 수 있다. 각각의 디렉터리 이름에 대한 읽기 잠금과 파일 이름에 대한 쓰기 잠금을 획득하는데, 디렉터리 이름에 대한 읽기 작금은 디렉터리가 삭제되거나, 이름이 변경되거나, 스냅샷이 생성되지 않도록 하는데 충분하다.
파일 이름에 대한 쓰기 잠금은 동일한 이름의 파일을 두 번 만들려는 시로들 serilazation하게 한다.
네임스페이스에는 여러 개의 노드가 있으므로 읽기-쓰기 잠금 개체가 느리게 할당되고 사용되지 않으면 삭제된다. 또한 잠금은 교착 상태를 방지하기 위해 일관된 전체 순서로 획득된다. 네임스페이스 트리에서 수준별로 먼저 정렬되고 사전순(lexicographically)으로 동일한 수준 내에서 수집된다.
Replica Placement
일반적으로 수백 개의 청크서버가 여러 머신 랙에 분산되어 GFS 클러스터를 구성한다. 이러한 청크서버는 동일한 랙 또는 다른 랙에서 수백 개의 클라이어트에서 차례로 접근할 수 있다.

서로 다른 렉에 존재하는 두 머신간의 교신은 하나 또는 그 이상의 스위치를 거쳐야 한다. 또한 렉을 들어오거나 나가는 대역폭은 하나의 랙 안에 있는 모든 시스템의 총 대역폭 보다 작을 수 있다. 다중 수분 분포(multi-level distribution)은 확장성(scalability), reliability(안전성) 및 가용성(availability)을 위해 데이터를 배포해야 하는 고유한 과제를 제시한다.
(1)데이터 안전성과 가용성을 극대화하고, (2)네트워크 대여폭을 최대화하는 두 가지 용도로 청크 복제본 배치 정책은 사용된다. 두 경우 모두 복제본을 여러 머신에 분산하여 저장하는 것만으로 충분하지 않다. 이 경우 디스크 또는 머신의 결함에 대해서만 보호하고, 머신간의 네트워크 대역폭만을 활용한다.
결국 위 정책을 효과적으로 달성하려면 청크의 복제본들을 랙 수준에서 분산시켜야 한다. 이 경우 하나의 렉에서 손상되거나 오프라인 상태인 경우에도 청크의 일부 복제본이 다른 랙에서 다른 복제본이 유지되고 사용 가능한 상태로 유지되기 때문이다.
또한 청크에 대한 트래픽(특히 읽기)이 여러 랙의 집계 대역폭(aggregate bandwidth)를 이용할 수 있음을 의미한다. (쓰기 트래픽은 여러 랙을 통과해야하지만 기꺼이 수행하는 trade-off이다.)
Creation, Re-replication, Rebalancing
Creation
청크 복제본은 청크 생성, 재복제, rebalancing과 같은 세 가지 이유로 만들어진다.
마스터가 청크를 생성할 때 어디에 초기 복제본을 배치할 지 결정한다. 이것은 다음과 같은 요소들을 통해 결정한다.
(1) 평균 디스크 공간 사용률이 낮은 청크서버에 새 복제본을 배치한다. 시간이 지나면 청크서버의 디스크 활용률은 비슷해진다.
(2) 각 청크 서버에 "최근" 생성 복제본 수를 제한한다. 작성 자체는 비용이 저렴하지만 쓰기에서 요구될 때 청크가 생성되고, 추가 작업량에서 청크는 일반적으로 완전히 작성되면 읽기 전용이 되기에 쓰기 트래픽이 임박한 것을 안정적으로 예측한다.
(3) 앞서 설명했듯 청크 복제본을 렉 수준에서 분산한다.
Re-replication
청크서버를 사용할 수 없게 되거나, 복제본이 손상되었거나, 에러로 인해 디스크 중 하나가 비활성되거나, 복제 목표가 증가되는 등의 다양한 이유로 사용 가능한 복제본 수가 사용자가 지정한 목표 아래로 떨어지면 마스터는 청크를 다시 복제한다.
다시 복제해야하는 청크는 몇 가지 요소에 따라 우선 순위가 지정된다. 먼저 복제본이 두 개 손실된 청크는 하나만 손실된 청크보다 더 높은 우선 순위를 부여받는다. 두 번째는 최근 삭제된 파일에 속하는 청크 대신 살아있는 파일에 대한 청크를 먼저 다시 복제한다. 마지막으로, 클라이언트의 진행을 막는 청크에 대해 높은 우선순위를 부여한다. 실행 중인 애플리케이션에 미치는 장애의 영향을 최소화하기 위해서이다.
마스터는 우선 순위가 가장 높은 청크를 선택하고 일부 청크 서버에 기존 유효한 복제본에서 청크 데이터를 직접 복사하도록 지시하여 청크를 복제한다. 새 복제본은 디스크 공간 활용률을 균일화하고, 단일 청크서버에서 활성 클론 작업 제한, 여러 랙에 걸쳐 복제본을 분산하는 등의 목표를 가지고 배치된다.
Rebalance
마지막으로 마스터는 복제본을 주기적으로 rebalance한다. 마스터는 더 나은 디스크 공간 및 로드 밸런싱을 위해 현재 복제된 배포를 검사하고 복제본을 이동시킨다. 또한 이 과정을 통해 새로운 청크와 함께 오는 과도한 쓰기 트래픽으로 순식간에 수렁에 빠지기(swamp)보다 점차 새로운 청크서버를 채운다(새 복제본의 배치 기준은 위에서 언급).
마스터는 또한 삭제할 기존 보제본을 선택해야 한다. 일반적으로 사용 가능한 공간이 평균 미만인 청크서버에서 디스크 공간을 제거하여 디스크 공간 사용을 균등화한다.
Garbage Collection
파일이 삭제된 후 GFS에선 해당 파일 청크가 존재한 물리적 스토리지 공간을 바로 수거하지 않는다. 파일 및 청크 수준에 일반적인 가비지 컬렉션을 통해 느린(lazy) 방식으로 수행한다. 이렇게 하는 것이 시스템을 훨씬 단순하고 신뢰할 수 있게 한다는 것을 관찰하였다.
Mechanism
애플리케이션에서 파일을 삭제하면 마스터는 다른 변경 상황과 마찬가지로 삭제 내용을 즉시 로깅한다. 그러나 리소스(physical storage)를 즉시 회수하는 대신 파일 이름이 삭제 타임스탬프(삭제 시간)이 포함된 숨겨진 이름(hidden name)으로 변경된다.
마스터가 파일 시스템 네임스페이스에 대한 정기적인 스캔을 하는 중에 3일 이상 존재하는 숨겨진 파일(hidden file)이 있다면 제거한다.
마스터에 의해 제거되기 전까지 해당 파일은 특수 이름으로 계속 읽을 수 있으며 이름을 정상적으로 변경하여 삭제를 취소할 수 있다.
숨겨진 파일이 네임스페이스에서 제거되면 인메모리 메타데이터 역시 지워진다. 이는 모든 청크로 연결되는 링크를 효과적으로 차단한다. 청크 네임스페이스에 대한 유사한 정기 스캔에서 마스터는 고립된 청크(orphande chunk, 즉 파일에서 연결할 수 없는 청크)를 식별하고 해당 청크의 메타데이터를 지운다.
마스터와 정지적으로 교환되는 허트비트 메시지에서 각 청크서버는 청크의 하위 집합을 보고하고, 마스터는 더이상 메타데이터가 없는 청크를 알려주면, 청크서버가 이 청크 복제본을 지우게 된다.
Discussion
분산 가비지 컬렉션은 프로그래밍 언어의 맥락에서 복잡한 솔루션을 요구하는 어려운 문제이지만, GFS는 이를 간단히 구현하였다. GFS에서 청크에 대한 모든 참조를 쉽게 식별할 수 있다. 청크는 마스터가 독점적으로 관리하는 파일-청크 매핑에 있다. 또한 모든 청크 복제본을 쉽게 식별할 수 있다. 청크 복제본은 각 청크서버의 지정된 디렉터리에 있는 리눅스 파일이다. 마스터에 알려지지 않은 복제본을 "Garbage"라 한다.
스토리지 회수에 다한 가비지 컬렉션 방식(lazy deletion)은 즉각적인 삭제(eager deletion)와 대비되는 몇 가지 차이점을 제공한다.
먼저 부품 고장이 흔한 대규모 분산 시스템에서 간단하고 안정적이다. 청크 생성은 일부 청크서버에서 성공하지만 다른 청크서버에서는 성공하지 못할 수 있고, 마스터가 모르는 복제본이 남아있을 수 있다. 복제본 삭제 메시지가 손실될 수 있으며 마스터는 오류 발생 시 재발송해야 한다.
둘 째, 가비지 컬렉션은 일관되고 신뢰할 수 있는 방법으로 유용하지 않은 복제본(not known to be useful)을 수거한다.
스토리지 회수를 마스터의 네임스페이스 스캔 또는 청크서버
handshacke와 같은 정기적인 백그라운드 작업에 병합한다. 따라서 일괄적으로 처리되며 비용은 감소하게 된다. 더욱이 마스터가 비교적 한가할 때만 가능한 작업이다. 마스터는 시기적절한 주의가 필요한 클라이언트 요청에 보다 신속하게 응답할 수 있다.
셋 째, 스토리지 회수 지연은 실수로 되돌릴 수 없는 삭제에 대비한 일종의 안전망을 제공한다.
Stale Replica Detection
청크서버에 다운되어 청크에 대한 변화가 누락되거나 청크 서버에 장애가 발생하면 청크 복제본은 'stale' 상태가 될 수 있다. 각 청크에 대해 마스터는 청크 버전 번호를 유지하여 최신 복제본과 stale 복제본을 구분한다.
마스터는 새 리스를 청크에 부여할 때마다 청크 버전 번호를 증가시키고 최신 복제본에 알린다. 마스터와 최신의 복제본은 이러한 새 버전의 번호를 영구 상태로 기록한다.
이것은 클라이언트가 청크에 쓰기를 시작하기 전에 발생한다. 다른 복제본을 현재 사용할 수 없는 경우 해당 청크 버전 번호는 새 번호로 갱신되지 않는다. 마스터는 청크서버가 재시작될 때 이 청크서버에 stale 복제본이 있음을 감지하고 청크 집합과 관련 버전 번호를 알린다. 마스터가 레코드의 버전 번호보다 큰 버전을 발견하면 마스터는 리스를 부여할 때 실패했다 가정하므로 상위 버전이 최신 버전으로 바뀐다.
마스터는 가비지 컬렉션에서 stale 복제본을 제거한다. 그 이전에는 청크 정보에 대한 클라이언트 요청에 응답할 때 오래된 복제본이 전혀 존재하지 않는 것으로 간주한다. 마스터는 청크의 리스를 보유하고 있는 청크서버에 알리거나 복제 잡업에서 청크서버에 다른 청크서버의 청크를 읽도록 지시할 때 청크 버전 번호를 포함한다.
클라이언트 또는 청크서버는 작업을 수행할 때 버전 번호를 확인하여 항상 최신 데이터에 접근하도록 한다.
