해시법은 검색과 더불어 데이터의 추가와 삭제도 효율적으로 할 수 있는 방법.
검색(인덱싱)이 빠른 자료구조는 연속형 자료구조이고, 연결형 자료구조에 비해 삽입(추가)와 삭제가 느리다.
ex) c++ STL vector 자료구조
- 인덱싱: O(1)
- 삽입 및 삭제: O(n)
삽입 및 삭제가 빠른 자료구조는 연결형 자료구조이고, 연속형 자료구조에 비해 검색이 느리다(인덱싱 불가).
ex) 노드들이 연결된 링크드 리스트, 노드는 value 필드와 다음 노드를 가리키는 포인터 필드를 가짐.
=> Trade-off 관계
1. 해시법(hashing)
해시법은 데이터를 저장할 위치(인덱스)를 간단한 연산으로 구하는 것. 검색 뿐만 아니라 추가, 삭제도 효율적으로 수행할 수 있다. 예를 들어 배열의 각 요소 값으로 키 값이 있을 때 각 요솟수를 특정 수로 나눈 나머지를 해시 값(hash value)라고 할 수 있다. 이 해시 값은 데이터에 접근할 때 사용한다.

해시 값이 인덱스가 되도록 원래의 키 값을 저장한 배열이 아래의 해시 테이블(hash table)이다.

이 해시 테이블에 35를 추가하는 경우, 35를 13으로 나눈 나머지는 9이므로 해시 테이블의 9번째 위치에 값(35)를 저장한다.

이렇게 키 값(35)을 가지고 해시 값(9)를 만드는 과정을 해시 함수(hash function)라고 한다. 보통은 앞서 보였듯 나머지 연산 또는 이런 나머지 연산을 다시 응용한 연산을 사용. 그리고 해시 테이블의 각 요소를 버킷(bucket)이라고 한다.
2. 충돌(Collision)
위 해시 테이블 배열에 새로운 값 18을 추가하는 경우 고려해보면, 18을 13으로 나눈 나머지인 해시 값은 5이고 인덱스가 5인 버킷에 키 값을 저장해야 한다. 하지만 위 그림과 같이 이 버킷은 이미 채워져 있다. 이렇듯 키 값과 해시 값의 대응 관계가 반드시 1 대 1이라는 보증은 없으며, 이렇게 저장할 버킷이 중복되는 현상을 충돌(collision)이라 한다.
결국 해시 함수는 가능하면 해시 값이 치우치지 않도록(충돌이 발생되지 않도록) 고르게 분포된 값을 만들어야 한다.
- 충돌에 대한 대처에는 크게 다음과 같은 방법들이 있다.
(본 글에선 '체인법'만 언급한다.)
- 체인법(Chaining): 같은 해시 값을 갖는 요소를 연결 리스트로 관리. (= 오픈 해시법(open hasing))
- 오픈 주소법(Open addressing): 빈 버킷을 찾을 때까지 해시를 반복.
3. 체인법
체인법은 같은 해시 값을 갖는 데이터를 체인 모양으로 연결 리스트에서 연결하는 방법으로 오픈 해시법(open hashing)이라고도 한다.
배열(해시 테이블)의 각 버킷에 저장하는 값은 그 인덱스를 해시 값으로 하는 연결 리스트의 첫 번째 노드(node)에 대한 참조이다. 반면 데이터가 없는 버킷은 널(null)을 가리킨다.
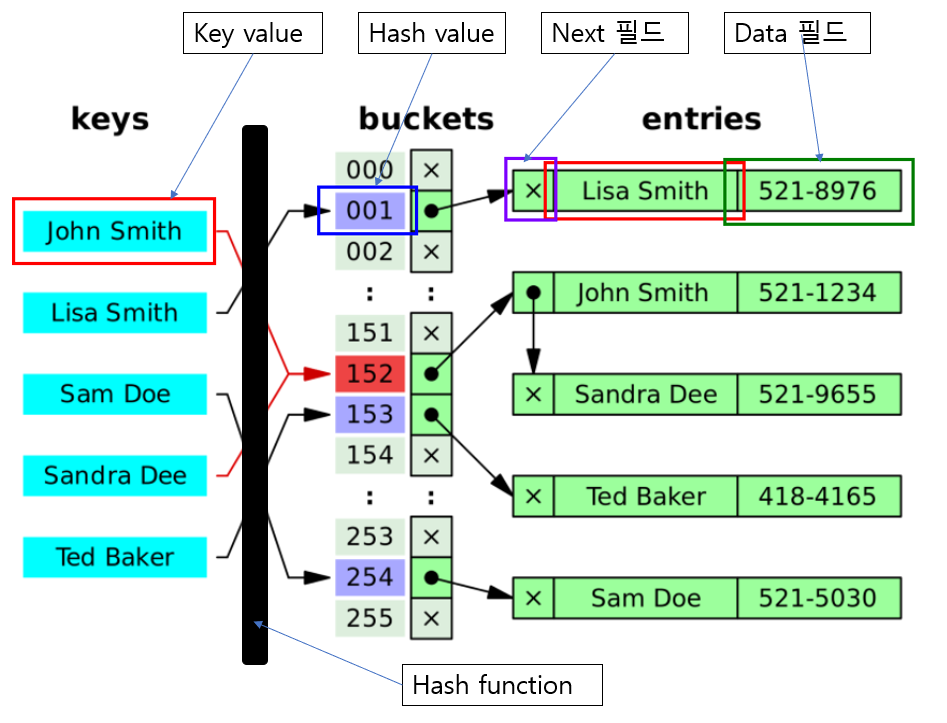
- 버킷용 클래스 Node<K, V>
개별 버킷을 나타내는 것이 클래스 Node<K, V>이다. 이 클래스에는 아래 세 가지 필드와 세 가지 메서드가 있다.- 세 가지 필드
- key: 키 값(자료형 K는 임의의 자료형)
- data: 데이터(자료형 V는 임의의 자료형)
- next: 체인의 다음 노드에 대한 참조
- 세 가지 메서드
- getKey: 키 값(key)을 그대로 반환
- getValue: 데이터(data)를 그대로 반환
- hashCode: 키 값의 해시 값을 반환
- 세 가지 필드
cf) Java의 Hash Code란, 객체를 식별할 수 있는 유니크한 값을 말한다. 메모리에 생성된 객체의 주소를 정수로 변환한 형태를 얘기하는데, 이 정수는 중복되지 않는 고유의 값이다. Object Class에서 hashCode()를 가지고 있어서 객체를 생성하여 확인해보면 Hash Code 값을 확인 할 수 있다. 실질적으로 Java에서 정의된 hashCode() 메소드는 아래와 같이 설명된다.
1. 변경되지 않은 한 객체의 hashCode() 메소드 호출결과는 항상 같은 integer 값이어야 한다. 2. equals 메소드가 같다고 판별한 두 객체의 hashCode() 호출 결과는 똑같은 integer 값이어야 한다. 3. 그러나 java.lang.Object.equals 메소드가 다르다고 두 객체의 hashCode() 값이 반드시 달라야 하는 것은 아니다. (참조: https://dbjh.tistory.com/36)
체인법 JAVA 예제 코드
- 체인법으로 구현한 클래스 ChainHash<K, V>의 Node 클래스
public class ChainHash<K, V> {
// 해시를 구성하는 노드
class Node<K, V>{
private K key; // 키 값
private V data; // 데이터
private Node<K, V> next; // 다음 노드에 대한 참조
// 생성자
Node(K key, V data, Node<K, V> next){
this.key = key;
this.data = data;
this.next = next;
}
// 키 값 반환
K getKey(){
return key;
}
// 데이터 반환
V getValue(){
return data;
}
// 키의 해시 코드 반환
public int hashCode(){
return key.hashCode();
}
}
...
} 자기 참조형 클래스(next 필드의 자료형이 같은 Node 클래스)인 Node<K, V>에서 필드 next에 대입되는 값은 체인에 있는 다음 노드에 대한 참조이다. 하지만 다음 노드가 없을 경우에는 데이터가 없는 버킷과 마찬가지로 널이 대입된다.
hashChain 클래스
- 해시 클래스 ChainHash<K, V> 필드
- size: 해시 테이블의 크기 (table(배열)의 요소 수)
- table: 해시 테이블을 저장하는 배열
- 해시 테이블: "해시 값이 인덱스가 되도록 원래의 키 값을 저장한 배열"
- 해시 클래스의 생성자
- 클래스 ChainHash<K, V>의 생성자는 비어 있는 해시 테이블을 생성하며, 매개변수 capacity에 전달받는 것은 해시 테이블의 용량. 요소 수가 capacity인 배열 table의 본체를 생성하고 capacity 값을 필드 size에 복사.
- 해시 테이블의 각 버킷은 맨 앞부터
table[0]..table[size-1]로 접근. 생성자가 호출된 직후 배열 table의 모든 요소는 널(null)을 참조하며, 모든 버킷이 비어 있는 상태가 됨.
- 메서드
- hashValue 메서드: 해시 값을 구하는 메서드. key의 해시 값(hashCode)을 해시 테이블의 크기 size로 나눈 나머지를 반환
- search 메서드: 키 값이 key인 요소를 검색하는 메서드.
- add 메서드: 키 값이 key이고 데이터가 data인 요소를 삽입하는 메서드
- remove 메서드: 키 값이 key인 요소를 삭제하는 메서드
- dump 메서드: 해시 테이블의 내용을 통째로 출력하는 메서드
public class ChainHash<K, V> {
// 해시를 구성하는 노드
class Node<K, V>{
private K key; // 키 값
private V data; // 데이터
private Node<K, V> next; // 배열의 각 요소는 버켓, 다음 노드에 대한 참조
// 생성자
Node(K key, V data, Node<K, V> next){
this.key = key;
this.data = data;
this.next = next;
}
// 키 값 반환
K getKey(){
return key;
}
// 데이터 반환
V getValue(){
return data;
}
// 키의 해시 값 반환 (key -> hash value, hash value가 hash table의 index로)
public int hashCode(){
return key.hashCode();
}
}
// 필드
private int size; // hash table size
private Node<K, V>[] table; // hash table
// 생성자
public ChainHash(int capacity){
try{
table = new Node[capacity];
this.size = capacity;
}catch(OutOfMemoryError e){
this.size = 0;
}
}
// 해시 값(hash value) 구하기
public int hashValue(Object key){
return key.hashCode() % size;
// key의 고유 해시코드를 테이블 크기로 나누어 해시 값을 생성.
}
/* ADD
1. 해시 함수가 키 값을 해시 값으로 변환
2. 해시 값을 인덱스로 하는 버킷을 선택
3. 버킷이 가리키는 연결 리스트를 처음부터 순서대로 검색합니다. 키 값과 같은 값을 찾으면 키 값이 이미 등록된 상태이므로 추가 실패.
끝까지 스캔하여 찾지 못하면 리스트의 맨 앞 위치에 노드를 삽입.
=> 시간 복잡도: O(k) (k: 해당 해쉬 값을 갖는 키 들의 갯수)
*/
// 키 값: key, 데이터: data를 갖는 요소 추가.
public int add(K key, V data){
int hash = hashValue(key); // 해당 키의 해시값 구하기
Node<K, V> p = table[hash]; // 노드 선택
while(p != null){
if(p.getKey().equals(key)) // 해당 키 값이 이미 등록되어있다면,
return 1;
else
p = p.next;
}
Node<K, V> temp = new Node<K, V>(key, data, table[hash]); // 기존에 테이블 요소에서 삽입된 참조를 자신 노드가 참조.
table[hash] = temp; // 새로 만든 노드를 버킷(table[hase])이 참조.
return 0;
}
/* SEARCH
1. 해시 함수가 키 값을 해시 값으로 변환.
2. 해시 값을 인덱스로 하는 버킷을 선택.
3. 선택한 버킷(노드)의 연결 리스트를 처음부터 순서대로 검색. 키 값과 같은 값을 찾으면 검색 성공. 끝까지 스캔한 결과 찾지 못해면 실패.
=> 시간 복잡도: O(k) (k: 해당 해쉬 값을 갖는 키 들의 갯수)
*/
// 키 값 key를 갖는 요소 검색(데이터를 반환)
public V search(K key){
int hash = hashValue(key); // 검색한 데이터의 해시 값
Node<K, V> p = table[hash]; // 노드 선택
while(p != null){
if(p.getKey().equals(key))
return p.getValue();
else
p = p.next;
}
// 루프를 끝까지 돌면 자연스럽게 검색내용이 없다는 뜻.
return null;
}
/* REMOVE
1. 해시 함수가 키 값을 해시 값으로 변환
2. 해시 값을 인덱스로 하는 버킷 선택
3. 버킷이 가리키는 연결 리스트를 처음부터 순서대로 검색. 발견 시 삭제, 발견을 못하면 삭제 실패.
=> 시간 복잡도: O(k) (k: 해당 해쉬 값을 갖는 키 들의 갯수)
*/
public int remove(K key){
int hash = hashValue(key);
Node<K, V> p = table[hash];
Node<K, V> pp = null;
while(p != null){
if(p.getKey().equals(key)){
if(pp==null)
table[hash] = p.next;
else
pp.next = p.next;
return 0;
}
pp = p;
p = p.next;
}
return 1; // 해당 키 값 없음 -> 삭제 실패.
}
/* DUMP
해시 테이블의 모든 내용을 출력하는 dump 메서드
*/
public void dump(){
for(int i=0; i<size; i++){
Node<K, V> p = table[i];
System.out.printf("%02d ", i); // i번째 버킷
while(p != null){
System.out.printf("-> key: %s, value: %s", p.getKey(), p.getValue());
p = p.next;
}
System.out.println();
}
}
}